下图是本文所讲述的整个Java集合框架基本内容,共分为俩大部分,Collection接口和Map接口
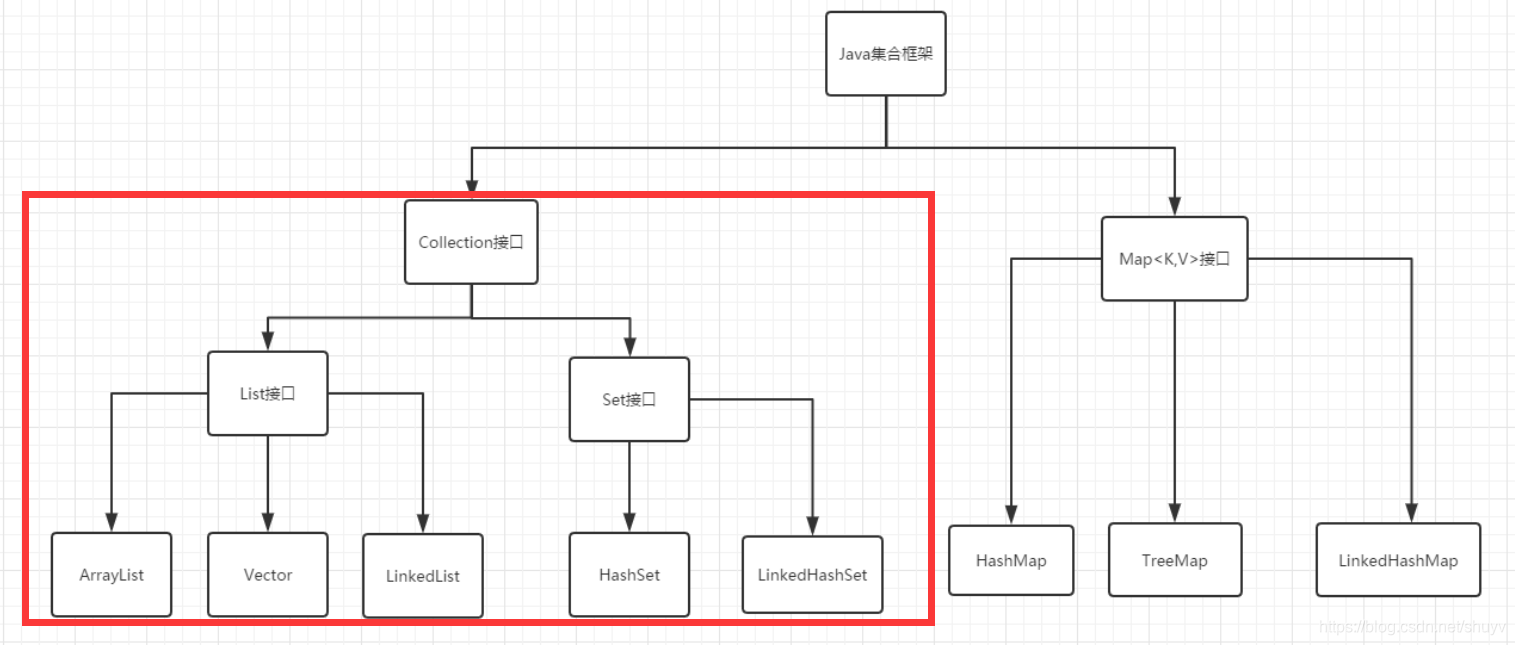
Collection集合框架体系
集合
概念
对象的容器,实现了对对象常用的操作,类似数组功能。
集合和数组的区别
- 1.数组的长度是固定的,集合长度不固定
- 2.数组可以储存基本类型和引用类型,集合只能储存引用类型
- 3.数组的长度是固定的,一旦数据量超出容量,则不可继续储存数据,但是对于集合来说,当数据量超过容量的时候,集合会自动扩容,舒服了~~~
一、List集合(interface)
List实现了Collection接口,它具有俩个常用的实现类:ArrayList类和LinkedList类。
](https://img-blog.csdnimg.cn/20210110230440988.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3NodXl2,size_16,color_FFFFFF,t_70)
1.ArrayList实现类(class)
ArrayList实现类除了包含Collection接口中的所有方法之外,还包括List接口中提供的一些常用方法。
如下表:
| 方法名称 | 说明 |
|---|---|
| E get(int index) | 获取此集合中指定索引位置的元素,E 为集合中元素的数据类型 |
| int index(Object o) | 返回此集合中第一次出现指定元素的索引,如果此集合不包含该元素,则返回 -1 |
| int lastIndexOf(Object o) | 返回此集合中最后一次出现指定元素的索引,如果此集合不包含该元素,则返回 -1 |
| E set(int index, Eelement) | 将此集合中指定索引位置的元素修改为 element 参数指定的对象。此方法返回此集合中指定索引位置的原元素 |
| List subList(int fromlndex, int tolndex) | 返回一个新的集合,新集合中包含起始索引到末尾索引之间的所有元素,包前不包后 |
常用操作:增删改查
public class Demo02 {
public static void main(String[] args) {
List<String> aList = new ArrayList<String>();
aList.add("shuyv2019");
aList.add("shuyv2020");
aList.add("shuyv2021");
System.out.println(aList);
List<Integer> bList = new ArrayList<Integer>();
bList.add(2019);
bList.add(2020);
bList.add(2021);
System.out.println(bList);
//删除集合中指定下标处的数据
aList.remove(1);
//aList.remove("shuyv2019");
aList.forEach(temp->{
System.out.println(temp);
});
//根据内容删除
Object o = 2020;
bList.remove(o);
for (Integer temp : bList) {
System.out.println(temp);
}
//清空集合中的所有元素
//aList.clear();
//bList.clear();
//修改集合中的元素
aList.set(0,"凌2019");
aList.forEach(temp->{
System.out.println(temp);
});
}
}
注意上述代码中的删除操作,remove删除有俩种方式,一种是根据索引进行删除(int),另一种是直接根据内容删除(Object)。
2.LinkedList实现类(class)
由上述图片所描述的Collection集合框架体系可知,Link集合接口继承了Collection接口,所以说LinkedList实现类包含Collection接口和List接口的所有方法,除此之外,LinkedList实现类当中还包含一些特别的方法。
如下表:
| 方法名称 | 说明 |
|---|---|
| void addFirst(E e) | 将指定元素添加到此集合的开头 |
| void addLast(E e) | 将指定元素添加到此集合的末尾 |
| E getFirst() | 返回此集合的第一个元素 |
| E getLast() | 返回此集合的最后一个元素 |
| E removeFirst() | 删除此集合中的第一个元素 |
| E removeLast() | 删除此集合中的最后一个元素 |
代码演示:
public class Demo01 {
public static void main(String[] args) {
// 创建集合对象
LinkedList<String> products = new LinkedList<String>();
String str1 = new String("shuyv2019");
