二, Flume 事务和拓扑结构
文章目录
2.1, Flume事务

在Flume工作流程中, 主要有两大事务,分别是
- 在数据接收端Source和数据缓冲区Channel之间的
Put事务(推送)
Put事务:
- doPut: 将批数据写入临时缓冲区putList.
- doCommit: 检查channel内存队列是否足够合并.
- doRollback: 当channel内存队列空间不足(sink从channel拉取的数据量小于source放入channel的数据量), 会回滚数据.
- 数据缓冲区Channel和数据写出端Sink之间的
Take事务(拉取)
Take事务:
- doTake: 将数据取到临时缓冲区takeList, 并将数据发送到HDFS.
- doCommit: 如果数据全部发送成功, 则清除临时缓冲区takeList.
- doRollback: 数据发送过程中如果出现异常, 执行rollback(将临时缓冲区takeList中的数据全部归还给channel内存队列.)
源码分析: 待补充
2.2, Flume Agent 内部原理

详细说明如下:
- Source在接受数据后, 可不是直接就把event(事件,Flume基本传输单位)传给channel暂存, 而是
先经过Channel Processor的处理 Channel Processor把event传给拦截器链, Inteceptor 拦截器主要是对event进行初步的数据清洗,拦截器实现修改和过滤event的功能.Channel Processor 再把拦截器处理过的event传给选择器, 一个souce可以向多个channel同时写数据,所以也就产生了以何种方式向多个channel写的问题,Channel Selector(channel 选择器)主要是提供Source选择Channel的策略.主要有两大策略:1. Replicating Channel Selector(复制Channel选择器): 会把数据完整地发送到每一个channel;2. Multiplexing Channel Selector(多路复用Channel 选择器): 通过配置来按照一定的规则发送指定类型的event到指定的Channel上,听起来很像负载均衡;- 经过Channel Interceptor和Channel Selector的处理后,
Channel Processor会把Interceptor拦截器处理过的事件, 根据Selector选择器得出的Channel列表, 写入到每一个Channel中. SinkProcessor就是控制Sink获取Channel数据的策略, 主要有三种DefaultSinkProcessor(单独),LoadBalacingSinkProcessor(负载均衡),FailoverSinkProcessor(故障转移).
----------> 待补充
注意: ** 一个Sink只能对应于一个Channel, 但是一个Channel能对应于多个Sink.**
2.3, Flume 拓扑结构
2.3.1 简单串联

这种拓扑结构要求相互连接的agent之间必须使用Avro sink 进行连接.
2.3.2 复制和多路复用

应用: 当syslog, java, nginx、 tomcat等混合在一起的日志流流入到一个Sources后,将混杂的日志流分开放入到多个Channel进行缓存,然后给每种日志建立一个自己的Sink写出到不同的地方(HDFS, 下一个agent, logger 等等)。
2.3.3 负载均衡或故障转移

这种拓扑结构可以用于负载均衡或者故障转移, Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上 。
- 在用于负载均衡时, 我们只需要
把agent1中的数据通过它的Sink分散到后部不同的agent2, agent3, agent4中便可以实现负载均衡,因为要写出的数据分散到多个agent中, 多个agent中的多个channel对待写出数据进行缓冲, 降低了接受写出数据目标(的HDFS中的磁盘)的负载. - 在用于故障转移时, 我们
给agent2,agent3, agent4设置不同的优先级, 规定只有最高优先级才能执行写出过程,而当优先级最高的agent挂掉时, 让优先级次高的继续执行写出, 提高了执行效率.
2.3.4 聚合

- 这种模式是我们最常见的,也非常实用,日常 web 应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。
- 用 flume 的这种组合方式能很好的解决这一问题,
每台服务器部署一个 agent 采集日志,传送到一个集中收集日志的 agent,再由此 agent上传到 hdfs、hive、hbase 等,进行日志分析。
2.4 企业开发案例
一, Channel 副本选择器的策略(复制, 多路复用)
2.4.0 复制和多路复用(单个agent独立完成)
[案例需求和需求分析]

