参考代码:UC-Net
1. 概述
导读:这篇文章研究的是RGB-D数据的显著性目标检测问题,其中的D代表的是深度图,可以通过如Kinect之类的深度传感器/深度估计网络等得到。在之前RGB-D显著性目标检测算法中一般将显著性目标当成为决策性的像素点估计问题,因而对于每个输入的样本数据都只会生成一个固定的显著性目标检测结果。其实要是对于显著性目标的结果具有较为明确的判断准则,那么这样的方式本身也没有什么问题。但是关键却是在显著性目标的标注问题上,不同人对同一幅图的显著性目标确定可能会存在差异,这就导致了使用上述算法得到的显著性目标并不是很准确。对此文章将原来的决策性检测问题通过条件变分自动编码器(CVAE)变化为基于概率模型的检测问题,因而可以对于同一张图在latent space上进行采样,从而生成多个不同的显著性目标检测结果,之后通过多数投票的方式保持显著性目标的一致性(salient concensus)。此外,文章通过遮挡之后迭代进行显著性目标检测从而得到一张图的多个显著性目标结果。
通过在RGB图像基础上引入深度图像可以极大提升显著性目标检测的准确度,但是由于人员在标注过程中存在主观判断差异与评判标准模糊,使用传统的显著性目标检测算法可能会存在结果上的歧义问题,因为算法只呈现了一个结果。这篇文章通过CAVE引入概率模型,通过采样得到多个显著性目标的结果,见下图1所示:

文章的算法会得到多个显著性目标,之后会通过显著性目标一致性(投票机制)得到最后的显著性目标。对于CVAE中的条件部分文章是通过遮挡显著性目标多次进行检测得到的,从而使得对于单张训练图片有多个显著性目标检测结果。此外,由于直接引入深度信息会导致较多的噪声,因而文章还提出了一种深度信息优化网络(depth correction network)得到丰富的语义与几何信息。
2. 方法设计
2.1 整体pipline
使用 ξ = { X i , Y i } i = 1 N \xi=\{X_i,Y_i\}_{i=1}^N ξ={
Xi,Yi}i=1N表示训练的数据对,其中 X i = { I i , D i } X_i=\{I_i,D_i\} Xi={
Ii,Di}由RGB图像和深度图像组成的RGB-D数据。文章的整体算法流程见下图所示:
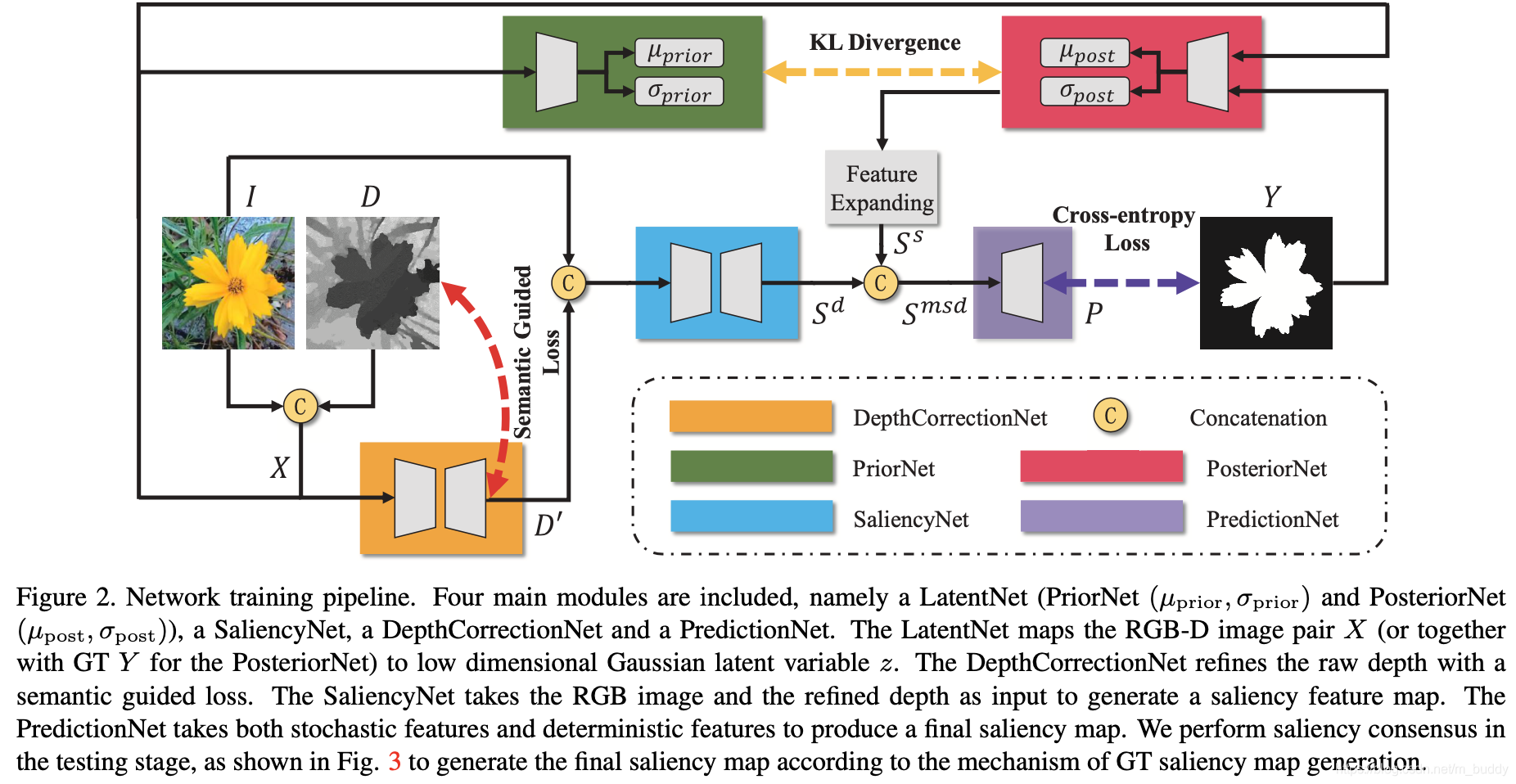
上面复杂的算法pipline主要由下面的几个子功能模块组成:
