Presto(暂译:普雷斯托)系列文章目录-CHAPTER 6 Connectors
This book provides a great introduction to Presto and teaches you everything
you need to know to start your successful usage of Presto.
—Dain Sundstrom and David Phillips, Creators of the Presto
Projects and Founders of the Presto Software Foundation
Presto plays a key role in enabling analysis at Pinterest. This book covers the Presto essentials, from use cases through how to run Presto at massive scale.
—Ashish Kumar Singh, Tech Lead,
Bigdata Query Processing Platform, Pinterest

文章目录
- Presto(暂译:普雷斯托)系列文章目录-CHAPTER 6 Connectors
- 前言
- CHAPTER 6 Connectors
-
- 1.Configuration
- 2. RDBMS Connector Example PostgreSQL
- 3. Query Pushdown
- 4. Parallelism and Concurrency
- Other RDBMS Connectors
- Security
- Presto TPC-H and TPC-DS Connectors
- Hive Connector for Distributed Storage Data Sources
- Apache Hadoop and Hive
- Hive Connector
- Hive-Style Table Format
- Managed and External Tables
- Partitioned Data
- Loading Data
- File Formats and Compression 文件格式和压缩
- Non-Relational Data Sources
- Presto JMX连接器
- Black Hole Connector
- Memory Connector
- 其他连接器
- 结论
- CHAPTER 7 高级连接器
前言
Presto: The Definitive Guide SQL at Any Scale, on Any Storage,in Any Environment
——Matt Fuller, Manfred Moser, and Martin Traverso
- Part I. Getting Started with Presto
-
- Introducing Presto.
-
- Installing and Con€guring Presto
-
- Using Presto
- Part II. Diving Deeper into Presto
-
- Presto Architecture
-
- Production-Ready Deployment
-
Connectors
-
Advanced Connector Examples
-
- Using SQL in Presto.
-
- Advanced SQL
- Part III. Presto in Real-World Uses
-
- Security
-
- Integrating Presto with Other Tools
-
- Presto in Production.
-
- Real-World Examples
-
- Conclusion.
- Index
提示:以下是本篇文章正文内容,非专业翻译,下面翻译仅供参考
CHAPTER 6 Connectors
在第3章中,您将目录配置为使用连接器来访问目录中的数据源。特别是TPC-H基准数据,然后t通过TOC-H连接器了解一些有关如何使用SQL查询数据。catalogs是使用Presto的重要方面。他们定义了与基础数据源和存储系统,并使用诸如连接器之类的概念,模式和表。这些基本概念在第4章中进行了介绍,并介绍了它们的基本概念。在第8章中将更详细地讨论与SQL结合使用。连接器可转换基础数据源的查询和存储概念,诸如关系数据库管理系统(RDBMS),对象存储或键值存储,例如表,列,行和数据类型的SQL和Presto概念。这些可以是简单的SQL到SQL的转换和映射,但还有更多从SQL到对象存储或NoSQL系统的复杂转换。这些可以也可以由用户定义。您可以像考虑数据库驱动程序一样来考虑连接器。它将用户输入转换为基础数据库可以执行的操作。每个连接器都实现Presto服务提供商接口(SPI)。这使Presto允许您使用相同的SQL工具来处理任何基础连接器公开的数据源,并使Presto成为SQL-on-Anything系统。查询性能还受连接器实现的影响。最多基本连接器与数据源建立单一连接,并将数据提供给Presto。但是,更高级的连接器可以将一条语句分解为多个连接,并行执行操作以获得更好的性能。连接器的另一个高级功能是提供表统计信息,然后可以基于成本的优化器使用它来创建高性能的查询计划。但是,连接器的实现更为复杂。
普雷斯托提供了许多连接器:·
- 用于RDBMS系统的连接器,如PostgreSQL或MySQL-参见第87页·
- 适合于查询系统的Hive连接器使用Hadoop分布式文件系统(HDFS)和类似的对象存储系统;参见第93页中的“用于分布式存储数据源的Hive连接器”
- 许多非关系数据源的连接器 请参阅第104页
- tpch和tpcds连接器上的“非关系数据源”,该连接器旨在服务于TPC基准数据-请参阅第92页PrestoTPC-H和TPC-DS连接器
- Java管理人员的连接器上的扩展或JMX-参见第104页的“Presto JMX Connector”
在本章中,您将了解更多关于这些连接器的信息,这些连接器可从Presto项目中获得。 Presto二十多个连接器,更多的是由Presto团队和用户社区创建的。 商业,属性连接器也可以进一步扩大普雷斯托的范围和性能。 如果您有自定义数据源,或者没有连接器,则可以通过实现必要的SPI调用并将其放入插件目录中来实现您自己的连接器。
catalog和连接器使用的一个重要方面是,它们都可以同时用于Presto中的SQL语句和查询。 这意味着您可以创建跨数据源的查询。 例如,您可以将来自关系数据库的数据与存储在对象存储后端的文件中的数据结合起来。 这些联合查询将在更详细的讨论第122页的n“Presto中的查询联邦。
1.Configuration
正如第23页“添加数据源”中所讨论的,您想要访问的每个数据源都需要通过创建catalog来配置为catalog文件。 文件的名称在写查询时确定catalog的名称。 强制属性connector.name指示目录使用哪个连接器。 相同的连接器可以在不同的目录中多次使用;例如,使用相同的技术(如PostgreSQL)访问具有不同数据库的不同RDBMS服务器实例。 或者如果你有两个HIve集群,您可以在一个Presto集群中配置两个目录,它们都使用Hive连接器,允许您查询来自两个Hive集群的数据。
2. RDBMS Connector Example PostgreSQL
Presto包含开源和专有RDBMS的连接器,包括My SQL、Postgre SQL、AWS Redshift和Microsoft SQL Server。 Presto通过我们的连接器查询这些数据源每个系统各自的JDBC驱动程序。 让我们看看一个使用PostgreSQL的简单示例。
PostgreSQL实例可以由几个数据库组成。 每个数据库都包含模式,其中包含对象例如表格和视图。 在使用Postgre SQL配置Presto时,您可以选择作为catalog公开在Presto中的数据库中。在创建一个指向服务器中特定数据库的简单目录文件etc/catalog/postgresql.properties之后,重新启动Presto,您可以找到更多信息。 您还可以看到postgresql连接器被配置为所需的connector.name:
connector.name=postgresql
connection-url=jdbc:postgresql://db.example.com:5432/database
connection-user=root
connection-password=secret
- 目录属性文件中的用户和密码确定对底层数据源的访问权限。 例如,这可以用来限制对只读操作或限制访问的可用表格。
您可以列出所有目录以确认新目录可用,并使用PrestoCLI或使用JDBC驱动程序的数据库管理工具检查详细信息(如第25页的 “Presto Command-Line Interface” 中所解释的和第30页的“PrestoJDBC驱动程序):
SHOW CATALOGS;
Catalog
------------
system
postgresql
(2 rows)
SHOW SCHEMAS IN postgresql;
Catalog
------------
public
airline
(2 rows)
USE postgresql.airline
SHOW TABLES;
Table
---------
airport
carrier
(2 rows)
在本例中,您可以看到我们连接到一个Postgre SQL数据库,该数据库包含两个模式:public and airline。 然后在airline的模式中有两张表,airport and carrier。 让我们试试跑一个查询。 在本例中,我们向Presto发出SQL查询,其中表存在于Postgre SQL数据库中。 使用PostgreSQL连接器,Presto能够检索用于处理、返回的数据将结果发送给用户:
SELECT code, name FROM airport WHERE code = 'ORD';
code | name
------+------------------------------
ORD | Chicago O'Hare International
(1 row)
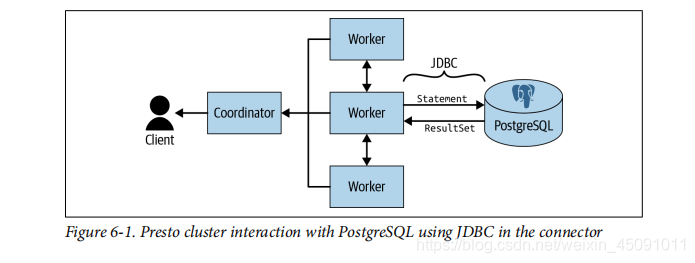
如图6-1所示,客户端将查询提交给Presto协调节点。 它将工作卸载给一个worker,该worker使用JDBC将整个SQL查询语句发送到PostgrSQL。 Postgre SQL JDBC驱动程序包含在Postgres SQL连接器中。 Postgre SQL处理查询并通过JDBC返回结果。 连接器读取结果并将其写入Presto内部data格式。 Presto继续对进行处理,将其提供给协调节点,然后将结果返回给用户。
