Java基础(十六)——IO流(二)
按功能划分:
基础流(节点流):直接与磁盘交互。
包装流(处理流):建立在节点流的基础上,通过缓冲区进续写。
一、包装流
1、初识包装流
带 Buffer 的都是带缓冲区的。

包装流是没有无参的,必须传递对应的基础流。完整代码:

之前使用的 IO 流中,都是跟磁盘直接进行交互,这种交互方式效率比较低下。现在使用的是有缓冲区,从磁盘直接读取到内存中,再从内存中一次性读取出来:

看起来这种方式好像更麻烦了,但是这种方式实际效率更高。
2、包装流不关闭资源(close()和flush())
意思是:最后不调用 close()方法,结果会怎样?

结果是目标文件什么都没有,空白一片。

如果有 close()方法,则能正常写入字符。如果调用 flush()方法,也能正常写入。close()方法里面有调用到 flush()方法。
原因是:这里设置了缓冲区大小,只有当缓冲区满了,或者没满的时候,手动调用方法(关流,也就是 close 方法),把缓冲区的内容一次性加载到文件中去,这时候文件才会有内容。
3、带缓冲区的字节输入流
直接上代码:
@Test
public void method4() {
// 带缓冲区的字节输入流
BufferedInputStream bis = null;
try {
bis = new BufferedInputStream(new FileInputStream("test3.txt"));
byte[] b = new byte[1024];
int len;
while ((len = bis.read(b) )!= -1){
System.out.println(new String(b,0,len));
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
使用方式跟前面的使用差不多。
4、带缓冲区的字符流
字节流有缓冲区,同理,字符流也会有自己的缓冲区。

可以发现,还是跟前面的使用方式差不多。不过这里就不再用这种方法了,用 readline()和 newline(),先来看看这两个的用法和意思:
readLine():(一行一行的读取)

newLine():

这句话的意思是,换行符由系统来定义,因为每个操作系统的换行符不同,windows是 “\n” ,但 Linux可能就是其他的,mac也不可能是这种了。
所以最终代码为:
public void method2() throws IOException {
BufferedReader br = new BufferedReader(new FileReader("test3.txt"));
BufferedWriter bw = new BufferedWriter(new FileWriter("test5.txt"));
String str;
while ((str = br.readLine()) != null){
bw.write(str);
bw.newLine();
}
bw.close();
br.close();
}
BufferedReader —— readLine()
BufferedWriter —— newLine()
这两个是它们独有的方法,其他 IO 流没有这两个方法。
二、对象流
1、初识对象流
如果现在有个对象,要通过字节字符流写出来很简单,但是如果要通过字节字符流读取这个内容生成对象,就相当麻烦了,一个个字符串截取:
所以有个对象流,专门针对对象的读写。

2、未序列化异常
写一个对象类,接着运行上面代码,会发现报错:

翻译一下是说还没有序列化。所以对象类需要实现一个接口——Serializable,实现接口需要重写方法,但是这个接口比较特殊,不用重写方法即可。
所以最终代码为:
@Test
// 使用对象流进行对象的读写操作,对象类必须实现 Serializable 接口
public void method1() throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("test6.txt"));
User user = new User(1,"zs",11);
User user2 = new User(2,"zs",121);
oos.writeObject(user);
oos.writeObject(user2);
oos.close();
}
使用对象流进行对象的读写操作,对象类必须实现 Serializable 接口。
本质上读写操作是序列化和反序列化,
写入对象到文件中为序列化,
读取文件的对象为反序列化。
3、通过对象流读取多个对象信息
读取多个对象时会遇到一些麻烦,比如不知道读取几个,读取完了继续读取会报错。经过多次调整,最终决定采用集合来存储对象,然后对象流存储一个集合这个方案。
存储(通过集合存储多个对象信息):
@Test
public void method2() throws IOException {
// 通过集合存储多个对象信息
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("test7.txt"));
ArrayList<User> list = new ArrayList<>();
list.add(new User(1,"zs",11));
list.add(new User(2,"ls",12));
list.add(new User(3,"ww",13));
list.add(new User(4,"z6",14));
list.add(new User(5,"t7",11));
oos.writeObject(list);
oos.close();
}
读取(通过对象流读取文件多个对象信息 – 读取集合):
@Test
public void method2() throws IOException, ClassNotFoundException {
//通过对象流读取文件多个对象信息 -- 读取集合
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("test7.txt"));
List<User> list = (List<User>)ois.readObject(); // 强转
for ( User user:list) {
System.out.println(user);
}
ois.close();
}
如果有后续内容需要添加,则先把原本的读出来,到新的集合中,再把要加的写入到新的集合中去,再把这个新的集合写到文件中去。 保证文件里面只有一个集合对象,读的时候就永远不会出问题。
4、序列化
a、序列化和序列号
前面在对象那里需要实现一个接口,进行序列化,这个序列化,就是在写入的时候序列化出来的一个序列号;这个序列号是反序列化的唯一标识。如果反序列化的时候查找的序列号不一致就会出问题
简单的说就是,写入的时候进行了序列化,然后改变了类的结构;接着反序列化的时候这个当做模板的类,因为其结构改变,所以序列号也进行改变了,序列号不一致,就读取不了文件。
 当序列号不一致的情况就会出现这种错误。可以看到该数字十分大,所以其类型是 long 类型。
当序列号不一致的情况就会出现这种错误。可以看到该数字十分大,所以其类型是 long 类型。
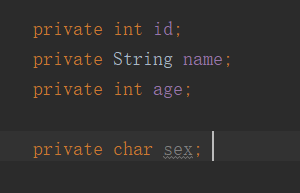
前三个是原本有的属性。后面一个是新加的,加了这个属性后,类结构改变,序列号不一致就报错了。可以发现,这两个序列号中,一个是三个属性的序列号,另外一个是四个属性的序列号。也可以因此得知,静态变量会被序列化。
那么哪些修饰符修饰的属性不会被序列化呢?
经过多次测试得知:私有的静态属性不会被序列化(其特点是,所有对象共用一份,这种就不会被序列化)
5、transient——修饰的变量不会被序列化
这个关键词修饰的变量,不会被序列化。
6、 转换流
a、引入转换流
对象流因为结尾有个 Stream,可以猜测其为字节流。实际其实质也是字节流
所以对象流只能传递字节流。
有一种流,可以实现字节与字符之间的转换,叫转换流。这样一来,对象流也没有了限制。
b、转换流
转换流:字节通向字符的桥梁,本质上是字符流。
InputStreamReader———文件中的字节转换成程序中的字符
OutputStreamWriter———程序中的字符转换成文件中的字节
c、输出转换流
使用方式:

d、输入转换流
如图:

e、转换不同编码格式
转换流除了能转换字节字符,还能转换不同编码格式。
txt 文件可以选择其他编码格式,这时候用程序读取会出现乱码,可以通过转换 utf-8 来完成转码,让程序能够正常显示。
编码不相同时就会出现这种乱码:
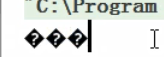
转换编码:

这样,就能够正常显示输出内容。