- 1)由先验网络PriorNet和后验网络PosteriorNet组成LatentNet,分别去映射 X i X_i Xi(对于PriorNet)和数据对 ( X i , Y i ) (X_i,Y_i) (Xi,Yi)(对于PosteriorNet)得到latent space下的数据 z i ∈ R K z_i\in R^K zi∈RK,用来表示两者之间的数据分布;
- 2)使用 I i , D I I_i,D_I Ii,DI输入到DepthCorrectionNet中得到优化之后的深度图像 D i ‘ D_i^{‘} Di‘,用以排除原始深度图像噪声,丰富语义和深度信息;
- 3)使用 D i ‘ , I i D_i^{‘},I_i Di‘,Ii输入到SaliencyNet得到saliency的特征图 S i d S_i^d Sid;
- 4)使用在latent space采样得到的 S i s S_i^s Sis和 S i d S_i^d Sid通过预测网络PredictionNet得到最后的显著性目标结果;
其测试的时候使用的是在latent space进行多次采样得到多个显著性目标结果,之后使用saliency concensus(多数投票)的方式得到最后的结果,其pipline见下图所示:
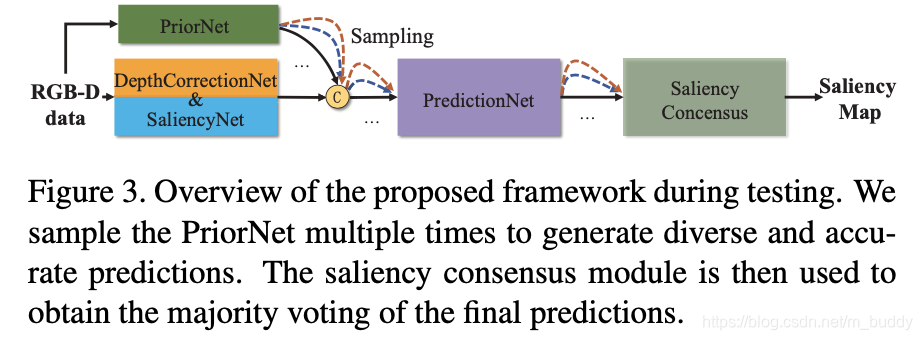
2.2 网络的各组成部分
LatentNet:
文中的CAVE包含三个部分:
- 1)由PriorNet(由五个卷积层组成)将输入的RGB-D数据映射到先验概率分布 P θ ( z ∣ X ) , z ∼ N ( μ , d i a g ( σ 2 ) ) P_{\theta}(z|X),z\sim\mathcal{N}(\mu,diag(\sigma^2)) Pθ(z∣X),z∼N(μ,diag(σ2))。其中 μ , σ ∈ R K , K = 8 \mu,\sigma\in R^K,K=8 μ,σ∈RK,K=8, θ \theta θ是可学习的网络参数;
- 2)由PosteriorNet将输入的 { X i , Y i } \{X_i,Y_i\} { Xi,Yi}映射到数据分布 Q ϕ ( z ∣ X , Y ) Q_{\phi}(z|X,Y) Qϕ(z∣X,Y), ϕ \phi ϕ是可学习的网络参数;
- 3)由latent space采样得到的数据经过解码器得到真实显著性目标分布 P w ( Y ∣ X , z ) P_w(Y|X,z) Pw(Y∣X,z);