3. Query Pushdown
正如我们在前面的示例中所看到的,Presto能够通过将SQL语句下推到底层数据源来加载处理。 这被称为查询下推,或SQL下推。 优点是,由于底层系统可以减少返回Presto的数据量,避免不必要的内存、CPU和网络IO成本。 此外,像Postgre SQL这样的系统通常具有索引在某些筛选列上,允许更快的处理。
但是,并不总是能将整个SQL语句下推数据源。 目前,Presto连接器SPI限制了可以下推到过滤器和列投影的操作类型:
SELECT state, count(*)
FROM airport
WHERE country = 'US'
GROUP BY state;
给定前面的Presto查询,PostgreSQL连接器构造SQL查询下推到PostgreSQL:
SELECT state
FROM airport
WHERE country = 'US';
当查询由RDBMS connector推送时,有两个重要的地方可以查看。 SELECT列表中的列被设置为Presto需要的特定列。 在这种情况下,我们只需要在Presto中处理GROUP BY的状态列。 我们还推动过滤country = ‘US’,这意味着我们不需要对state column进行进一步的处理。 你注意到了aggregations不会被下推到PostgreSQL。 这是因为Presto无法向下推送任何其他形式的查询,聚合必须在Presto中执行。 这可能是有利的因为Presto是一个分布式查询处理引擎,而PostgreSQL不是。 如果您确实希望将额外的处理下推到底层的RDBMS源,则可以使用视图来完成这一点。 如果将处理封装在PostgreSQL中的视图中,则将其作为表暴露给Presto,并且处理发生在PostgreSQL中。 例如,假设您在PostgreSQL中创建视图SQL:
CREATE view airline.airports_per_us_state AS
SELECT state, count(*) AS count_star
FROM airline.airport
WHERE country = 'US'
GROUP BY state;
当您在Presto中运行ShowTables时,您可以看到此视图:
SHOW TABLES IN postgresql.airline;
Table
---------
airport
carrier
airports_per_us_state
(3 rows)
SHOW CATALOGS;
Catalog
------------
system
mysql-dev
mysql-prod
mysql-site
(2 rows)
现在您可以只查询视图,所有处理都被推到PostgreSQL,因为视图显示为Presto的普通表:
SELECT * FROM airports_per_us_state;
4. Parallelism and Concurrency
目前,所有RDBMS连接器都使用JDBC与底层数据源进行单个连接。 数据不是并行读取的,即使底层数据源是并行系统。并行系统像Teradata或Vertica这样的系统,您必须编写并行连接器,以利用这些系统如何以分布式方式存储数据。 当从多个表访问时在相同的RDBMS中,为查询中的每个表创建并使用JDBC连接。 例如,如果查询在Postgre SQL中的两个表之间执行连接,Presto将创建两个不同的连接通过JDBC检索数据,如图6-2所示。 它们并行运行,将结果发回,然后在Presto中执行连接
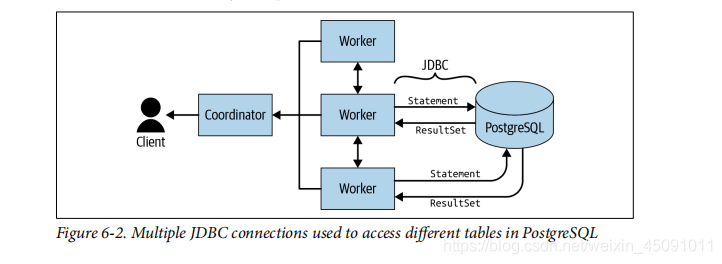
与聚合一样,连接不能被下推。 但是,如果您想利用底层Postgre SQL系统中可能的性能增强,可以在Postgre SQL中创建视图,甚至添加本地索引以进行进一步改进。
Other RDBMS Connectors
目前,Presto开源项目有四个RDBMS连接器。 MySQL、PostgreSQL、AWS Redshift和Microsoft SQLServer连接器已经包含在Presto的插件目录中并准备配置。 如果您有多个服务器,或者希望分开访问,您可以为每个实例在Presto中配置多个目录。 您只需要命名不同的*.properties文件。 和往常一样,属性文件的名称决定目录的名称:
SHOW CATALOGS;
Catalog
------------
system
mysql-dev
mysql-prod
mysql-site
(2 rows)
不同的RDBMS之间存在细微差别。 让我们来看看它们的目录配置文件中是如何配置的。 在MySQL中,数据库和模式以及catalog之间没有区别,JDBC连接字符串基本上指向特定的My SQL服务器实例:
connector.name=mysql
connection-url=jdbc:mysql://example.net:3306
connection-user=root
connection-password=secret
PostgreSQL明确区分,实例可以包含包含模式的多个数据库。 特定数据库中的JDBC连接点:
connector.name=postgresql
connection-url=jdbc:postgresql://example.net:5432/database
connection-user=root
connection-password=secret
AWS Redshift目录看起来类似于Postgre SQL目录。 事实上,Redshift使用Postgre SQL JDBC驱动程序,因为它基于开源Postgre SQL代码,JDBC驱动程序兼容使用:
connector.name=redshift
connection-url=jdbc:postgresql://example.net:5439/database
connection-user=root
connection-password=secret
Microsoft SQLServer连接字符串与MySQL字符串相似。 然而,SQLServer确实有数据库和模式的概念,并且示例简单地连接到默认数据库:
connector.name=sqlserver
connection-url=jdbc:sqlserver://example.net:1433
connection-user=root
connection-password=secret
使用不同的数据库,如Sales,必须配置一个属性:
connection-url=jdbc:sqlserver://example.net:1433;databaseName=sales
Security
目前,对RDBMS连接器进行身份验证的唯一方法是将用户名和密码存储在目录配置文件中。 因为Presto集群中的机器被设计为可信系统,这应该足以用于大多数用途。 为了保持Presto和连接的数据源的安全,重要的是确保对机器和配置文件的访问。 它会我们被当作私钥来对待。 Presto的所有用户使用与RDBMS相同的连接。 如果您不想在明文中存储密码,则有方法通过用户名以及来自Presto客户端的密码。 我们在第10章中进一步讨论这一点。 总之,使用带有RDBMS的Presto是很容易的,并且允许您在一个地方公开所有的系统并查询它们同时。 仅此使用就已经为Presto的使用提供了一个显著的好处。 当然,当你用其他连接器添加更多的数据源时,它会更有趣。 所以让我们继续学习更多。
Presto TPC-H and TPC-DS Connectors
您已经在第2章中发现了TPC-H连接器的用法。 让我们仔细看看。 将TPC-H和TPC-DS连接器内置到Presto中,并提供一组模式来支持TPC基准H(TPC-H)和TPC基准DS(TPC-DS)。 这些数据库基准套件来自事务处理Perfor-Mance理事会,是用于数据库系统的行业标准基准测量高度复杂的决策支持数据库的性能。 连接器可用于测试Presto的功能和查询语法,而无需配置对外部数据的访问来源。 当您查询TPC-H或TPC-DS模式时,连接器使用确定性算法快速生成一些数据。
创建目录属性文件etc/catalog/tpch.properties,以便conf配置TPC-H连接器:
connector.name=tpch
对于TPC-DS连接器,配置是相似的;例如,具有etc/catalog/tpch.properties:
connector.name=tpcds
两个连接器都暴露了在结构方面包含相同数据集的模式:

您可以使用这些数据集来了解更多关于Presto支持的SQL的信息,如第8章和第9章所讨论的,而不需要连接另一个数据库。 连接器另一个重要用例是数据的简单可用性。 您可以使用连接器进行开发和测试,甚至可以使用生产Presto部署。 有了大量的数据就很容易获得了,您可以构建查询,在Presto集群上放置一个重要的负载。 这允许您更好地支持集群的性能,调优和优化它,并确保它执行完毕时间和跨版本更新和其他更改。
Hive Connector for Distributed Storage Data Sources
正如你在第16页的“Presto简史”中所学到的,Presto被设计成在Facebook规模上运行快速查询。 鉴于Facebook在其Hive数据仓库中有大量存储,Hive连接器作为与Presto一起开发的第一个连接器是很自然的。
Apache Hadoop and Hive
在您了解Hive连接器及其以及它适合多种对象的存储格式,您需要重新掌握有关Apache Hadoop和Apache Hive。如果您对Hadoop和Hive不太熟悉,并且想了解更多信息,我们建议您修补项目的官方网站,网络上的视频和其他资源,以及一些可用的好书。例如,Edward Capriolo 的Programming Hive等。(O’Reilly)已被证明是我们的理想指导书。目前,我们需要讨论某些Hadoop和Hive概念,为Presto的使用提供足够的上下文。
Hadoop的核心是Hadoop分布式文件系统(HDFS)和应用程序软件(例如Hadoop MapReduce)与存储在其中的数据进行交互HDFS。Apache YARN用于管理Hadoop应用程序所需的资源位置。Hadoop是领先的系统,可用于跨大数据集的分布式处理计算机集群。它能够扩展系统,同时保持较高的性能。计算机群集上的可用服务。最初,数据处理是通过编写MapReduce程序进行的。他们遵循一个特定的编程模型,该模型使数据处理变得自然集会分布在整个集群中。该模型运行良好且健壮。然而,编写用于分析问题的MapReduce程序很麻烦。 它也不能很好地为依赖SQL和数据仓库的现有基础设施、工具和用户进行迁移。
Hive提供了使用MapReduce的替代方法。它被创建为一种方法在Hadoop之上提供SQL抽象层以与HDFS中的数据进行交互使用类似SQL的语法。现在,大量了解和理解SQL的用户可以与HDFS中存储的数据进行交互。配置单元数据在HDFS中存储为文件,通常称为对象。这些文件使用例如ORC,Parquet等其他格式。使用特定的文件存储文件Hive理解的目录和文件布局;例如,分区和分桶表格。我们将布局称为Hive风格表格式。
