Unet论文:http://www.arxiv.org/pdf/1505.04597.pdf
Unet源代码:https://github.com/jakeret/tf_unet
发表于:2015 MICCAI
一、基本介绍
1.1历史背景
卷积神经网络(CNN)不仅对图像识别有所帮助,也对语义分割领域的发展起到巨大的促进作用。 2014 年,加州大学伯克利分校的 Long 等人提出全卷积网络(FCN),这使得卷积神经网络无需全连接层即可进行密集的像素预测,CNN 从而得到普及。使用这种方法可生成任意大小的图像分割图,且该方法比图像块分类法要快上许多。之后,语义分割领域几乎所有先进方法都采用了该模型。
1.2 FCN(全卷积网络)
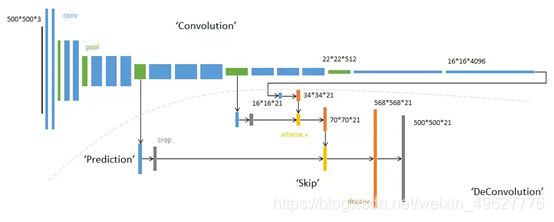
网络的整体结构分为:全卷积部分和反卷积部分。
全卷积部分:借用了一些经典的CNN网络并把最后的全连接层换成卷积,用于提取特征,形成热点图;
反卷积部分:将小尺寸的热点图上采样得到原尺寸的语义分割图像。
总的来说:FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
具体可参考:https://zhuanlan.zhihu.com/p/30195134
https://www.jianshu.com/p/14641b79a672
1.3提出的背景
虽然卷积网络已经存在很长时间了,但是由于可用训练集的大小和网络结构的大小,它们的成功受到限制。在许多视觉任务中,特别是在生物医学图像处理中,期望的输出应包括位置,所以应该给每个像素都进行标注。然而在生物医学任务中通常无法获得数千个训练图像。因此,提出了一种数据增强方法来有效利用标注数据,提出一种U型的网络结构可以同时获取上下文信息和位置信息
二、网络结构
2.1 网络组件
①U型结构
②编码器-解码器结构
编码和解码,早在2006年就发表在了Nature上。当时这个结构提出的主要作用并不是分割,而是压缩图像和去噪声。后来把这个思路被用在了图像分割的问题上,也就是现在我们看到的FCN或者U-Net结构,在它被提出的三年中,有很多很多的论文去讲如何改进U-Net或者FCN,不过这个分割网络的本质的结构是没有改动的, 即下采样、上采样和跳跃连接。
编码器逐渐减少池化层的空间维度,解码器逐步修复物体的细节和空间维度。编码器和解码器之间通常存在快捷连接,因此能帮助解码器更好地修复目标的细节。U-Net 是这种方法中最常用的结构。
③skip-connection
2.2结构详解
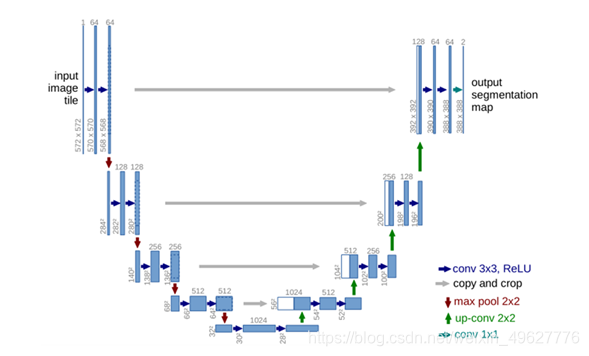
①U-net前半部分作用是特征提取,后半部分是上采样。每一个蓝色块表示一个多通道特征图,特征图的通道数标记在顶部,X-Y尺寸设置在块的左下边缘。不同颜色的箭头代表不同的操作。
②蓝色箭头代表3x3的卷积操作,channel的大小乘2,stride是1,padding为0,因此,每个该操作以后, feature map的大小会减2。输入是572x572的,但是输出变成了388x388,是因为灰色箭头表示复制和剪切操作,在同一层左边的最后一层要比右边的第一层要大一些,这就导致了,想要利用浅层的feature,就要进行一些剪切,也导致了最终的输出是输入的中心某个区域。
③红色箭头代表2x2的max pooling操作,需要注意的是,如果pooling之前feature map的大小是奇数,那么就会损失一些信息。
④绿色箭头代表2x2的反卷积操作,操作会将feature map的大小乘2,channel的大小除以2。
⑤输出的最后一层,使用了1x1的卷积层做了分类,把64个特征向量分成了2类(细胞类、背景类)。
三、方法亮点
3.1同时具备捕捉上下文信息的收缩路径和允许精确定位的对称扩展路径,并且与FCN相比,U-net的上采样过程依然有大量的通道,这使得网络将上下文信息向更高层分辨率传播。