对于上面提到的LatentNet,其具体结构见下图所示:
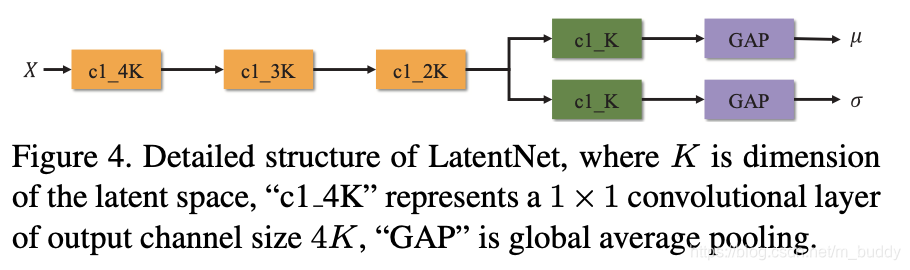
之后根据CAVE的训练监督逻辑,可以得到下面的损失表达形式:
L C V A E = E z Q ϕ ( z ∣ X , Y ) [ − l o g P w ( Y ∣ X , z ) ] + D K L ( Q ϕ ( z ∣ X , Y ) ∣ ∣ P θ ( z ∣ X ) ) L_{CVAE}=E_{z~Q_{\phi}(z|X,Y)}[-logP_w(Y|X,z)]+D_{KL}(Q_{\phi}(z|X,Y)||P_{\theta}(z|X)) LCVAE=Ez Qϕ(z∣X,Y)[−logPw(Y∣X,z)]+DKL(Qϕ(z∣X,Y)∣∣Pθ(z∣X))
对于上面提到的条件部分(也就是一个图像中对应多个显著性目标)文章是通过遮挡之后再检测得到的,具体见下图所示:

在文章中通过上述的过程总共得到4个显著性目标用于训练CVAE。
SaliencyNet:
文章的这部分网络是通过VGG16与DenseASPP构建的,最后得到特征图 S d S^d Sd,它是channel为 M = 32 M=32 M=32的数据,其结构见下图所示:
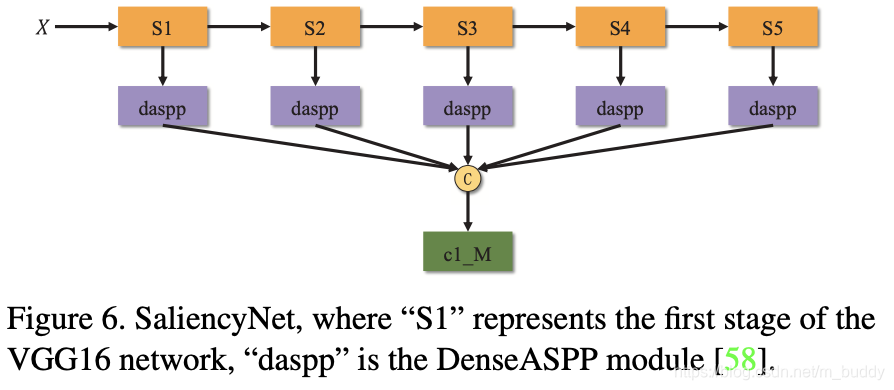
输入的RGB-D数据经过LatentNet之后得到一个样本分布 ( μ p r i o r k , σ p r i o r k ) (\mu_{prior}^k,\sigma_{prior}^k) (μpriork,σpriork),之后在其基础上通过 η ∈ N ( 0 , I ) \eta\in\mathcal{N}(0,I) η∈N(0,I)进行参数重采样得到抽样样本 z k = σ p r i o r k ⋅ η + μ p r i o r k z^k=\sigma_{prior}^k\cdot\eta+\mu_{prior}^k zk=σpriork⋅η+μpriork,之后将 z k z^k zk进行扩充得到包含 K K K个channel的样本数据 S d S^d Sd。
PredictionNet:
将上述提到的 S d S^d Sd和 S s S^s Ss进行混合(channel上concat)得到channel为 K + M K+M K+M数据 S s d S^{sd} Ssd。为了防止训练过程中网络天然偏向于saliency的特征,从而忽略了条件变量,文章还将其在channel上进行重排序,从而将其shuffle之后混合得到数据 S m s d S^{msd} Smsd,之后通过解码器得到显著性目标检测结果。
