1[54. 螺旋矩阵]
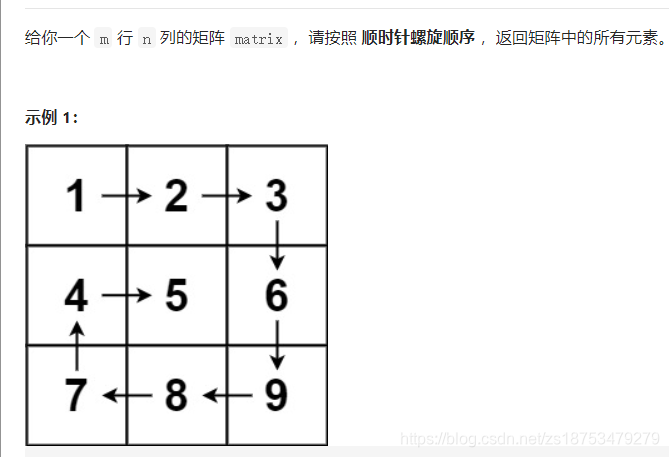
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
List<Integer> res = new ArrayList<>();
if(matrix == null || matrix.length == 0 || matrix[0] == null || matrix[0].length == 0)
return res;
int rowStart = 0;
int rowEnd = matrix.length - 1;
int colStart = 0;
int colEnd = matrix[0].length - 1;
while(rowStart <= rowEnd && colStart <= colEnd) {
for(int i = colStart ; i <= colEnd ; i++){
res.add(matrix[rowStart][i]);
}
rowStart++;
for(int i = rowStart ; i <= rowEnd ; i++){
res.add(matrix[i][colEnd]);
}
colEnd--;
if(rowStart <= rowEnd){
for(int i = colEnd ; i >= colStart ; i--){
res.add(matrix[rowEnd][i]);
}
}
rowEnd--;
if(colStart <= colEnd){
for(int i = rowEnd ; i >= rowStart ; i--){
res.add(matrix[i][colStart]);
}
}
colStart++;
}
return res;
}
}
2虚拟内存的作用
在系统中所有的进程之间是共享CPU和主存这些内存资源的。当进程数量变多时,所需要的内存资源就会相应的增加。可能会导致部分程序没有主存空间可用。此外,由于资源是共享的,那么就有可能导致某个进程不小心写了另一个进程所使用的内存,进而导致程序运行不符合正常逻辑。
为了更加有效的管理内存并少出错,现代系统提供了一种对主存的抽象的概念,叫做虚拟内存(VM)。
虚拟内存是硬件异常、硬件地址翻译、主存、磁盘文件和内核软件间的完美交互,他为每个进程提供了一个大的、一致的和私有的地址空间。
虚拟内存提供了三个重要的能力: 缓存,内存管理,内存保护
- 将主存视为一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据
- 为每个进程提供了一致的地址空间,简化内存管理
- 保护了每个进程的地址空间不被其他进程破坏
3两张表join,数据库底层是如何执行的
https://blog.csdn.net/zs18753479279/article/details/115022900
4主键索引和组合索引的区别
主键:是一种特殊的唯一索引,一张表中只能定义一个主键索引,通常有一列或列组合,用于唯一标识一条记录,使用关键字PRIMARY KEY来创建。为表定义一个主键将自动创建主键索引(聚簇索引)。
联合索引 :可以覆盖多个数据列,像INDEX(columnA, columnB)索引,这就是联合索引。
主键索引为什么只有一个?
因为主键从实现角度来看是一个 唯一 非空 聚类索引, 聚类索引在一个表中只有一个,所以主键只有一个 至于为什么聚类索引在一个表中只有一个?是因为聚类索引表数据的物理顺序和索引排序方式一致,而物理存储方式只有一种,所以聚类索引在一个表中只有一种
5组合索引是如何存储的