String str2 = new String("shuyv2020");
String str3 = new String("shuyv2021");
String str4 = new String("shuyv2022");
products.add(str1);
products.add(str2);
products.add(str3);
products.add(str4);
System.out.println(products);
//在集合末尾添加元素
String str5 = new String("shuyv2023");
products.addFirst(str5);
System.out.println(products);
//返回集合的第一个元素
String the_first = products.getFirst();
System.out.println(the_first);
}
}
3.二者区别(底层理解)
ArrayList类和LinkedList类都是List集合接口的实现类,因此都实现了List的所有未实现方法,只是实现方式不同。
此二者最大的区别,则是底层储存数据的方式不同,ArrayList是基于顺序表数据结构而实现,访问速度快。LinkedList是基于链表数据结构而实现,占用内存较大,适合批量插入或者删除数据。
二、Set集合(interface)
- Set集合当中的对象不按照特定的方式排序。
- Set集合中不能包含重复的对象,并且最多只允许包含一个null元素。
- Set集合实现了Collection接口,它主要有俩个常用的实现类:HashSet和TreeSet
1.HashSet实现类(class)
顾名思义,HashSet集合底层是按照Hash算法来储存集合中的元素。因此具有良好的存取和查找性能。
HashSet具有以下特点:
- 1.不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
- 2.HashSet不是同步的,如果多个线程同时访问或者修改一个HashSet,则必须通过代码来保证q其同步。
- 3.集合元素值可以是null。
- 4.具有很好的存取和查找性能。
代码演示:
public class Demo01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
String str1 = new String("shuyv2019");
String str2 = new String("shuyv2020");
String str3 = new String("shuyv2021");
String str4 = new String("shuyv2022");
String str5 = new String("shuyv2022");
hashSet.add(str1);
hashSet.add(str2);
hashSet.add(str3);
hashSet.add(str4);
hashSet.add(str5);
System.out.println("2019-2022年的shuyv:" + hashSet);
Iterator<String> it = hashSet.iterator();
while (it.hasNext()) {
System.out.println((String) it.next());
}
System.out.println(hashSet.size());
}
}
执行结果如下:
2019-2022年的shuyv:[shuyv2019, shuyv2020, shuyv2022, shuyv2021]
shuyv2019
shuyv2020
shuyv2022
shuyv2021
4
通过上述代码可知,如果向Set集合中添加俩个相同的元素,则后添加的元素会覆盖前面添加的元素,即在Set集合中不会出现相同的元素。
HashSet的底层理解:
当我们向HashSet存入一个元素的时候,HashSet会调用该对象的hashCode()方法来获取该对象的hashCode值(十六进制哈希值,也就是内存地址值),然后根据该hashCode值决定该对象在HashSet中的存储位置。所以要特别注意一点,虽然HashSet中不能出现重复的元素,但是也有特殊情况,比如当使用equals()方法来比较俩个元素时,如果返回值为true,但是这俩个元素的hashCode不相等,HashSet会把这俩个元素放在不同的位置,依然可以添加成功。
2.TreeSet实现类(class)
TreeSet类同时实现了Set接口和SortedSet接口。SortedSet接口是Set接口的子接口,可以实现对集合进行字然排序,因此使用TreeSet类实现的Set接口默认情况下是自然排序的,这里的自然排序是指升序。
这里的自然排序也有局限性,因为*TreeSet只能对实现了Comparable接口的类对象进行排序*。
Comparable接口请查询Java API文档进行了解
Java API文档
TreeSet实现类除了实现Collection接口所有的方法之外,还提供了一些常用方法。
如下表:
| 方法名称 | 说明 |
|---|---|
| E first() | 返回此集合中的第一个元素。其中,E 表示集合中元素的数据类型 |