收缩路径遵循卷积网络的典型架构。每一次下采样后都把特征通道的数量加倍。扩展路径中的每一步都首先使用反卷积,每次使用反卷积都将特征通道数量减半,特征图大小加倍。反卷积过后,将反卷积的结果与收缩路径中对应步骤的特征图拼接起来。
3.2 Overlap-tile 策略,这种方法用于补全输入图像的上下信息,可以解决由于现存不足造成的图像输入的问题。
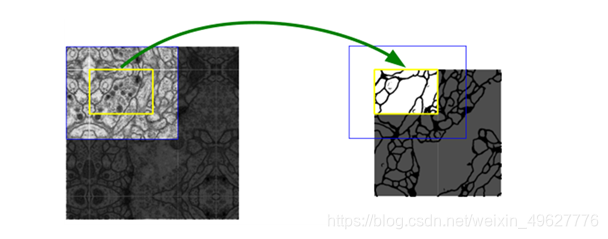
为了预测图像边界区域中的像素,通过镜像输入图像来推断缺失的上下文。 这种平铺策略对于将网络应用于大图像非常重要,因为分辨率会受到GPU内存的限制。
该策略的思想是:对图像的某一块像素点(黄框内部分)进行预测时,需要该图像块周围的像素点(蓝色框内)提供上下文信息,以获得更准确的预测。简单地说,就是在预处理中,对输入图像进行padding,通过padding扩大输入图像的尺寸,使得最后输出的结果正好是原始图像的尺寸, 同时, 输入图像块(黄框)的边界也获得了上下文信息从而提高预测的精度
3.3使用随机弹性变形进行数据增强。
作者采用了弹性变形的图像增广,以此让网络学习更稳定的图像特征。因为数据集是细胞组织的图像,细胞组织的边界每时每刻都会发生不规则的畸变,所以这种弹性变形的增广是非常有效的。

如果 σ值很大,则结果值很小,因为随机值平均为0;如果σ很小,则归一化后该字段看起来像一个完全随机的字段。
对于中间σ值,位移场看起来像弹性变形,其中σ是弹性系数。然后将位移场乘以控制变形强度的比例因子 α。 将经过高斯卷积的位移场乘以控制变形强度的比例因子 α,得到一个弹性形变的位移场,最后将这个位移场作用在仿射变换之后的图像上,得到最终弹性形变增强的数据。作用的过程相当于在仿射图像上插值的过程,最后返回插值之后的结果。
3.4使用加权损失(分离同一类别的接触物体)
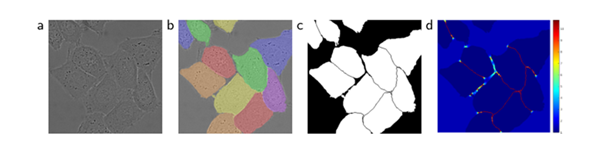
(a)原始图像
(b)标注图像实况分割 不同的颜色表示HeLa细胞的不同情况
(c)生成分割蒙版(白色:前景,黑色:背景)
(d)以像素为单位的权重映射,迫使网络学习边界像素
方法:预先计算权重图,一方面补偿了训练数据每类像素的不同频率,另一方面是网络更注重学习相互接触的细胞间边缘。
因此,使用加权损失,其中接触细胞之间的分离背景标签在损失函数中获得大的权重。预先计算每个真实分割的权重图,以补偿训练数据集中某一类像素的不同频率,并迫使网络学习,在触摸细胞之间引入的小分离边界(见图c和d)。
使用形态运算来计算分离边界。权重图计算如下:
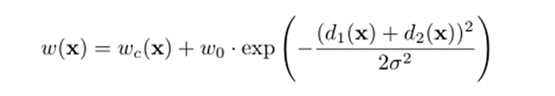
四、网络模型主要应用及结果
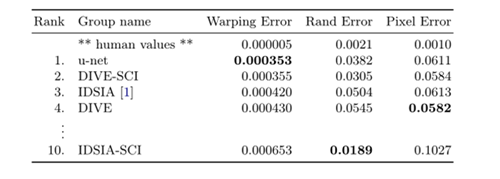
4.1在电子显微镜记录中分割神经元结构,在下图中演示了数据集中的一个例子和我们的分割结果。我们提供了全部结果作为补充材料。数据集是EM分割挑战提供的,这个挑战是从 ISBI 2012开始的,现在依旧开放。训练数据是一组来自果蝇幼虫腹侧腹侧神经索(VNC)的连续切片透射电镜的30张图像(512x512像素)。每个图像都带有一个对应的标注分割图,细胞(白色)和膜(黑色)。测试集是公开可用的,但对应的标注图是保密的,可以通过将预测的膜概率图发送给组织者来获得评估。通过在10个不同级别对结果进行阈值化和计算“warping error”, “Rand error”还有“pixel error”(预测的label和实际的label)。u-net(输入数据的7个旋转版本的平均值)无需进行任何进一步的预处理或后处理即可获得0.0003529的warping error和0.0382的Rand error。
4.2 ISBI细胞追踪挑战的结果
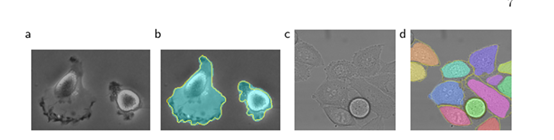
(a)" PHc-U373 "数据集输入图像的一部分。(b)分割结果(青色mask)与人工真实(黄色边框)©“DIC-HeLa”数据集的输入图像。(d)分割结果(随机彩色mask)与人工真实(黄色边框)。