- 在同一个agent内, 我们把Sources获取到的日志信息交给多个Channel缓存, 再设置多个不同的Sink拉取Channel缓存到的日志信息, 完成了复制和多路复用的功能.
[案例实操]
- 先写好配置文件
agent1.conf, 放入到 flume安装目录/job/group1中.
# 根据需求分析, 我们需要监控target.log(目标日志文件) 并分别把其改动内容写入到HDFS 和 本地文件系统上.
## 我们采用了复制和多路复用的拓扑结构.
####1️⃣ ,使用一个sources接收日志文件并监控.
#### 2️⃣, 使用两个sink分别负责写出数据到HDFS和本地文件系统
#### 3️⃣, 注意: 此案例中我们使用两个channel分别给两个sink缓存数据, 但是,
########## 由于一个sink只能对应于一个channel, 而一个channel可以对应于多个sink, 在缓存数据相同的情况下, 我们使用一个一个channel给多个sink缓存数据也是同样可行的.
# 1. 给agent1的各个组件命名
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
#2. 配置sources (default sources)
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive-3.1.2/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# 3. 配置sink(hdfs + file_roll sink)
### 3.1 负责写出到HDFS的 hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://bigdata01:8020/hive_logs/%Y%m%d/%H
##### hdfs sink的自定义设置
###### 上传文件的前缀(hdfs.filePrefix)
a1.sinks.k1.hdfs.filePrefix = log_
###### 是否按照时间滚动文件夹(hdfs.round)(每个一段时间重新创建文件并写入监控文件的内容)
a1.sinks.k1.hdfs.round = true
###### 多少倍时间间隔单位创造一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
###### 重新定义创建新文件夹的时间间隔
a1.sinks.k1.hdfs.roundUnit = hour
###### 是否使用本地时间戳(而不是事件头中的时间戳)
a1.sinks.k1.hdfs.useLocalTimeStamp = true
###### 积攒多少个event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 100
###### 设置文件类型, 可支持压缩, 还可以解决乱码问题
a1.sinks.k1.hdfs.fileType = DataStream
###### 多久生成一个新的文件
a1.sinks.k1.hdfs.rollnterval = 30
###### 设置每个文件的滚动(重命名原日志文件进行归档,并生成新的日志文件用于log写入)大小
a1.sinks.k1.hdfs.rollSize = 134217700
a1.sinks.k1.hdfs.rollCount = 0
### 3.2 负责写出到本地文件系统的 file_roll sink(目标写入文件目录一定要存在!!!!!)
a1.sinks.k2.type = file_roll
a1.sinks.k2.sink.directory =/opt/module/data/flume-data
# 4. 配置channel
a1.channels.c1.type = memory
a1.channels.c2.type = memory
#### memory channel 的自定义设置
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 5. 把sources, sinks 与 channel绑定
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
在这里一定要注意: file_roll sink 指定的directory 必须是已经存在的!
- 运行 flume
bin/flume-ng agent -n a1 -c conf/ -f job/group1/agent1.conf -Dflume.root.logger=INFO,console
- 最终结果如下:
-
flume 运行成功的标志:

-
查询hive, 在本地文件系统(file_roll sink作用)生成的日志:

-
在hdfs中生成的文件内容:
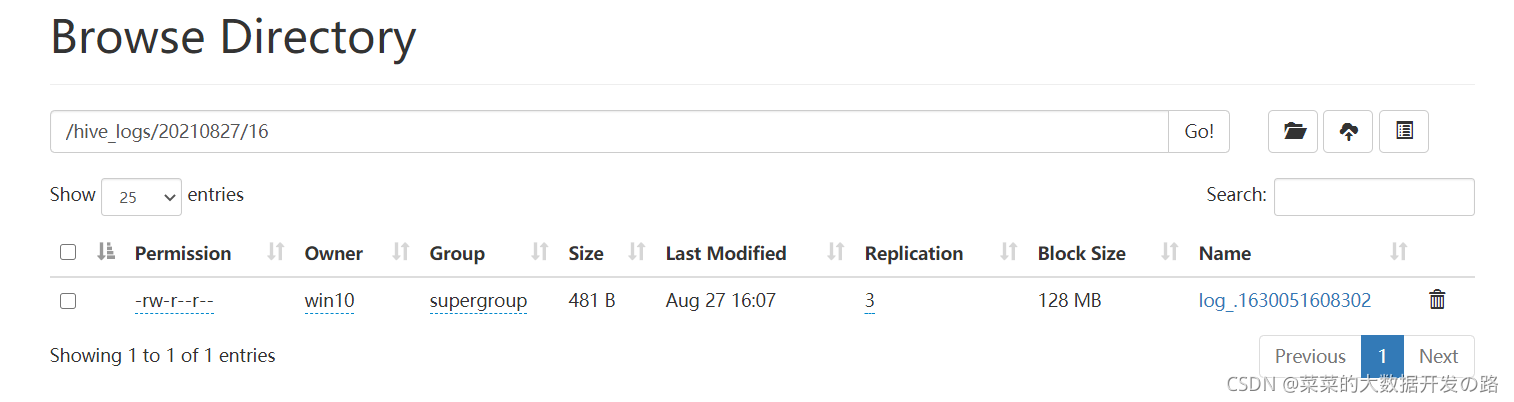
在本次案例中, 一定要对配置文件的书写多加注意! 多根据输入开启flume指令后的控制台输出定位错误.
2.4.1 复制和多路复用(多个agent配合完成)
[案例需求和需求分析]
使用 Flume-1 监控文件变动,
- Flume-1 将变动内容传递给 Flume-2,Flume-2 负责存储到 HDFS。
- 同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 Local FileSystem。