| E last() | 返回此集合中的最后一个元素 |
| E poolFirst() | 获取并移除此集合中的第一个元素 |
| E poolLast() | 获取并移除此集合中的最后一个元素 |
| SortedSet subSet(E fromElement,E toElement) | 返回一个新的集合,新集合包含原集合中 fromElement 对象与 toElement。。对象之间的所有对象。包含 fromElement 对象,不包含 toElement 对象 |
| SortedSet headSet<E toElement〉 | 返回一个新的集合,新集合包含原集合中 toElement 对象之前的所有对象。不包含 toElement 对象 |
| SortedSet tailSet(E fromElement) | 返回一个新的集合,新集合包含原集合中 fromElement 对象之后的所有对象。包含 fromElement 对象 |
注意:方法看上去多一些,但其实只是一些简单的集合元素获取,还有截取,注意索引范围。
代码举例:
public class Demo02 {
public static void main(String[] args) {
TreeSet<Double> treeSet = new TreeSet<Double>();
Double num1 = 2020.0;
Double num2 = 2019.0;
Double num3 = 2021.0;
Double num4 = 2022.0;
Double num5 = 2022.0;
treeSet.add(num1);
treeSet.add(num2);
treeSet.add(num3);
treeSet.add(num4);
treeSet.add(num5);
System.out.println("treeSet中的元素:" + treeSet);
//返回集合中的第一个元素和最后一个元素
System.out.println(treeSet.first());
System.out.println(treeSet.last());
//集合截取
Object newSet = treeSet.subSet(2020.0,2022.0);
System.out.println(newSet);
Iterator<Double> it = treeSet.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
三、遍历
1.传统for循环
传统的for循环,就是最普通最简单的形式,如下代码举例:
for (int i = 0; i < aList.size(); i++) {
System.out.println(aList.get(i));
}
2.高级for循环
语法格式:
for(数据类型 变量名 : 集合/数组) {
代码块
};
注意:在高级for循环中定义的变量,每次循环都会被集合中的元素赋值,也就是说,该变量接受的是集合中的每个元素。
代码演示:
for (Object temp : aList) {
System.out.println(temp);
}
3.lambda表达式
匿名函数,是在高级for循环的基础上,再次简化语法。
语法格式如下:
集合.forEach(临时变量->{
代码块
});
代码演示:
aList.forEach(temp->{
System.out.println(temp);
});
注意:
- 1.在使用lambda表达式的时候,不需要指定数据类型,它会自动识别。
- 2.lambda表达式只针对集合,不可以遍历数组。
4.迭代器
Iterator(迭代器)是一个接口,它的作用就是遍历容器内的所有元素,迭代器不同于Collection和Map系列的集合,Collection和Map系列集合主要是用于盛装其他对象,而Iterator则主要用于遍历访问Collection中的元素。
Iterator接口中定义的方法:
| 方法名 | 作用 |
|---|---|
| boolean hasNext() | 如果被迭代的集合没有被遍历完,则返回true |
| Object next() | 返回集合里的下一个元素 |
| void remove() | 删除集合里上一次next方法返回的元素 |
| void forEachRemaining(Consumer action) | 这是Java8当中新增的默认方法,该方法可使用Lambda表达式来遍历集合元素 |
代码演示:
public class IteratorTest {
public static void main(String[] args) {
// 创建一个集合,多态语法(基于继承)
Collection the_Set = new HashSet();
the_Set.add("shuyv2019");
the_Set.add("shuyv2020");
the_Set.add("shuyv2020");
the_Set.add("shuyv2021");
the_Set.add("shuyv2022");
System.out.println(the_Set);