Hive元数据描述了HDFS中存储的数据如何映射到架构,表和列通过SQL查询的列。此元数据信息保存在数据库中例如MySQL或PostgreSQL,可通过Hive Metastore Service(HMS)访问。Hive运行时提供类似SQL的查询语言和分布式执行层执行查询。Hive运行时将查询转换为一组MapReduce可以在Hadoop群集上运行的程序。随着时间的流逝,Hive已演变为提供其他执行引擎,例如Apache Tez和Spark,查询被翻译成对应的的SQL方言。
Hadoop和Hive在整个行业中得到了广泛的应用。 随着它们的使用,HDFS的格式已经成为许多其他分布式存储系统的支持格式,如AmazonS3和S3兼容的存储资源,Azure数据湖存储,AzureBlob存储,谷歌云存储等。
Hive Connector
用于Presto的Hive连接器允许您连接到HDFS对象存储集群。 它利用HMS中的元数据,查询和处理存储在HDFS中的数据。 利用Hive连接器从分布式存储(如HDFS或云存储)读取数据可能是Presto的使用案例中最普通的之一。
- Presto和Presto Hive连接器根本不使用Hive运行。 Presto是FaceBook对Hive的升级替代品,适合运行交互式查询。
Hive连接器允许Presto从分布式存储(如HDFS)读写。 然而,它不受HDFS的限制,而是设计用于一般的分布式存储。 目前,您可以配置Hive连接器与HDFS、AWSS3、AzureBlob存储、Azure数据湖存储、Google云存储和S3兼容存储一起工作。 与S3兼容的存储可以包括MinIO,Ceph,IBM Cloud Object Storage,Swift Stack,Cloudian,Riak CS,Leo FS,Open IO等。 存在着各种兼容的存储。 只要它们实现了S3API并以相同的方式运行,Presto不需要知道大部分的区别。
由于Hadoop和其他兼容系统的广泛使用,HDFS和Hive连接器的扩展特征集支持t嗯,它可以被认为是用Presto查询对象存储的主要连接器,因此对于许多(如果不是大多数)Presto用户来说是至关重要的。 架构上,Hive连接器与RBDMS和其他连接器有点不同,因为它根本不使用Hive引擎本身。 因此,它不能将SQL处理推送到Hive。 相反,它只是使用HMS(HIve Metastore Service)中的元数据,使用Hadoop项目提供的HDFS客户端直接访问HDFS上的数据。 它还以分布式存储中的数据组织方式假定Hive表格式。
总之,模式信息是从HMS访问的,数据布局与Hive数据仓库相同。 这些概念是相同的,但数据存储在一个位置以外的位置HDFS。 然而,与Hadoop不同的是,这些非Hadoop分布式文件系统并不总是有一个相当于存储的HMS供Presto使用的元数据。 为了利用Hive风格的表格式,您必须配置Presto来使用现有Hadoop集群中的HMS或您自己的独立HMS。 这可能意味着你使用其它来替换HMS,如AWS Glue,或只使用HMS运行最小的Hadoop部署。 使用HMS描述除HDFS之外的BLOB存储中的数据,允许使用Hive Connector来查询这些数据储存系统。 这将通过Presto和任何能够使用SQL的工具将存储在这些系统中的数据解锁到SQL使用的所有功能。
配置catalog以使用Hive连接器需要您若要创建具有所需名称的 catalog properties文件,例如etc/catalog/s3.properties、etc/catalog/gcs.properties,etc/catalog/minio.properties等,或者甚至只是etc/catalog/hdfs.properties属性。 在下面,我们假设使用etc/catalog/hive.properties。 至少,您需要为HMS配置连接器名称和URL:
connector.name=hive-hadoop2
hive.metastore.uri=thrift://example.net:9083
许多其他配置属性适用于不同的用例,其中一些您很快就会了解更多。 当有疑问时,一定要检查文档;请参阅“文档第13页。 让我们接下来讨论一些细节。
Hive-Style Table Format
一旦配置了连接器,您就可以从Presto,例如,在HDFS中创建一个模式:
CREATE SCHEMA hive.web
WITH (location = 'hdfs://starburst-oreilly/web')
模式有时仍然称为数据库,可以包含多个表。 您可以在下一节中阅读更多关于它们的内容。 模式创建通常只创建有关模式的元数据在HMS中:
..
hdfs://starburst-oreilly/web/customers
hdfs://starburst-oreilly/web/clicks
hdfs://starburst-oreilly/web/sessions
...
```sql
Using Amazon S3 is not much different. You just use a different protocol string:
CREATE SCHEMA hive.web
WITH (location = 's3://example-org/web')
...
s3://example-org/web/customers
s3://example-org/web/clicks
s3://example-org/web/sessions
...
Managed and External Tables
在schema之后,我们需要了解更多有关schema中内容的信息组织为表。Hive区分管理表(又叫托管表)和外部表。管理表由Hive管理,因此也可能由Presto管理,并创建以及其在数据库目录位置下的数据。外部表不受Hive管理,并显式指向Hive管理的目录之外的另一个位置。
管理表和外部表之间的主要区别在于Hive,因此Presto拥有管理表中的数据。如果您删除托管表,HMS中的元数据和数据将被删除。如果删除外部表,则数据保留,并且仅删除有关表的元数据。
您使用的表的类型实际上取决于计划使用Presto的方式。你可能正在使用Presto进行数据联合,您的数据仓库或数据湖,或者两者都使用,或者其他混合。您需要确定谁拥有数据。可能是Presto工作使用HMS,也可以是Hadoop和HMS,Spark或ETL中的其他工具管道。在所有情况下,元数据都在HMS中进行管理。关于哪个系统拥有并管理HMS和数据的决定通常是根据您的数据架构。在Presto的早期使用案例中,Hadoop通常会跟踪数据生命周期。但是随着越来越多的用例将Presto用作核心工具,许多用户改变其模式,Presto接管了控制权。
一些新的Presto用户从查询现有的Hadoop部署开始。在这个在这种情况下,它开始于更多的数据联合使用,而Hadoop拥有该数据。你然后配置Hive连接器以将Hadoop中的现有表暴露给Presto用于查询。您使用外部表,通常在这种情况下,您不能允许Presto写入这些表。
其他Presto用户可能会开始从Hadoop迁移并完全迁移到Presto,否则它们可能会从另一个对象存储系统(特别是通常是一个基于云的系统。在这种情况下,最好开始创建数据定义局域网通过Presto进行数据管理(DDL),让Presto拥有数据。
让我们考虑一下Presto表的以下DDL:
CREATE TABLE hive.web.page_views (
view_time timestamp,
user_id bigint,
page_url varchar,
view_date date,
country varchar
)
在此示例中,表page_views将数据存储在一个目录下,该目录也名为page_views。 page_views目录是该目录下的子目录由hive.metastore.warehouse.dir定义,如果已定义,则为其他目录创建架构时的架构位置。这是一个HDFS示例:hdfs:/ user / hive / warehouse / web / page_views / ...
这是一个Amazon S3示例:s3:// example-org / web / page_views / ...
接下来,让我们考虑一个指向现有数据的Presto表的DDL。该数据是通过其他方式(例如Spark或ETL流程)创建和管理数据落地在存储中。在这种情况下,您可以通过Presto创建一个外部表指向此数据的外部位置:
CREATE TABLE hive.web.page_views (
view_time timestamp,
user_id bigint,
page_url varchar,
view_date date,
country varchar
)
WITH (
external_location = 's3://starburst-external/page_views'
)
这会将有关表的元数据插入到HMS中,包括外部路径以及一个向Presto和HMS发出信号的标志,表明该表是外部表,因此需要操作被另一个系统管理。
结果,位于s3:// example-org / page_views中的数据可能已经存在。一旦该表在Presto中创建,您可以开始查询它。当您配置HIve 连接器到现有的Hive仓库,您将看到现有的表格,并能够立即从他们那里查询。或者,您可以在一个空目录中创建表,并期望数据能够稍后由Presto或外部来源加载。无论哪种情况,Presto期望目录结构已经创建;否则,DDL错误。这创建外部表的最常见情况是与其他人共享数据时工具。
Partitioned Data
到目前为止,您已经了解了表的数据(无论是托管数据还是外部数据)如何作为一个或多个文件存储在目录中。数据分区是对此的扩展,并且是一种用于将逻辑表水平划分为较小数据的技术称为分区。该概念本身源自RDBMS中的分区方案。HIve介绍这种用于HDFS中数据的技术,是获得更好查询性能和数据的可管理性的一种方法。现在,分区是分布式文件系统中的标准数据组织策略,(例如HDFS)和对象存储(例如S3)中。让我们使用此表示例演示分区:
CREATE TABLE hive.web.page_views (
view_time timestamp,
user_id bigint,
page_url varchar,
view_date date
)
WITH (
partitioned_by = ARRAY['view_date']
)
- 在 partitioned_by 语句中列出的列必须是最后一列DDL中定义的列。否则,您会收到错误消息。
与非分区表一样,page_views表的数据位于…/page_views。使用分区会更改表布局的结构方式。和在分区表中,在表子目录中添加了其他子目录。在以下示例中,您将看到分区按键定义的目录结构:
...
.../page_views/view_date=2019-01-14/...