DepthCorrectionNet:
为了优化原始的深度信息 D D D,文章使用该网络进行优化深度信息的表达。该网络会预测得到一个新的深度信息 D ‘ D^{‘} D‘,它会与原始的深度信息计算 L 1 L_1 L1损失 L s l L_{sl} Lsl。为了使得在深度信息上能够体现出物体的边界信息,文章还引入了Boundary IoU损失 L I o U b L_{IoUb} LIoUb,对于这里提到的intensity图 I g I_g Ig,其是在原始RGB空间变换过来的,其计算过程描述为:
I g = 0.2126 ∗ I l r + 0.7152 ∗ I l g + 0.0722 ∗ I l b I_g=0.2126*I^{lr}+0.7152*I^{lg}+0.0722*I^{lb} Ig=0.2126∗Ilr+0.7152∗Ilg+0.0722∗Ilb
其中, I l r , I l g , I l b I^{lr},I^{lg},I^{lb} Ilr,Ilg,Ilb代表的是三个颜色通道上的变换结果,其变换过程描述为:
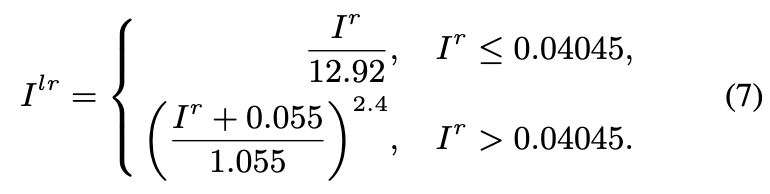
上面是对红色通道的计算,对于蓝绿通道的计算也是类似的。
之后计算 I g I_g Ig和 D ‘ D^{‘} D‘的梯度信息,得到 g D ‘ gD^{‘} gD‘和 g I gI gI,因而上面的Boundary IoU损失描述为:
L I o U b = 1 − 2 ∣ g D ‘ ∩ g I ∣ ∣ g D ‘ ∣ + ∣ g I ∣ L_{IoUb}=1-2\frac{|gD^{‘}\cap gI|}{|gD^{‘}|+|gI|} LIoUb=1−2∣gD‘∣+∣gI∣∣gD‘∩gI∣
因而,深度部分的损失函数描述为:
L D e p t h = L s l + L I o U b L_{Depth}=L_{sl}+L_{IoUb} LDepth=Lsl+LIoUb
2.3 显著性检测结果的一致性
在latent space经过 C C C次采样之后会得到预测结果 { P c } c = 1 C \{P^c\}_{c=1}^C {