// 调用forEach()方法遍历集合,,注:lambda表达式
System.out.println("使用lambda表达式遍历结果如下:");
the_Set.forEach(temp->{
System.out.println(temp);
});
System.out.println("-----------------------------------");
System.out.println("使用迭代器遍历结果如下:");
// 迭代器遍历
Iterator it = the_Set.iterator(); // 获取迭代器对象it
while (it.hasNext()) {
// it.next()返回的数据类型是Object类型,因此需要强制类型转换
String obj = (String) it.next();
System.out.println(obj);
if (obj.equals("shuyv2020")) {
// 从集合中删除上一次next()方法返回的元素
it.remove();
}
}
System.out.println("------------------------迭代过程中删除了shuyv2020,集合结果如下:");
System.out.println(the_Set);
}
}
代码执行结果如下:
[shuyv2019, shuyv2020, shuyv2022, shuyv2021]
使用lambda表达式遍历结果如下:
shuyv2019
shuyv2020
shuyv2022
shuyv2021
-----------------------------------
使用迭代器遍历结果如下:
shuyv2019
shuyv2020
shuyv2022
shuyv2021
------------------------迭代过程中删除了shuyv2020,集合结果如下:
[shuyv2019, shuyv2022, shuyv2021]
注意事项:
Iterator(迭代器)必须依附于Collection对象,如若有一个Iterator对象,那么必然有一个Collection对象。
当使用Iterator(迭代器)访问Collection集合元素的时候,Collection集合里的元素不能改变,只有通过Iterator中的remove()方法删除上一次next()方法返回的集合元素才可以,否则会引发“java.util.ConcurrentModificationException”异常
5.lambda表达式遍历迭代器
根据3、4小节直接通过代码展示
public class Demo02 {
public static void main(String[] args) {
// 创建一个集合
Collection objs = new HashSet();
objs.add("shuyv2019");
objs.add("shuyv2020");
objs.add("shuyv2021");
// 获取objs集合对应的迭代器
Iterator it = objs.iterator();
// 使用lambda表达式遍历迭代器
it.forEachRemaining(temp->{
System.out.println("迭代集合元素:" + temp);
});
}
}
运行结果如下
迭代集合元素:shuyv2019
迭代集合元素:shuyv2020
迭代集合元素:shuyv2021
Map集合(interface)

Map是一种键值对(key-value)集合,Map集合中的每一个元素都包含一个键(key)对象和一个值(value)对象。Map集合用于保存具有映射关系的数据。
注意:
- 1.Map结合中的key和value都可以是任何引用数据类型。
- 2.Map中的key不允许重复,value可以重复。而且使用equals方法来比较key的时候返回值永远是false。
- 3.key和value一一对应,通过key来访问value。
Map结合接口主要有来个实现类:HashMap类和TreeMap类。
HashMap类底层由哈希算法来存取键对象,TreeMap类可以对键对象进行排序。
1.HashMap实现类
以下表格是一些常用方法
| 方法名称 | 方法作用 |
|---|---|
| void clear() | 删除该 Map 对象中的所有 key-value 对。 |
| boolean containsKey(Object key) | 查询 Map 中是否包含指定的 key,如果包含则返回 true。 |
| boolean containsValue(Object value) | 查询 Map 中是否包含一个或多个 value,如果包含则返回 true。 |
| V get(Object key) | 返回 Map 集合中指定键对象所对应的值。V 表示值的数据类型。通过键获取值 |
| V put(K key, V value) | 向 Map 集合中添加键-值对,如果当前 Map 中已有一个与该 key 相等的 key-value 对,则新的 key-value 对会覆盖原来的 key-value 对。 |
| void putAll(Map m) | 将指定 Map 中的 key-value 对复制到本 Map 中。 |