.../page_views/view_date=2019-01-15/...
.../page_views/view_date=2019-01-16/...
...
Presto使用相同的Hive样式表格式。此外,您可以选择分区在多列上:
CREATE TABLE hive.web.page_views (
view_time timestamp,
user_id bigint,
page_url varchar,
view_date date,
country varchar
)
WITH (
partitioned_by = ARRAY['view_date', 'country']
)
选择多个分区列时,Presto将创建一个分层目录结构体:
..
.../page_views/view_date=2019-01-15/country=US…
.../page_views/view_date=2019-01-15/country=PL…
.../page_views/view_date=2019-01-15/country=UA...
.../page_views/view_date=2019-01-16/country=US…
.../page_views/view_date=2019-01-17/country=AR...
...
分区可以提高查询性能,尤其是随着数据的增长尺寸。例如,让我们进行以下查询:
SELECT DISTINCT user_id
FROM page_views
WHERE view_date = DATE '2019-01-15' AND country = 'US';
提交此查询后,Presto会识别WHERE中的分区列子句,并使用关联的值仅读取view_date = 2019-01-15 / country = US子目录。通过仅读取所需的分区,可能会获得较大的性能可以节省大量人力。如果您今天的数据很小,则性能提升可能不会引人注目。但是,随着数据的增长,性能的提高非常重要。
Loading Data
加载数据。中到目前为止,您已经了解了Hive样式的表格格式,包括分区数据。您如何将数据放入表中?这实际上取决于谁拥有数据。让我们首先假设您要在Presto中创建表并加载Presto的数据:
CREATE TABLE hive.web.page_views (
view_time timestamp,
user_id bigint,
page_url varchar,
view_date date,
country varchar
)
WITH (
partitioned_by = ARRAY['view_date', 'country']
)
要通过Presto加载数据,Presto支持INSERT INTO ... VALUES,INSERT INTO...SELECT和CREATE TABLE AS SELECT。 尽管INSERT INTO存在使用局限,因为它为每个语句创建单个文件和单个行。 通常对在学习Presto时使用。INSERT SELECT和CREATE TABLE AS执行相同的功能。哪一个你使用与否取决于要加载到现有表中还是将表创建并同时加载。以您可能要查询的INSERT SELECT为例,从一个非分区的外部表查询数据,并加载到Presto中的分区表中:
presto:web> INSERT INTO page_views_ext SELECT * FROM page_views;
INSERT: 16 rows
前面示例显示向外部表中插入新数据。默认情况下,Presto禁止写入外部表。到要启用它,您需要在目录配置文件中将hive.non-managed-table-writes-enabled 设置为true。如果您熟悉Hive,Presto会执行所谓的动态分区:分区目录结构是在Presto首次检测到分区列时创建的。
您也可以在Presto中创建一个外部分区表。一个目录结构S3中的数据如下:
s3://example-org/page_views/view_date=2019-01-14/...
s3://example-org/page_views/view_date=2019-01-15/...
s3://example-org/page_views/view_date=2019-01-16/...
我们创建外部表定义:
CREATE TABLE hive.web.page_views (
view_time timestamp,
user_id bigint,
page_url varchar,
view_date date
)
WITH (
partitioned_by = ARRAY['view_date']
)
Now let’s query from it:
presto:web> SELECT * FROM page_views;
view_time | user_id | page_url | view_date
-----------+---------+----------+-----------
(0 rows)
发生了什么?即使我们知道其中包含数据,HMS仍无法识别分区。如果您熟悉Hive,就会了解MSCK REPAIR TABLE命令自动发现所有分区。幸运的是,Presto有自己的以及自动发现和添加分区的命令:
CALL system.sync_partition_metadata(
'web',
'page_views',
‘FULL’
)
...
Now that you have added the partitions, let’s try again:
presto:web> SELECT * FROM page_views;
view_time | user_id | page_url | view_date
-------------------------+---------+----------+------------
2019-01-25 02:39:09.987 | 123 | ... | 2019-01-14
...
2019-01-25 02:39:11.807 | 123 | ... | 2019-01-15
...
另外,Presto提供了手动创建分区的功能。这经常麻烦,因为您必须使用命令来定义每个分区分别地:
CALL system.create_empty_partition[w][x](
'web',
'page_views',
ARRAY['view_date'],
ARRAY['2019-01-14']
)
...
当您要在外部创建分区时,通过ETL流程添加空分区非常有用,然后暴露给Presto。Presto还仅通过指定partition列即可支持删除分区DELETE语句的WHERE子句中的值。在此示例中,数据保持不变完整无缺,因为它是一个外部表:
DELETE FROM hive.web.page_views
WHERE view_date = DATE '2019-01-14'
需要强调的是,您不必管理表和数据使用Presto,但如果需要的话,也可以。许多用户利用Hive或其他工具来创建和操作数据,并且仅使用Presto来查询数据。
File Formats and Compression 文件格式和压缩
Presto支持Hadoop / HDFS中使用的许多常见文件格式,包括以下:
• ORC
• PARQUET
• AVRO
• JSON
• TEXTFILE
• RCTEXT
• RCBINARY
• CSV
• SEQUENCEFILE
Presto使用的三种最常见的文件格式是ORC,Parquet和Avro数据文件。 ORC,Parquet,RC Text和RC Binary格式的阅读器经过严格优化,在Presto中进行了改进以提高性能。HMS中的元数据包含文件格式信息,因此Presto知道什么读取数据文件时使用的读取器。在Presto中创建表格时,默认数据类型设置为ORC。但是,可以在CREATE TABLE中覆盖默认值语句作为WITH属性的一部分:
CREATE TABLE hive.web.page_views (
view_time timestamp,
user_id bigint,
page_url varchar,
ds_date,
country varchar
)
WITH (
format = 'ORC'
)
可以使用以下命令设置目录中所有表的默认存储格式。目录属性文件中的hive.storage-format配置。默认情况下,Presto使用GZIP压缩编解码器写入文件。你可以通过设置hive.compression-codec 将代码更改为使用SNAPPY或NONEcatalog属性文件中的配置。
Non-Relational Data Sources
非关系数据源Presto包含用于查询非关系数据源的变体的连接器。这些数据源通常被称为NoSQL系统,可以是键值存储,列存储,流处理系统,文档存储和其他系统。
其中一些数据源提供类似SQL的查询语言,例如CQL阿帕奇·卡桑德拉(Apache Cassandra)。其他仅提供特定的工具或API来访问数据或包括完全不同的查询语言,例如“查询域特定的语言”Elasticsearch中使用的语言。这些语言的完整性常常受到限制,并且不规范。这些NoSQL数据源的Presto连接器允许您运行SQL查询这些系统就像是关系系统一样。这使您可以使用诸如BI工具或允许那些了解SQL的人查询这些数据源。这些数据源包括使用联接,聚合,子查询和其他高级SQL功能。
在下一章中,您将了解有关这些连接器的更多信息:
- NoSQL系统,例如Elasticsearch或MongoDB-“文档存储连接器示例:Elasticsearch”(第120页)
- 流媒体系统,例如Apache Kafka-“流媒体系统连接器考试-ple:Kafka”(第118页)
- 诸如Apache Accumulo之类的键值存储系统-“键值存储连接器”示例:第110页的Accumulo”和Apache Cassandra“ Apache Cassandra”连接器”(第117页)
- 具有Apache Phoenix连接器的Apache HBase-“通过以下方式连接到HBase:Phoenix”,第109页让我们暂时跳过这些,并讨论一些更简单的连接器和相关的方面优先。
Presto JMX连接器
可以轻松地配置JMX连接器以在目录属性文件等中使用,catalog/jmx.properties:connector.name = jmx
暴露有关运行coordinator and workers在Presto的JVM的运行时信息。它使用Java管理扩展( Java Management Extensions ——JMX)并允许您在Presto中使用SQL访问可用信息,对于监视和故障排除特别有用。连接器暴露了历史模式,历史数据,汇总数据,当前具有用于元数据最新信息的schema。了解更多信息的最简单方法是使用Presto语句调查可用的表格:从jmx.current显示表;
SHOW TABLES FROM jmx.current;
Table
------------------------------------------------------------------
com.sun.management:type=diagnosticcommand
com.sun.management:type=hotspotdiagnostic
io.airlift.discovery.client:name=announcer
io.airlift.discovery.client:name=serviceinventory
io.airlift.discovery.store:name=dynamic,type=distributedstore
io.airlift.discovery.store:name=dynamic,type=httpremotestore
....