4.3 ISBI细胞追踪挑战赛2015的分割结果(IOU)
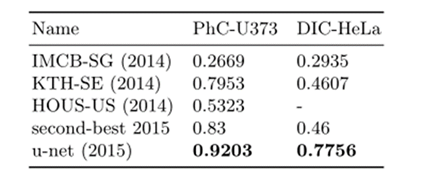
将u-net应用于光显微图像中的细胞分割任务。这项分离任务是2014年和2015年ISBI细胞追踪挑战的一部分。第一个数据集“PHc-U373”包含Glioblastoma-astrocytoma(胶质母细胞瘤-星形细胞瘤)细胞在聚丙烯酰亚胺基底上,通过相差显微镜记录。它包含35个部分注释的训练图像。实现了92%的平均IOU,这明显优于83%的第二好算法。第二个数据集“DIC-HeLa”是平板玻璃上的HeLa细胞,通过微分干涉对比显微镜记录。它包含20个部分注释的训练图像。在这里,实现了77.5%的平均IOU,这明显优于第二好的算法46%。
五、网络缺陷和不足
5.1 不足之处
感兴趣的目标尺寸非常小,对于尺寸极小的目标,U-Net分割性能可能会不好,分割效果也不好。
5.2研习Unet
①FCN与Unet的区别
U-Net和FCN非常的相似,U-Net比FCN稍晚提出来,但都发表在2015年,和FCN相比,U-Net的第一个特点是完全对称,也就是左边和右边是很类似的,而FCN的decoder相对简单,只用了一个deconvolution的操作,之后并没有跟上卷积结构。第二个区别就是skip connection,FCN用的是加操作(summation),U-Net用的是叠操作(concatenation)。这些都是细节,重点是它们的结构用了一个比较经典的思路,也就是编码和解码(encoder-decoder)结构。
②U型结构到底多深,是不是越深越好?
关于到底要多深这个问题,还有一个引申的问题就是,降采样对于分割网络到底是不是必须的?问这个问题的原因就是,既然输入和输出都是相同大小的图,为什么要折腾去降采样一下再升采样呢?
比较直接的回答当然是降采样的理论意义,我简单朗读一下,它可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。升采样的最大的作用其实就是把抽象的特征再还原解码到原图的尺寸,最终得到分割结果。
参考https://zhuanlan.zhihu.com/p/44958351
六、个人思考总结
从2015年这篇文章发表以来,Unet被引用数千次。成为大多做医疗影像语义分割任务的baseline,也启发了大量研究者去思考U型语义分割网络。
新颖的特征融合,对图像特征多尺度识别,skip connection,到现在依旧值得我们学习借鉴。
Unet延伸:
Unet-family:https://github.com/ShawnBIT/UNet-family
医学图像特点:
(1)图像语义较为简单、结构较为固定。做脑部图像的,就用脑CT和脑MRI,做胸片的只用胸片CT,做眼底的只用眼底OCT,都是一个固定的器官的成像,而不是全身的。由于器官本身结构固定和语义信息没有特别丰富,所以高级语义信息和低级特征都显得很重要。
(2)数据量少。医学影像的数据获取相对难一些,很多比赛只提供不到100例数据。所以我们设计的模型不宜多大,参数过多,很容易导致过拟合。(原始UNet的参数量在28M左右(上采样带转置卷积的UNet参数量在31M左右),而如果把channel数成倍缩小,模型可以更小。缩小两倍后,UNet参数量在7.75M。缩小四倍,可以把模型参数量缩小至2M以内)非常轻量。个人尝试过使用Deeplab v3+和DRN等自然图像语义分割的SOTA网络在自己的项目上,发现效果和UNet差不多,但是参数量会大很多。
(3)多模态。相比自然影像,医疗影像是具有多种模态的。以ISLES脑梗竞赛为例,其官方提供了CBF,MTT,CBV,TMAX,CTP等多种模态的数据。比如CBF是脑血流量,CBV用于检测巨细胞病毒的。
(4)可解释性重要。由于医疗影像最终是辅助医生的临床诊断,所以网络告诉医生一个3D的CT有没有病是远远不够的,医生还要进一步的想知道,病在哪一层,在哪一层的哪个位置,分割出来了吗,能不能求体积。
参考文章:【深度学习论文】:U-Net