| V remove(Object key) | 从 Map 集合中删除 key 对应的键-值对,返回 key 对应的 value,如果该 key 不存在,则返回 null |
| boolean remove(Object key, Object value) | 这是 Java 8 新增的方法,删除指定 key、value 所对应的 key-value 对。如果从该 Map 中成功地删除该 key-value 对,该方法返回 true,否则返回 false。 |
| Set entrySet() | 返回 Map 集合中所有键-值对的 Set 集合,此 Set 集合中元素的数据类型为 Map.Entry |
| Set keySet() | 返回 Map 集合中所有键对象的 Set 集合 |
| boolean isEmpty() | 查询该 Map 是否为空(即不包含任何 key-value 对),如果为空则返回 true。 |
| int size() | 返回该 Map 里 key-value 对的个数 |
| Collection values() | 返回该 Map 里所有 value 组成的 Collection |
案例演示:
创建HashMap集合用来保存NBA球员信息,然后通过上述表格的常用方法对集合进行操作。
public class Demo01 {
public static void main(String[] args) {
HashMap players = new HashMap();
players.put("James","36");
players.put("Durant","30");
players.put("ZiMu","24");
players.put("HaDen","29");
players.put("Yao","40");
System.out.println("------------------------------NBA运动员-------------------------------");
System.out.println(players);
System.out.println("Keys: " + players.keySet());
System.out.println("values: " + players.values());
//通过key获取value
System.out.println("Yao's age is " + players.get("Yao") + " years old");
System.out.println("---------------------------------------------------------------------");
// 获取Map键集合的迭代器对象
Iterator it = players.keySet().iterator();
while (it.hasNext()) {
// 遍历
Object key = it.next();
Object value = players.get(key);
System.out.println(key + "今年" + value + "岁。");
}
Scanner scanner = new Scanner(System.in);
System.out.println("---------------------------------------------------------");
System.out.println("请输入要删除的球员");
String input = scanner.next();
if (players.containsKey(input)) {
// 判断输入的键是否被集合包含,如果在集合当中,则删除
players.remove(input);
} else {
System.out.println("NBA没有这个球员!");
}
System.out.println("删除后球员后的集合-----------------------------------------------------");
Iterator iterator = players.keySet().iterator();
while (iterator.hasNext()) {
// 遍历
Object key = iterator.next();
Object value = players.get(key);
System.out.println(key + "今年" + value + "岁。");
}
}
}
Scanner输入:Durant
执行结果如下
------------------------------NBA运动员-------------------------------
{
James=36, Yao=40, HaDen=29, Durant=30, ZiMu=24}
Keys: [James, Yao, HaDen, Durant, ZiMu]
values: [36, 40, 29, 30, 24]
Yao's age is 40 years old