如您所见,表名称使用Java类路径作为发出类的指标和参数。这意味着在引用表时需要使用引号SQL语句中的名称。通常,找出可用的颜色很有用表格中的数字:
DESCRIBE jmx.current."java.lang:type=runtime";
Column | Type | Extra | Comment
------------------------+---------+-------+---------
bootclasspath | varchar | | bootclasspathsupported | boolean | |
classpath | varchar | |
inputarguments | varchar | |
librarypath | varchar | |
managementspecversion | varchar | |
name | varchar | |
objectname | varchar | |
specname | varchar | |
specvendor | varchar | |
specversion | varchar | |
starttime | bigint | |
systemproperties | varchar | |
uptime | bigint | |
vmname | varchar | |
vmvendor | varchar | |
vmversion | varchar | |
node | varchar | |
object_name | varchar | |
(19 rows)
This allows you to get information nicely formatted:
SELECT vmname, uptime, node FROM jmx.current."java.lang:type=runtime";
vmname | uptime | node
--------------------------+---------+--------------
OpenJDK 64-Bit Server VM | 1579140 | ffffffff-ffff
(1 row)
请注意,此查询仅返回一个节点,因为这是一个简单的安装单个协调器/工作程序节点的地址,如第2章所述。JMX连接器通常公开许多有关JVM的信息,包括作为Presto的特定方面。您可以通过以下方式开始探索可用信息:从presto开始在桌子上;例如,使用DESCRIBE jmx.current.“presto.execution:name=queryexecution”。以下是一些值得一试的describe语句:
DESCRIBE jmx.current."presto.execution:name=querymanager";
DESCRIBE jmx.current."presto.memory:name=clustermemorymanager";
DESCRIBE jmx.current."presto.failuredetector:name=heartbeatfailuredetector";
要了解有关使用Web UI和其他相关信息监视Presto的更多信息编方面,您可以转到第12章。
Black Hole Connector
黑洞连接器可以轻松配置为在目录属性文件中使用例如etc/catalog/blackhole.properties:connector.name =blackhole它充当任何数据的接收器,类似于Unix操作系统中的空设备,/dev/null。这使您可以将其用作任何从其他目录插入查询读取的目标。由于它实际上并没有写任何东西,因此您可以使用它来从这些目录中衡量读性能。例如,您可以在黑洞中创建测试架构,然后通过tpch.tiny数据集。然后,您从tpch.sf3数据中读取数据集并将其插入黑洞目录:
CREATE SCHEMA blackhole.test;
CREATE TABLE blackhole.test.orders AS SELECT * from tpch.tiny.orders;
INSERT INTO blackhole.test.orders SELECT * FROM tpch.sf3.orders;
此操作从本质上衡量了tpch目录的读取性能,因为它会读取150万个订单记录,然后将它们发送到黑洞。使用其他方式像tcph.sf100这样的mas会增加数据集的大小。这使您可以评估性能您的Presto部署方式。
连接器带有RDBMS,对象存储或键值存储目录的类似查询可以是有助于查询开发以及性能测试和改进。
Memory Connector
可以将内存连接器配置为在目录属性文件中使用。为了例如etc / catalog / memory.properties:connector.name =memory。您可以像临时数据库一样使用内存连接器。所有数据都存储在群集中的内存。停止群集会破坏数据。当然,你也可以灵活使用SQL语句删除表中的数据甚至一起删除表。使用内存连接器对于测试查询或临时存储很有用。为了例如,我们将其用作需要外部数据的简单替代使用Iris数据集时配置的源;请参阅第15页的“虹膜数据集”。
- 虽然对于测试和小型任务很有用,但内存连接器是不适合大数据集和生产用途,尤其是当分布在整个集群中时。例如,数据可能是分布在不同的工作程序节点上,并且工作程序崩溃导致该数据丢失。内存连接器仅用于临时数据。
其他连接器
如您所知,Presto项目包含许多连接器,但有时您最终导致您只需要为该特定接口再增加一个连接器的情况数据源。好消息是您没有被困住。 Presto团队以及更大的Presto公司社区,正在不断扩展可用连接器的列表,所以到您阅读这本书,清单可能比现在更长。还可以从Presto项目本身之外的各方获得连接器。这包括Presto的其他社区成员和用户,他们编写了自己的con-且尚未将其归还,或由于某种原因而无法做出贡献的人或其他。数据库系统的商业供应商也提供连接器,因此请确定您要查询的系统的所有者或创建者是一个好主意。和Presto社区包括商业供应商,例如Starburst,它们捆绑在一起具有支持和扩展功能的Presto,包括附加或改进的连接器。最后但并非最不重要的一点是,您必须牢记Presto是一个热情的社区围绕开源项目。因此,您可以(并鼓励)查看代码现有连接器,并根据需要创建新的连接器。理想情况下,您可以甚至与项目一起工作,并为该项目贡献一个连接器,以实现简单的维护和使用。
结论
现在,您更多地了解了Presto访问各种数据的功能资料来源。无论您访问哪种数据源,Presto都可将数据提供给您可以使用SQL和基于SQL的工具进行查询。特别是,您了解了至关重要的Hive连接器,用于查询分布式存储(例如HDFS或云)存储系统。在下一章的第7章中,您可以了解有关很少有其他被广泛使用的连接器。有关所有连接器的详细文档,请访问Presto网站。看第12页上的“网站”。如果找不到所需的内容,您甚至可以与社区合作创建您自己的连接器或增强现有的连接器连接器
CHAPTER 7 高级连接器
示例现在您知道了Presto提供了哪些功能连接器以及如何进行配置从第6章开始。让我们将该知识扩展到更复杂的一些知识中。使用方案和连接器。这些通常是需要聪明的连接器足以转换来自底层数据源的存储模式和想法,很难从SQL和Presto映射到面向表的模型。通过直接跳到有关您要连接的系统的部分来了解更多信息。使用Presto并使用SQL查询:
- 第109页的“使用Phoenix连接到HBase”- 第110页上的“键值存储连接器示例:Accumulo”
- 第117页上的“ Apache Cassandra连接器”- 第118页上的“流系统连接器示例:Kafka”
- 第120页上的“文档存储连接器示例:Elasticsearch”使用这些连接器后,您可以通过了解以下内容来完善自己的理解页面上的“ Presto中的查询联合”中的查询联合以及相关的ETL用法122。
通过Phoenix连接到HBase分布式
可伸缩的大数据存储Apache HBase构建在HDFS之上。用户数但是,不限于使用低级HDFS并通过Hive connector访问它。 Apache Phoenix项目提供了一个用于访问HBase的SQL层,感谢Presto Phoenix连接器,因此您可以从Presto以下位置访问HBase数据库就像任何其他数据源一样。像往常一样,您只需要一个目录文件,例如etc / catalog / bigtables.properties:
connector.name=phoenix
phoenix.connection-url=jdbc:phoenix:zookeeper1,zookeeper2:2181:/hbase
连接URL是数据库的JDBC连接字符串。它包括一系列Apache ZooKeeper节点,用于发现HBase节点。Phoenix模式和表已映射到Presto模式和表,您可以使用常规的Presto语句检查它们:
SHOW SCHEMAS FROM bigtable;
SHOW TABLES FROM bigtable.example;
SHOW COLUMNS FROM bigtable.examples.user;
现在您可以查询任何HBase表并在下游工具中使用它们了,就像连接到Presto的任何其他数据源中的数据一样。使用Presto,您可以使用水平伸缩性能优势查询HBase。按比例缩放Presto。您创建的任何查询都可以访问HBase和任何其他目录日志,使您可以将HBase数据与其他来源合并到联合查询中。
Key-Value Store Connector Example: Accumulo
键值存储连接器示例:Accumulo
Presto包括用于多个键值数据存储的连接器。键值存储是一个系统用于管理通过使用唯一键存储和检索的记录的字典的方法。想象一下一个哈希表,其中的键是通过它检索记录的。该记录可能是一个值,多个值,甚至一个集合。
存在几种具有一系列功能的键值存储系统。一个广泛使用的系统是开放源代码——宽列存储数据库Apache Cassandra,用于可用的Presto连接器。您可以在“ Apache Cas‐sandra连接器”(第117页)。