注意: 上图中 flume-1, flume-2, flume-3 分别对应于三个agent, 所以我们要对应的写出三个配置文件, 反正就是挺脱裤子放屁的一个案例, 明明跟上一个案例一样的需求, 可以用一个agent(即多个不同类型sink输出)就能够解决复制和多路复用.
[案例实操]
- 根据上图中flume-1, 我们可写出配置文件1 ,
flume-1.conf
简单分析,
- 我们把flume-1 看作是所有数据的分发节点, 理所应当需要多个sink(此处我们拓展为了多个agent中的多个sink)去写出不同输出目的地(hdfs, local fs)的数据, 所以相应的我们就需要多个channel分别去缓存数据(如果数据都是一样的话, 一个channel也是可以的).
- 又因为我们
多个agent进行相连接, 我们的flume-1中agent1的sink就必须都得是 avro sink, flume-2和flume-3 因为与flume-1相连接, 所以应该是avro source
# agent1的各个组件的名称
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 配置sources(exec)
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive-3.1.2/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# 配置sinks(包括sink1 和 sink2)
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = bigdata01
a1.sinks.k1.port = 4041
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = bigdata01
a1.sinks.k2.port = 4042
# 配置channels(包括channel1 和 channel2)
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 绑定 sink channel sources
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
- 根据上图flume-2, 我们写出配置文件2,‘flume-2.conf’
flume-2的作用是利用 avro source接收分发的日志数据, 并利用hdfs sink 把日志数据更新到hdfs中去.
# agent2 a2 的各个组件的名称
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# 配置 sources r2 (avro)
a2.sources.type = avro
a2.sources.hostname = bigdata01
a2.sources.port = 4041
# 配置 sinks k2 (hdfs sink)
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://bigdata01:8020/hive-log-multiAgent
### 防止出现乱码
a2.sinks.k2.hdfs.fileType = DataStream
# 配置 channels
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# 把sources, sinks 分别与channels 绑定
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
- 根据上图flume-3, 我们写出配置文件3,‘flume-3.conf’
flume-3的作用是利用 avro source接收分发的日志数据, 并利用file_roll sink 把日志数据更新到本地文件系统中去.
# agent3 a3 的各个组件的名称
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# 配置 sources r3 (avro)
a3.sources.type = avro
a3.sources.hostname = bigdata01
a3.sources.port = 4041
# 配置 sinks k3 (file_roll sink)
a2.sinks.k3.type = file_roll
a2.sinks.k3.directiory = /opt/module/data/
# 配置 channels
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# 把sources, sinks 分别与channels 绑定
a3.sources.r2.channels = c3
a3.sinks.k3.channel = c3
要注意到:
avro sink的三个必须配置项为: type, hostname, port
avro source 的三个必须配置项为 type, bind, portavro source 为avro sink的服务端.
- 运行 flume
注意:
先启动下游数据流, 显而易见是因为下游是接收数据端, 理应首先开启等待数据的到来.另外,
带有avro source的是服务端!
bin/flume-ng agent -n a3 -c conf/ -f job/group1/flume-3.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent -n a2 -c conf/ -f job/group1/flume-2.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent -n a1 -c conf/ -f job/group1/flume-1.conf -Dflume.root.logger=INFO,console
- 最终结果如下:
-
flume 运行成功的标志:

-
查询hive, 在本地文件系统(file_roll sink作用)生成的日志:略
-
在hdfs中生成的文件内容:略
二, Sink Processor的策略(负载均衡, 故障转移)
2.4.2 负载均衡/故障转移()
failover Sink processor: maxpenalty, sink挂掉之后的最大回退时间(), 在这个时间内不会考虑使用这个sink
[案例需求和需求分析]
需求: 使用 Flume1 监控一个端口(这里采用netcat),其 sink 组中的 sink1, sink2 分别对接 Flume2 和 Flume3,采用 FailoverSinkProcessor,实现故障转移的功能。
- 再次复习一下, FailoverSinkProcessor 故障转移的原理, 设立sinkgroup, 为其中的每个sink(k1, k2,…) 设置优先级, 每次选择优先级最高的sink输出数据.
- 最后面设置sink的最大故障回退时间(maxpenalty, 以毫秒为单位), 就是某个sink发生故障后, 在给定的maxpenalty时间内不会考虑使用这个sink(即便这个sink已经恢复运行)
故障转移核心配置如下:
#### sink组的策略(故障转移)(配置sinks的策略为故障转移)--核心
a1.sinkgroups = g1
a1.sinkgrops.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000

[案例实操]
- flume安装目录下, 在job目录中新建group1目录 并新建
flume-1.conf, 这是作为agent1, 用来配置sink processor和往后分发数据.
# 命名组件
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
#配置sources (netcat source)
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#配置channels(memory channel)
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sinks(avro sinks)
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = bigdata01
a1.sinks.k1.port = 4041
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = bigdata01
a1.sinks.k2.port = 4043
#### sink组的策略(故障转移)(配置sinks的策略为故障转移)--核心
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
# 绑定各个组件--核心
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
- 建立
flume-2.conf,flume-3.conf, 作为接收不同优先级sink写出数据的两个agent.
接收k1的写出数据
# 命名组件
a2.sources = r2
a2.channels = c2
a2.sinks = k2
#配置sources
a2.sources.r2.type = avro
a2.sources.r2.bind = bigdata01
a2.sources.r2.port = 4041
#配置channels
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# 配置sinks
a2.sinks.k2.type = logger
# 绑定各个组件
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
接收k2的写出数据
# 命名组件
a3.sources = r3
a3.channels = c3
a3.sinks = k3
#配置sources
a3.sources.r3.type = avro
a3.sources.r3.bind = bigdata01
a3.sources.r3.port = 4043
#配置channels
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# 配置sinks
a3.sinks.k3.type = logger
# 绑定各个组件
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
最终实验结果:

负载均衡的配置步骤类似于故障转移, 只需要把上面的核心配置修改为下面的形式, 其他一切操作均相同.
# sinkgroup 负载均衡配置
a1.sinkgroup = g1
a1.sinkgroup.g1.sinks = k1 k2
a1.sinkgroup.g1.processor.type = load_balance
a1.sinkgroup.g1.processor.backoff = true
a1.sinkgroup.g1.processor.selector = random
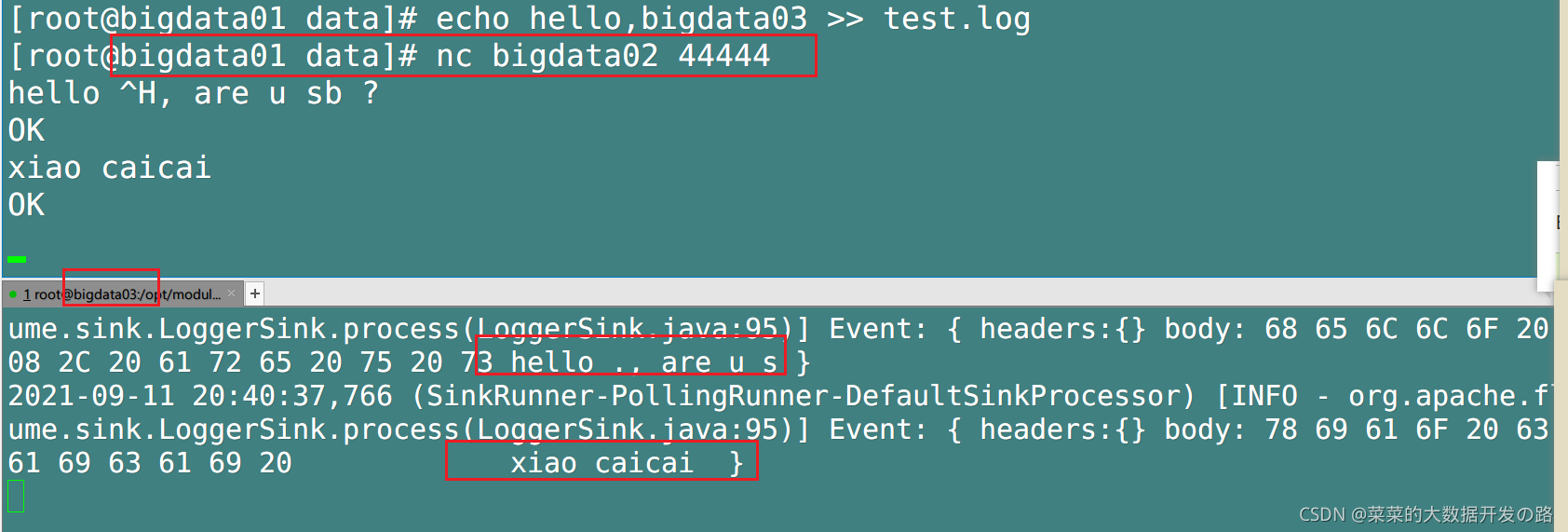
2.4.2 聚合(多数据源单出口汇总)
[案例需求和需求分析]
需求:
对bigdata01主机 /opt/module/data/test.log 进行监听;
对对bigdata02主机 的某个端口进行监听;
把bigdata01, bigdata02 主机的数据打印到bigdata03主机的控制台上.

[案例实操]
由于针对每一个主机的监听和数据传送需要在此主机上执行配置文件和flume, 所以我们先在bigdata01主机上编写好配置文件, 完了使用xsync(前面大数据集群搭建曾提到过的一个自定义脚本)直接把flume目录同步到其他主机即可.
- 由需求可知, 我们在bigdata01主机上对某个文件进行监控, 然后把文件的数据变化提交到bigdata03主机上并输出到此主机控制台, 编写配置文件
flume-1.conf如下:
# 命名各个组件
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置sources(exec source)
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/data/test.log
a1.sources.r1.shell = /bin/bash -c
# 配置sinks (avro sink)
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = bigdata03
a1.sinks.k1.port = 2021
# 配置channel (memory channel)
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 绑定各个组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 在bigdata02中, 要求我们使用netcat sources 监听端口4444, 并把提交到bigdata03主机上并输出到此主机控制台, 编写配置文件
flume-2.conf如下
## 远程服务器监听端口数据传输
a2.sources = r2
a2.sinks = k2
a2.channels = c2
#配置sources
a2.sources.r2.type = netcat
a2.sources.r2.bind = bigdata02
a2.sources.r2.port = 44444
#配置sinks
a2.sinks.k2.type = avro
a2.sinks.k2.hostname = bigdata03
a2.sinks.k2.port = 2021
# 配置channel (memory channel)
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# 绑定各个组件
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
- bigdata03 使用 avro sources 接受前面两个主机的数据, 并使用 logger sink打印到控制台. 所以有配置文件
flume-3.conf如下:
## 接收前两个agent 的数据并输出到控制台
a3.sources = r3
a3.sinks = k3
a3.channels = c3
#配置sources
a3.sources.r3.type = avro
a3.sources.r3.bind = bigdata03
a3.sources.r3.port = 2021
#配置sinks
a3.sinks.k3.type = logger
# 配置channel (memory channel)
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# 绑定各个组件
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
- 验证:
为了方便起见, 我们把对 bigdata01主机上文件test.log 的追加操作和对bigdata02主机某个端口发送数据都放在bigdata01主机上执行:
- 验证监控文件 test.log

- 验证端口4444的数据