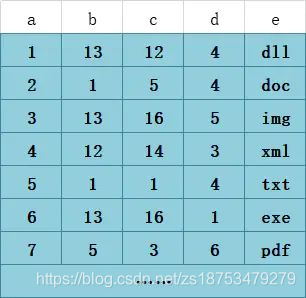
我们先看T1表,他的主键暂且我们将它设为整型自增的,InnoDB会使用主键索引在B+树维护索引和数据文件,然后我们创建了一个联合索引(b,c,d)也会生成一个索引树,同样是B+树的结构,只不过它的data部分存储的是联合索引所在行的主键值
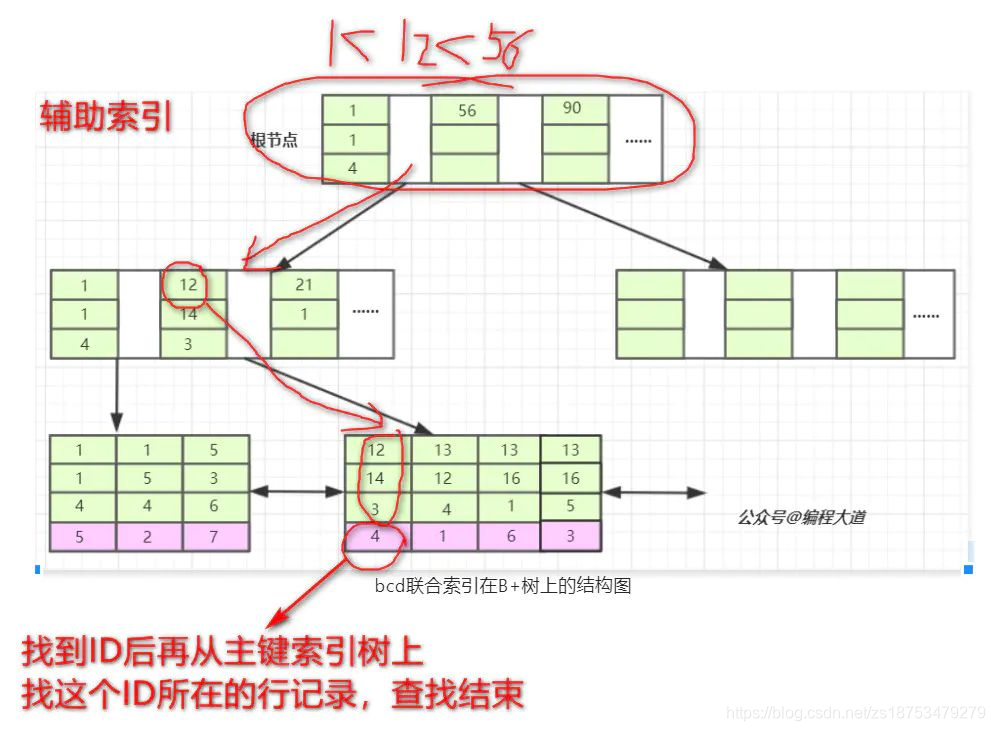
6联合索引的查找方式
当我们的SQL语言可以应用到索引的时候,比如 select * from T1 where b = 12 and c = 14 and d = 3; 也就是T1表中a列为4的这条记录。存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,第二个索引的第一个索引列为56,【1<12<56】,于是从这俩索引的中间读到下一个节点的磁盘文件地址,从磁盘上Load这个节点,通常伴随一次磁盘IO,然后在内存里去查找。当Load叶子节点的第二个节点时又是一次磁盘IO,比较第一个元素,b=12,c=14,d=3完全符合,于是找到该索引下的data元素即ID值,再从主键索引树上找到最终数据。
7redis底层数据结构六种
Redis底层数据结构有以下数据类型:1简单动态字符串 2链表 3字典 4跳跃表 5整数集合 6压缩列表
1 简单动态字符串
Redis构建了一种名为**简单动态字符串(SDS)**的抽象类型,并将SDS用作Redis的默认字符串表示。在Redis里面,C字符串只会作为字符串字面量用在一些无须对字符串值进行修改的地方(比如打印日志)。当Redis需要一个可以被修改的字符串值时,Redis就会使用SDS来表示字符串
SDS还被用作缓冲区:AOF模块中的AOF缓冲区,以及客户端状态中的输入缓冲区,都是由SDS实现的
2 链表【列表建】
链表提供了高效的节点重排能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度
列表键的底层实现之一就是链表。当一个列表键包含了数量比较多的元素,又或者列表中包含的元素都是比较长的字符串时,Redis就会使用链表作为列表键的底层实现
此外,发布与订阅、慢查询、监视器等功能也用到了链表,Redis服务器本身还使用链表来保存多个客户端的状态信息,以及使用链表来构建客户端输出缓冲区;redis-server里维护了一个字典(k,v),字典的键是一个个 频道!而字典的值则是一个链表,链表中保存了所有订阅这个channel客户端
3 字典【哈希键】
字典(映射)是一种用于保存键值对的抽象数据结构
Redis的数据库就是使用字典来作为底层实现的
字典还是哈希键的底层实现之一,当一个哈希键包含的键值对比较多,又或者键值对中的元素都是比较长的字符串时,Redis就会使用字典作为哈希键的底层实现
4 跳跃表【有序集合】
跳跃表是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的
Redis只在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构
5 整数集合【集合键】
整数集合是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现
6 压缩列表 【列表建、哈希键】
压缩列表是列表建和哈希键的底层实现之一。
当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。
当一个哈希键只包含少量键值对,而且每个键值对的键和值要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做哈希键的底层实现
8Redis zset实现原理
zset的两种实现方式
ziplist:满足以下两个条件的时候:1 元素【member 】数量少于128的时候;2 每个元素【member 】的长度小于64字节
skiplist:不满足上述两个条件就会使用跳表,具体来说是组合了map和skiplist
map用来存储member到score的映射,这样就可以在O(1)时间内找到member对应的score 即(Map-----<member , score>)
skiplist按从小到大的顺序存储score
skiplist每个元素**【member】的值都是map[score,value]对**
因为有了skiplist,才1能在O(logN)的时间内插入一个元素,并且实现快速的按score范围查找元素
9 什么是skiplist?
有序链表:
在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
而二分查找法只适用于有序数组,不适用于链表。
假如我们每相邻两个节点增加一个指针(或者理解为有三个元素进入了第二层),让指针指向下下个节点。

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。在插入一个数据的时候,决定要放到那一层,取决于一个算法(在redis 中t_zset.c 有一个zslRandomLevel 这个方法)。
现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中的下一层进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:

-
23 首先和7 比较,再和19 比较,比它们都大,继续向后比较。
-
但23 和26 比较的时候,比26 要小,因此回到下面的链表(原链表),与22比较。
-
23 比22 要大,沿下面的指针继续向后和26 比较。23 比26 小,说明待查数据23 在原链表中不存在
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。这就是跳跃表。