我们现在将更详细讨论的另一个示例是Apache Accumulo。这是一个高度高性能,广泛使用的开源键值存储,可以通过以下方式查询Presto连接器。一般概念可以转换为其他键值存储。受Google BigTable启发,Apache Accumulo是一种经过排序的分布式键值存储以进行可伸缩的存储和检索。 Accumulo将键值数据存储在HDFS上-钥匙。
图7-1显示了Accumulo中的键如何由行ID,列和行时间戳的三元组组成。关键字首先按关键字排序,和字典序排序,然后按时间戳降序排列。

图7-1 Accumulo中的键值对Accumulo可以通过使用列簇column families和locality groups组进一步优化。大多数操作对Presto都是透明的,但是知道您的SQL的访问模式查询可以帮助您优化Accumulo表的创建。这等同于使用Accumulo为其他任何应用程序优化表格。让我们看一下表7-1中关系表的逻辑表示。
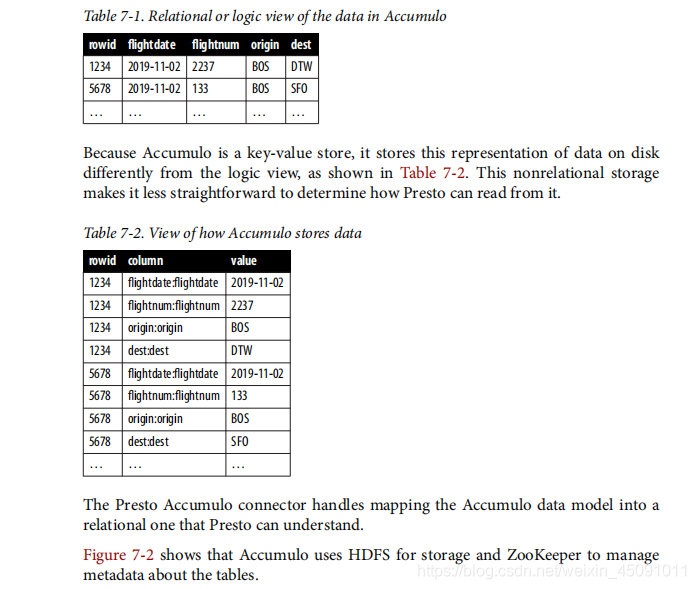
由于Accumulo是键值存储,因此它将这种数据表示形式存储在磁盘上与逻辑视图不同,如表7-2所示。这种非关系存储使确定Presto如何从中读取内容变得不那么直接。Presto Accumulo连接器可将Accumulo数据模型映射到Presto可以理解的关系型。图7-2显示Accumulo使用HDFS进行存储,使用ZooKeeper进行操作年龄有关表的元数据。
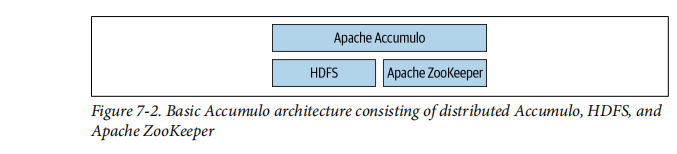
基本的Accumulo体系结构,由分布式Accumulo,HDFS和ZooKeeperAccumulo的核心是一个分布式系统,它由一个主节点和多个服务器。
如图7-3所示。服务器服务包含并暴露服务器,它们是表的水平分区。客户端直接连接到服务器扫描所需的数据。
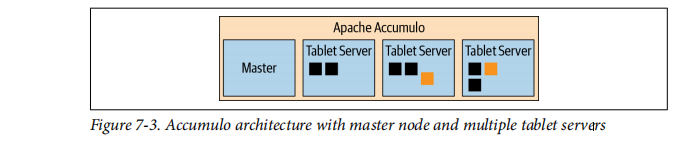
图7-3。具有主节点和多个服务器的Accumulo体系结构就像Accumulo本身一样,Presto Accumulo连接器也使用ZooKeeper。它读全部表中的信息,例如表,视图,表属性和列定义Accumulo使用的ZooKeeper实例。
让我们看一下如何从Presto的Accumulo中扫描数据。在Accumulo中,密钥对可以通过使用Scanner对象从表中读取。Scanner开始在特定键处读取该表并终止,并在另一个键处或表末尾终止。这可以将Scanner配置为仅读取所需的确切列。召回RDBMS连接器,仅将所需的列添加到SQL查询生成器中推入数据库。Accumulo还具有BatchScanner对象的概念。在阅读时使用来自Accumulo的多个范围。因为它可以使用,所以效率更高多名worker与Accumulo进行通信。
如图7-4所示。用户首先将查询提交给协调点,然后协调点通信Accumulo来从元数据确定splits。它通过从Accumulo中的可用索引中查找范围决定splits。 Accumulo从索引返回行ID,Presto将这些范围存储在splits中。如果无法使用索引,单个节点的所有范围均使用一个splits。最后,工作人员使用该信息连接到特定的服务器,并拉出来自Accumulo的并行数据。这将通过使用BatchScanner从Accumulo并行拉数据。
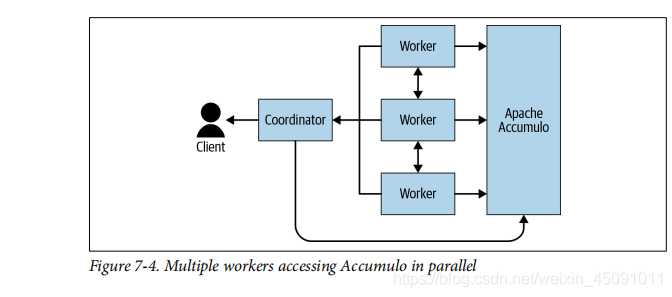 多名worker并行访问Accumulo。一旦从worker拉取数据后,数据将以关系格式放入Presto,其余的处理由Presto完成。在这种情况下,将Accumulo用于数据存储。 Presto提供了更高级别的SQL接口,用于访问Accumulo中的数据。如果您自己编写应用程序是为了从Accumulo中检索数据,您将编写类似于以下Java代码段的内容。您设置范围进行扫描并定义要提取的列:
多名worker并行访问Accumulo。一旦从worker拉取数据后,数据将以关系格式放入Presto,其余的处理由Presto完成。在这种情况下,将Accumulo用于数据存储。 Presto提供了更高级别的SQL接口,用于访问Accumulo中的数据。如果您自己编写应用程序是为了从Accumulo中检索数据,您将编写类似于以下Java代码段的内容。您设置范围进行扫描并定义要提取的列:
ArrayList<Range> ranges = new ArrayList<Range>();
ranges.add(new Range("1234"));
ranges.add(new Range("5678"));
BatchScanner scanner = client.createBatchScanner("flights", auths, 10);
scanner.setRangers(ranges);
scanner.fetchColumn("flightdate");
scanner.fetchColumn("flightnum");
scanner.fetchColumn("origin");
for (Entry<Key,Value> entry : scanner) {
// populate into Presto format
}
}
不需要读取的列修剪的概念类似于RDBMS连接器。 Accumulo连接器不使用下推SQL,而是使用Accumulo API设置要提取的列。使用Presto Accumulo连接器要使用Accumulo,请创建目录属性文件(例如**etc / catalog / accumulo.properties**)引用Accumulo连接器并配置包括与ZooKeeper的连接:
connector.name=accumulo
accumulo.instance=accumulo
accumulo.zookeepers=zookeeper.example.com:2181
accumulo.username=user
accumulo.password=password
使用之前的 flights示例,让我们在Accumulo中使用Presto创建一个表格,使用Presto CLI或通过JDBC连接到Presto的RDBMS管理工具:
CREATE TABLE accumulo.ontime.flights (
rowid VARCHAR,
flightdate VARCHAR,
flightnum, INTEGER,
origin VARCHAR
dest VARCHAR
);
在Presto中创建此表时,连接器实际上在accumulo中创建表和ZooKeeper中有关表的元数据。也可以创建列族。 Accumulo中的列族是一种优化用于同时访问列的应用程序的混合器。通过定义列族,Accumulo安排如何将列存储在磁盘上,将经常访问的列(作为列族的一部分)存储在一起以便访问。如果要创建表使用列族,您可以将其指定为表属性,在WITH中指定陈述:
CREATE TABLE accumulo.ontime.flights (
rowid VARCHAR,
flightdate VARCHAR,
flightnum, INTEGER,
origin VARCHAR
dest VARCHAR
)
WITH
column_mapping = 'origin:location:origin,dest:location:dest'
);
通过使用column_mapping,您可以使用限定词origin和dest定义列族位置,与Presto列名称相同。
- 当不使用column_mapping表属性时,Presto自动生成相同的列族和列限定符名称作为Presto列名称。您可以观察Accumulo通过在表中运行DESCRIBE获得列族和列限定符命令。
Presto Accumulo connector 支持INSERT语句:
INSERT INTO accumulo.ontime.flights VALUES
(2232, '2019-10-19', 118, 'JFK', 'SFO');
这是插入数据的便捷方法。但是,当数据从Presto写入Accumulo。为了获得更好的性能,您需要使用本地Accumulo API。 Accumulo连接器在Presto外部具有实用程序,可用于协助提高插入数据的性能。您可以找到更多信息有关使用Presto文档中的单独工具加载数据的信息。
我们在前面的示例中创建的表是一个内部表。 Presto Accumulo连接器支持内部和外部表。唯一的区别类型之间的区别是,删除外部表只会删除元数据,而不是数据本身。外部表允许您创建已经存在的Presto表在Accumulo中。此外,如果您需要更改schema ,例如添加column,您可以简单地删除表并在Presto中重新创建它,而不会丢失数据。值得注意的是,当每一行时,Accumulo都可以支持这种架构演变不需要具有相同的列集。
使用外部表需要做更多的工作,因为数据已经存储在专门方式中。例如,在以下情况下必须使用column_mapping表属性使用外部表。
CREATE TABLE accumulo.ontime.flights (
rowid VARCHAR,
flightdate VARCHAR,
flightnum, INTEGER,
origin VARCHAR
dest VARCHAR
)
WITH
external = true,
column_mapping = 'origin:location:origin,dest:location:dest'
);
Accumulo中的谓词下推
在Accumulo连接器中,Presto可以利用内置的二级索引在Accumulo中。为此,Accumulo连接器需要自定义服务器端每个Accumulo平板电脑服务器上的迭代器。迭代器作为JAR文件分发,您必须将其复制到每个平板电脑服务器上的$ ACCUMULO_HOME / lib / ext中。你可以在Presto文档中找到有关执行此操作的确切详细信息。Accumulo中的索引用于查找行ID。这些可以用来阅读实际表中的值。让我们看一个例子:键值存储连接器示例:
没有索引,Presto将从Accumulo中读取整个数据集,然后对其进行过滤在Presto中。工人们得到的拆分包含要读取的Accumulo范围。这range是平板电脑的整个范围。有索引的地方,例如示例索引在表7-3中,可以显着减少要处理的范围数。表7-3。排期表上的索引示例
协调器使用WHERE子句过滤Flightdate BETWEEN DATE’2019-10-01’AND 2019-11-05’AND origin ='BOS’扫描索引以获取表的行ID。然后将行ID打包到worker的拆分中以后用于访问Accumulo中的数据。在我们的示例中,我们有二级索引关于航班日期和出发地,我们收集了行ID {2232、1234、5478}和{3498,1234,5678}。我们从每个索引取交集,并知道我们只需扫描行ID {1234,5678}。然后将此范围放入拆分中由工人进行处理,可以直接访问各个值,如表7-4中的数据的详细视图。表7-4。详细信息视图,其中包含原始值,目标值和其他值的各个值列编号值2232€建议日期:
要利用谓词下推,我们需要在列上有索引我们想要下推谓词。通过Presto连接器在索引栏上索引使用index_columns表属性可以轻松启用umns:创建表accumulo.ontime.flights( rowid VARCHAR, 排期VARCHAR, flightnum,INTEGER, 起源VARCHAR dest VARCHAR)和 index_columns =‘flightdate,origin’);在关于Apache Accumulo的这一部分中,您了解了键值存储以及如何Presto可用于通过标准SQL查询它。
Apache Cassandra
让我们来看看另一种更广泛的可以从Presto中受益的系统:Apache Cassandra。Apache Cassandra连接器Apache Cassandra是支持大量数据的分布式,宽列存储数据的。其容错架构和线性可扩展性导致了广泛的应用卡桑德拉(Cassandra)在Cassandra中处理数据的典型方法是使用自定义查询为Cassandra创建的语言:Cassandra查询语言(CQL)。当CQL开启时表面看起来很像SQL,实际上错过了许多有用的功能SQL,例如联接。总体而言,与使用标准工具进行依靠SQL不可能。Apache Cassandra连接器| 117但是,通过使用Cassandra连接器,您可以允许对数据进行SQL查询在卡桑德拉。最少的配置是一个简单的目录文件,例如etc / catalog / sitedata用于跟踪网站上所有用户互动的Cassandra集群,例如:
通过此简单配置,用户可以查询Cassandra中的数据。任何Cassandra中的键空间(例如cart)在Presto中作为模式公开,并且现在可以使用普通SQL查询诸如用户之类的表:选择* FROM sitedata.cart.users;该连接器支持众多配置属性,可让您适应目录到您的Cassandra群集中,为连接启用身份验证和TLS等等。流系统连接器示例:Kafka流媒体系统和发布-订阅(pub / sub)系统专为han‐实时数据提要。例如,Apache Kafka被创建为LinkedIn上的高吞吐量和低延迟平台。发布者向Kafka写消息供订户消费。这样的系统通常对数据管道很有用系统之间。 Presto Kafka连接器用于从Kafka读取数据。曲线完全不能使用连接器发布数据。使用连接器,您可以使用SQL查询有关Kafka主题的数据,甚至可以将其加入与其他数据。 Presto的典型使用案例是实时Kafka的临时查询主题流以检查并更好地了解当前状态和数据流通过系统。使用Presto可以使数据分析变得更加轻松和方便通常没有任何特定Kafka知识但确实有知道如何编写SQL查询。带有Kafka的Presto另一个不太常见的用例是从卡夫卡使用CREATE TABLE AS或INSERT SELECT语句,您可以读取数据在Kafka主题中,使用SQL转换数据,然后将其写入HDFS,S3或其他存储。由于Kafka是流式系统,因此公开的主题会不断更改其内容当有新数据输入时。查询Kafka主题时必须考虑到这一点与Presto。使用Presto将数据迁移到HDFS或其他数据具有永久存储功能的基本系统使您可以保留传递的信息通过您的Kafka主题。一旦数据在目标数据库或存储中永久可用,Presto即可用于将其暴露给诸如Apache Superset之类的分析工具;请参见“查询,可视化第229页上的“更多信息,以及Apache Superset的更多信息”。118 |第7章:高级连接器示例使用Kafka连接器的工作方式与其他任何连接器一样。创建目录(用于例如使用Kafka连接器config-的etc / catalog / trafficstream.properties)确定所有其他必需的详细信息,然后指向您的Kafka集群:
现在,Kafka web.pages和web.users中的每个主题都可以作为表格在普雷斯托。在任何时候,该表都会以所有消息显示整个Kafka主题。在这个话题上很少。主题中的每个消息在Presto表中显示为一行。现在,可以通过Presto上的SQL查询,使用目录,架构,和表名:选择* FROM trafficstream.web.pages;选择* FROM trafficstream.web.users;本质上,您可以通过简单的方式实时直播Kafka主题,SQL查询。如果要将数据迁移到另一个系统(例如HDFS目录),则可以从简单的CREATE TABLE AS(CTAS)查询开始:
该表存在后,您可以通过运行插入查询将更多数据插入其中经常:插入hdfs.web.pages选择
*来自trafficstream.web.pages;为避免重复复制,您可以跟踪一些内部列连接器裸露的卡夫卡。具体来说,y您可以使用_partition_id,_partition_offset,_segment_start,_segment_end和_segment_count。规格用于定期运行查询的特定设置取决于您的Kafka配置用于删除消息以及用于运行查询的工具,例如Apache气流,在第231页上的“使用Apache Airflow进行的工作流”中进行了描述。Kafka主题的映射(包含在表中)及其包含的内容消息,可以为位于etc / kafka /中的每个主题定义一个JSON文件schema.tablename.json。对于前面的示例,您可以在以下位置定义映射等/kafka/web.pages.json。流系统连接器示例:Kafka | 119主题中的Kafka消息使用不同的格式,并且Kafka连接器包括最常用格式的解码器,包括Raw,JSON,CSV和阿夫罗配置属性,映射和其他内部的详细信息列可在Presto文档中找到;请参阅第13页“文档”。将Presto与Kafka一起使用将为流数据打开新的分析和见解通过Kafka,定义了Presto的另一种有价值的用法。另一个流处理-Presto支持的类似用途的系统是Amazon Kinesis。
文档存储连接器示例:ElasticsearchPresto包含用于知名文档存储系统的连接器,例如Elastic-搜索或MongoDB。这些系统支持信息的存储和检索。类似于JSON的文档。 Elasticsearch更适合于索引和搜索文档ments。 MongoDB是通用文档存储。概述Presto连接器允许用户使用SQL访问这些系统并查询数据即使它们不存在本机SQL访问,也无法访问它们。Elasticsearch集群通常用于存储日志数据或其他事件流,以用于长期甚至永久存储。这些数据集通常非常大,而且可以作为有用的资源,用于更好地了解在其中发出日志数据的系统操作和各种情况下。Elasticsearch和Presto是强大而高效的组合,因为这两个系统项目可以水平缩放。 Presto通过分解查询并运行其中的部分来进行扩展它遍布集群中的许多工作人员。Elasticsearch通常在自己的集群上运行,并且也可以水平扩展。它可以在多个节点上分片索引,并在分布式系统中运行任何搜索操作方式。调整Elasticsearch集群的性能是一个单独的主题,需要了解搜索索引中的文档数,即集群中的节点ber,副本集,分片配置及其他细节。但是,从客户的角度来看,因此从Presto的角度来看,这是完全透明的,Elasticsearch只是使用URL的URL公开集群。Elasticsearch服务器。
配置
配置Presto以访问Elasticsearch是通过创建目录来执行的文件,例如etc / catalog / search.properties:connector.name =弹性搜索elasticsearch.host = searchcluster.example.com此配置依赖于端口,架构和其他详细信息的默认值,但足以查询集群。该连接器支持大量数据开箱即用提供来自Elasticsearch的各种类型。它会自动分析每个索引,配置-确保每个表为一个表,以默认模式公开该表,创建必要的表嵌套的结构和行类型,并在Presto中公开它们。中的任何文档索引会自动解压缩到Presto中的表结构中。例如,在默认目录中,称为服务器的索引会自动以表格形式显示模式,您可以查询Presto以获取有关该结构的更多信息:描述search.default.server;用户可以立即开始查询索引。信息模式,或DESCRIBE命令,可用于了解为每个表创建的表和字段索引/模式。Elasticsearch模式中的字段通常包含多个值作为数组。如果自动检测的执行效果不理想,您可以添加字段属性defini-索引映射的位置。此外,_source隐藏字段包含来自Elasticsearch的原始文档,如果需要,您可以将函数用于JSON文档解析(请参见第183页的“ JSON函数”)和集合数据类型(请参见第149页的“集合数据类型”)。这些通常会有所帮助在Elasticsearch集群中使用文档时,这些文档是predomi‐JSON文档。在Elasticsearch中,您可以将来自一个或多个索引的数据作为别名公开。这也可以过滤数据。 Presto连接器支持别名用法并公开它们就像任何其他索引作为表一样。查询处理从Presto向Elasticsearch发出查询后,Presto实际上就可以利用除了已经集群的Elasticsearch之外,还包括其集群基础架构提高性能还有更多。Presto查询Elasticsearch以了解所有Elasticsearch分片。然后使用创建查询计划时,此信息。它将查询分为几个单独的部分针对特定的分片,然后将单独的查询发布给分片全部并行。结果返回后,将它们合并到Presto和