---------------------------------------------------------------------
James今年36岁。
Yao今年40岁。
HaDen今年29岁。
Durant今年30岁。
ZiMu今年24岁。
---------------------------------------------------------
请输入要删除的球员
Durant
删除后球员后的集合-----------------------------------------------------
James今年36岁。
Yao今年40岁。
HaDen今年29岁。
ZiMu今年24岁。
2.TreeMap实现类
TreeMap使用的方法和HashMap相同,唯一的不同就是,TreeMap可以对键对象进行排序。
3.Map集合的遍历
Map集合的遍历和上文当中Collection中的遍历方式没有太大的区别。
(1)高级for循环,结合entries实现遍历(针对键值都需要的情况)
高级for循环结合entries实现遍历,这是最常见的方式,并且在大多数情况下也是最可取的遍历方式。在键值都需要的时候使用。
public class Demo02 {
public static void main(String[] args) {
Map<String,String> map = new HashMap<String, String>();
map.put("凌薇","2020");
map.put("shuyv","2019");
for (Map.Entry<String,String> entry : map.entrySet()) {
String mapKey = entry.getKey();
String mapValue = entry.getValue();
System.out.println(mapKey + ":" + mapValue);
}
}
}
执行结果如下:
凌薇:2020
shuyv:2019
(2)for-each循环(只针对Key或者Value)
使用for-each循环遍历key或者values,一般只适用于只需要key或者values时使用。性能上比entrySet较好。
注意:这边的for-each循环和lambda表达式forEach不一样。
public class Demo03 {
public static void main(String[] args) {
Map<String,String> map = new HashMap<String, String>();
map.put("凌薇","2020");
map.put("shuyv","2019");
// for循环打印输出结合中的key
for (String key : map.keySet()) {
System.out.println(key);
}
// 打印值集合
for (String value : map.values()) {
System.out.println(value);
}
}
}
执行结果如下:
凌薇
shuyv
2020
2019
(3)迭代器遍历 Iterator
public class Demo04 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("凌薇","2020");
map.put("shuyv","2019");
Iterator<Map.Entry<String,String>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<String,String> entry = entries.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + ":" + value);
}
}
}
执行结果如下:
凌薇:2020
shuyv:2019
(4)通过Key找Value遍历
通过键找值遍历,这种方式的效率比较低,因为本身从键去找值就是比较耗时的操作。
代码演示如下
for(String key : map.keySet()){
String value = map.get(key);
System.out.println(key+":"+value);
}
泛型(集合框架的规范)
简介
Java的集合有缺点,当把对象放进集合当中时,该集合不能够记录这个对象是什么类型的,所以设计者们把集合设计成能接受任何类型的对象,从而使集合更加灵活。但是,集合中的对象都被编译成了Object类型(当然在运行过程中该对象的类型没有改变)。
所以在使用集合的时候会出现下问题:
- 1.集合对元素类型没有任何限制,这样可能会引发一些问题,例如,当我们想创建一个保存Dog对象的集合,但程序也可以轻易的将Cat对象丢进去,所以引发异常。
- 2.由于把对象丢进集合当中时,集合丢失了对象的状态信息,就是说集合不知道该对象的数据类型,直接认为该对象是Object类型,因此取出集合元素通常还需要强制类型转换,这种强制类型转换既增加了编译的复杂程度,也容易引发ClassCastException异常。
所以为了解决该类问题,Java出现了泛型。泛型可以在编译的时候检查类型安全,并且所有的强制类型转换都是自动的和隐式的,提高了代码的重用率。