Pc}c=1C,之后在这些结果上使用文章提到的自适应阈值方法得到二值结果 P b c P_b^c Pbc,这些多个检测结果经过多数表决之后得到多数表决的结果 P b m j v P_b^{mjv} Pbmjv,之后通过操作 1 c ( u , v ) = 1 ( P b c ( u , v ) = P b m j v ( u , v ) ) \mathcal{1}^c(u,v)=\mathcal{1}(P_b^c(u,v)=P_b^{mjv}(u,v)) 1c(u,v)=1(Pbc(u,v)=Pbmjv(u,v))(内部条件满足为1否则为0)进行最后计算:
P g m j v ( u , v ) = ∑ c = 1 C 1 c ( u , v ) C ∑ c = 1 C ( P b c ( u , v ) ∗ 1 c ( u , v ) ) P_g^{mjv}(u,v)=\frac{\sum_{c=1}^C\mathcal{1}^c(u,v)}{C}\sum_{c=1}^C(P_b^c(u,v)*\mathcal{1}^c(u,v)) Pgmjv(u,v)=C∑c=1C1c(u,v)c=1∑C(Pbc(u,v)∗1c(u,v))
2.4 网络的损失函数
得到显著性目标检测结果之后使用下面的损失进行监督:
L S m o o t h = ∑ u , v ∑ d ∈ x ⃗ , y ⃗ Φ ( ∣ ∂ d P u , v ∣ e − α ∣ ∂ d I g ( u , v ) ∣ ∣ ∣ ) L_{Smooth}=\sum_{u,v}\sum_{d\in\vec{x},\vec{y}}\Phi(|\partial_dP_{u,v}|e^{-\alpha|\partial_dI_g(u,v)|}||) LSmooth=u,v∑d∈x,y∑Φ(∣∂dPu,v∣e−α∣∂dIg(u,v)∣∣∣)
其中, Φ ( s ) = s 2 + 1 − e − 6 \Phi(s)=\sqrt{s^2+1-e^{-6}} Φ(s)=s2+1−e−6, α = 10 \alpha=10 α=10。则整个网络的损失函数描述为:
L = L C A V E + λ L D e p t h + λ L S m o o t h L=L_{CAVE}+\lambda L_{Depth}+\lambda L_{Smooth} L=LCAVE+λLDepth+λLSmooth
其中, λ = 0.3 \lambda=0.3 λ=0.3。
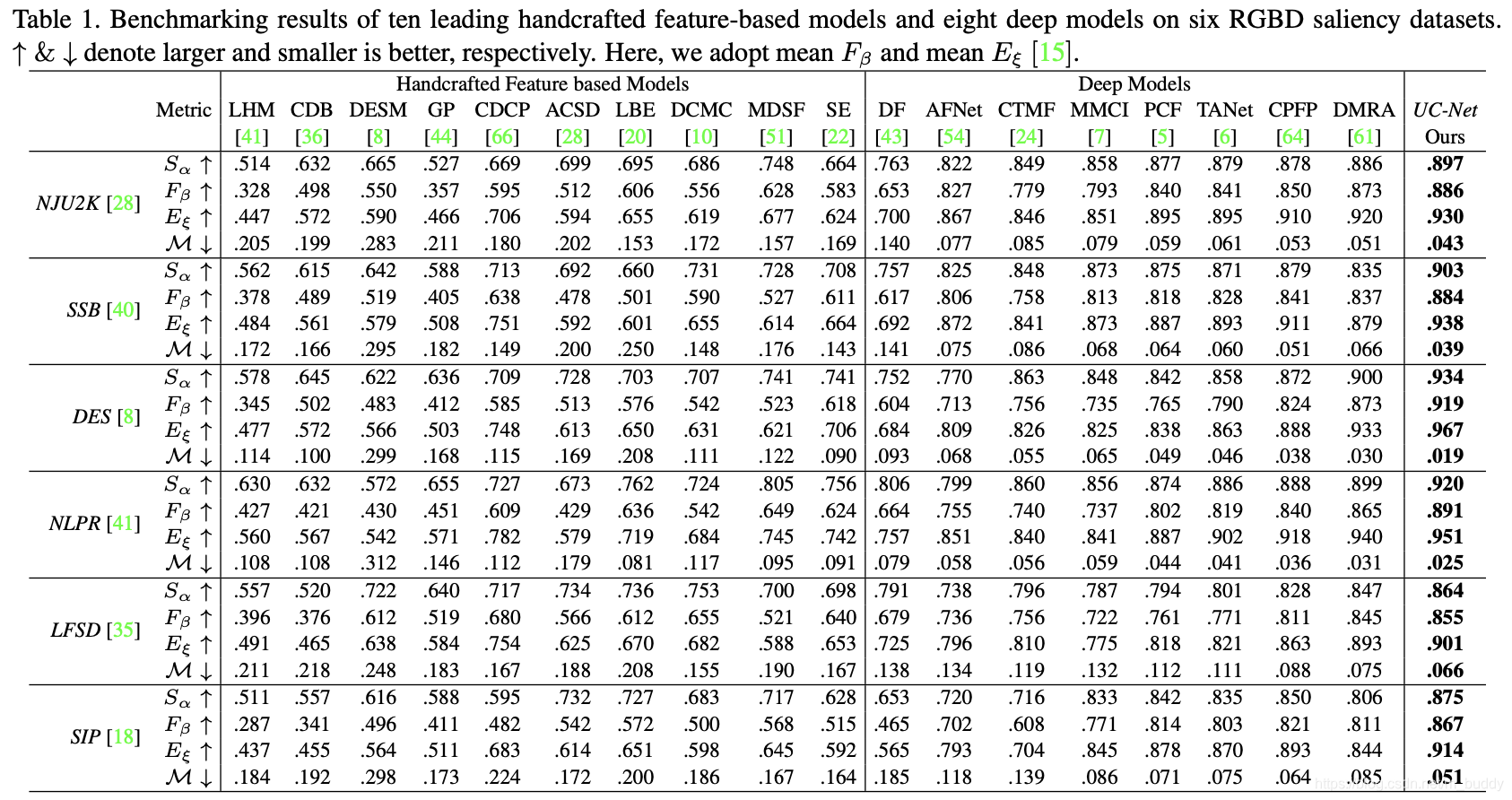
3. 实验结果