返回给用户。这意味着Presto与Elasticsearch结合可以使用用于查询的SQL并比Elasticsearch本身具有更高的性能。另请注意,这种与特定分片的单独连接在典型情况下也会发生Elasticsearch集群,其中该集群在负载均衡器后面运行,并且仅通过DNS主机名公开。全文搜索Elasticsearch连接器的另一个强大功能是对全文的支持搜索。它允许您在发出的SQL查询中使用Elasticsearch查询字符串来自Presto。例如,假设一个索引充满了网站上的博客文章。这些文件是存储在博客索引中。也许这些帖子包含许多领域,例如标题,简介,帖子,摘要和作者。通过全文搜索,您可以编写一个简单查询,可在所有字段中搜索整个内容以查找特定术语,例如预先:
Elasticsearch的查询字符串语法支持对不同的搜索词进行加权和其他适合全文搜索的功能。概括特定于Amazon Elasticsearch Service用户的另一个强大功能是支持AWS Identity and Access Management。查找有关此的更多详细信息配置以及使用TLS保护与Elasticsearch集群的连接和Presto文档中的其他技巧;请参阅第13页“文档”。将Presto与Elasticsearch结合使用可让您使用强大的SQL支持工具。您可以手动编写查询或进行连接丰富的分析工具。这使您比了解群集中的数据更好。以前可能的。当您将MongoDB连接到Presto时,具有类似的优势Presto MongoDB连接器的优势。Presto中的查询联合在第7页的“ Presto用例”中阅读了有关Presto的所有用例之后,然后了解Presto中的所有数据源和可用连接器后,您现在就可以准备在Presto中了解有关查询联合的更多信息。
Query Federation in Presto
联合查询是一个查询访问多个数据源中的数据。此查询可用于将来自多个RDBMS数据库,例如在其上运行的企业后端应用程序数据库PostgreSQL,带有在MySQL上的Web应用程序数据库。它也可能是数据仓库在PostgreSQL上查询来自源的数据,该数据源也在PostgreSQL中运行或其他地方。但是,当您合并来自具有针对其他非关系系统运行的查询的RDBMS。合并数据从数据仓库中获取对象存储中的信息,并填充数据从您的Web应用程序中大规模获取。或将数据与键值存储或NoSQL数据库中的内容相关联。您的对象存储数据湖可能突然变成通过SQL公开,这些信息可以成为更好理解的基础-查看您的整体数据。查询联合可以帮助您真正了解那些系统中的数据。在下面的示例中,您将了解在分布式数据库中联接数据的用例。将数据存储在关系数据库管理系统中。您可以找到信息第16页上的“飞行数据集”中有关必要设置的说明。有了这些数据,您可以提出以下问题:“飞机的平均延误时间是多少?按年?”通过使用SQL查询:
另一个问题是:“一周中最好的日子是从波士顿飞往波士顿?2月?”:
因为多个数据源和查询联合的概念是不可或缺的一部分Presto,我们鼓励您设置环境并探索数据。这些奇怪ies可以激发您自己创建其他查询的灵感。我们使用两个关于航空公司数据的分析查询示例来演示查询普雷斯托联邦。我们提供的设置使用存储在S3中的数据,并由使用Hive连接器配置Presto。但是,如果您愿意,可以存储HDFS,Azure存储或Google Cloud Storage中的数据,并使用Hive连接器查询数据。在第一个示例查询中,我们希望Presto返回前10名的航空公司来自HDFS中数据的最多航班:
虽然前面的查询向我们提供了前10名航空公司的搜索结果,最多的航班,它需要您了解uniquecarrier的价值。它会如果描述性更强的列提供了航空公司的完整名称,则更好的缩写。但是,我们要查询的航空公司数据源却没有包含此类信息。也许如果另一个包含该信息的数据源存在时,我们可以组合数据源以返回更可理解的结果。让我们看另一个例子。在这里,我们希望Presto返回前10个机场,出发次数最多:
与上一个查询一样,结果需要一些领域专业知识。例如,您需要了解“始发地”一栏包含机场代码。该代码是对于那些缺乏专业知识来分析结果的人来说毫无意义。
让我们将结果与关系数据中的其他数据结合起来,以增强我们的结果,根据。我们在示例中使用PostgreSQL,但是类似的步骤适用于任何关系型数据库。与航空公司数据一样,我们的GitHub存储库包括用于创建和在关系数据库中加载表以及将Presto连接器配置为访问它。我们选择将Presto配置为从PostgreSQL数据库中查询包含其他航空公司数据。 PostgreSQL中的表载体提供了一个映射-将航空公司代码ping到更具描述性的航空公司名称。您可以使用此附加组件我们第一个示例查询的国家数据。让我们看一下PostgreSQL中的表载体:
该表包含代码列代码以及描述列。使用这个信息,我们可以将第一个示例查询用于flight_orc表和mod-使其与PostgreSQL载体表中的数据结合:
哎呀!现在,我们已经编写了一个SQL查询来联合来自S3和PostgreSQL,我们能够提供更有价值的数据结果以提取均值-ing。无需知道或单独查询航空公司代码,描述性的结果中有航空公司名称。在查询中,引用表时必须使用完全限定的名称。什么时候利用USE命令设置默认目录和模式(非限定表)名称链接到该目录和架构。但是,任何时候您都需要查询-对于目录和架构,表名必须是合格的。否则,Presto尝试在默认目录和架构中找到它,并返回错误。如果你是引用默认目录和架构中的表,不需要完全限定表名。不过,建议您在每次参考时将其作为最佳做法,响到默认范围之外的数据源。接下来,让我们看一下PostgreSQL中的table airport。该表用作联邦(Feder)的一部分编写第二个示例查询:
查看来自PostgreSQL的数据,您会发现code列可用于加入我们对flight_orc表的第二个查询。这使您可以使用addi‐机场表中的国家信息与查询一起提供更多详细信息:
与第一个示例一样,我们可以通过以下方式提供更有意义的信息:在两个不同的数据源之间进行联合。在这里,我们可以添加名称机场,而不是用户依赖难以解释的机场代码。通过这个查询联合的快速示例,您会看到不同的组合-ents数据源和集中查询(在Presto中)可以提供对查询结果的改进。我们的示例仅增强了结果的外观和可读性。但是,在许多情况下,使用更丰富,更大数据集,查询联合以及不同来源的数据组合可以使您对数据有全新的了解。现在,我们已经介绍了一些来自最终用户的查询联合的示例让我们讨论一下其工作原理的体系结构。我们建立在一些基础之上您在Presto体系结构的第4章中了解的概念。Presto能够协调跨数据源的查询的混合执行参与查询。在前面的示例中,我们在分布式存储和PostgreSQL。对于通过Hive连接器进行的分布式存储,Presto读取数据文件直接存储,无论是来自HDFS,S3,Azure Blob存储等。传统数据库连接器(例如PostgreSQL连接器),Presto依赖于Post-greSQL作为执行的一部分执行。让我们使用之前的查询,但为了使它更有趣,我们添加了一个新谓词,该谓词引用了Post-greSQL机场表:
逻辑查询计划类似于图7-5。你看到计划包括同时扫描flights_orc和airport表。两个输入都被馈入加入联接运算符。但在将机场数据馈入联接之前,将应用过滤器因为我们只想查看阿拉斯加机场的结果。加入后,应用聚合和分组操作。最后是TopN运算符执行ORDER BY和LIMIT的组合。Presto中的查询联合| 127图7-5。联合查询的逻辑查询计划为了使Presto从PostgreSQL检索数据,它通过JDBC发送查询。例如,以幼稚的方式,以下查询被发送到PostgreSQL:
随着PostgreSQL的JDBC连接器将数据返回到Presto,Presto继续pro-处理在Presto查询引擎中执行的零件的数据。一些更简单的查询(例如SELECT * FROM public.airport)被完全推送向下访问基础数据源,如图7-6所示,以便查询执行切割发生在Presto外部,Presto充当传递对象。当前,不支持更复杂的SQL下推式。例如,聚合或仅涉及RDBMS数据的联接可以推入RDBMS以消除将数据传输到Presto。
下推查询计划分机ract,变换,负载和联合查询提取,转换,加载(ETL)是用于描述复制技术的术语数据源中的数据并将其着陆到另一个数据源中。通常情况下,为从目的地准备数据而转换数据的第一步。这可能包括删除列,进行计算,过滤和清理数据,加入数据,执行预汇总以及其他准备和发布数据的方式使它适合查询目的地。Presto并非旨在成为可与商业解决方案媲美的成熟ETL工具tion。但是,它可以通过避免使用ETL来提供帮助。因为Presto可以查询从数据源中删除数据,可能不再需要移动数据。 Presto查询存放数据以减轻ETL流程管理的复杂性。您可能仍然希望进行某种类型的ETL转换。也许你想查询预先汇总的数据,或者您不想在基础数据上加重负载系统。通过使用CREATE TABLE AS或INSERT SELECT构造,您可以移动数据从一个数据源转移到另一个数据源。将Presto用于ETL工作负载和用例的一大优势是对关系数据库以外的其他数据源。结论您现在真的对Presto中的连接器有了很好的了解。现在是时候充分利用它们。配置您的目录并准备好了解更多信息查询数据源。这将我们带入下一个主题,即Presto中有关SQL使用的所有内容。 SQL知识对于您成功使用Presto至关重要,我们涵盖了您需要了解的所有内容第8章和第9章