一、函数
函数是一段具有特定功能的、可重用的语句组,通过函数名来表示和调用。
- 函数是一段代码的抽象和封装
- 函数是一段具有特定功能的、可重用的语句组
- 函数是一种功能的抽象,表达特定功能
- 两个作用:降低编程难度和代码复用
降低编程难度:利用函数可以将一个复杂的大问题分解成一系列简单的小问题,分而治之,为每个小问题编写程序,通过函数封装,当各个小问题都解决了,大问题也就迎刃而解。
代码复用:函数可以在一个程序中的多个位置使用,也可以用于多个程序,当需要修改代码时,只需要在函数中修改一次,所有调用位置的功能都更新了,这种代码复用降低了代码行数和代码维护难度。
二、定义函数(声明函数)


- 函数名:def保留字,函数名可以是任何有效的Python标识符
- 参数列表:参数列表是调用该函数时传递给它的值
- 参数可以有零个、一个、多个,当传递多个参数时各参数由逗号分隔,当没有参数时也要保留圆括号
- 参数列表中的参数是形式参数,简称为“形参”,相当于实际参数的一种符号表示或占位符
- 参数分为非可选参数、可选参数
- 函数体:函数体是函数每次被调用时执行的代码,由一行或多行语句组成
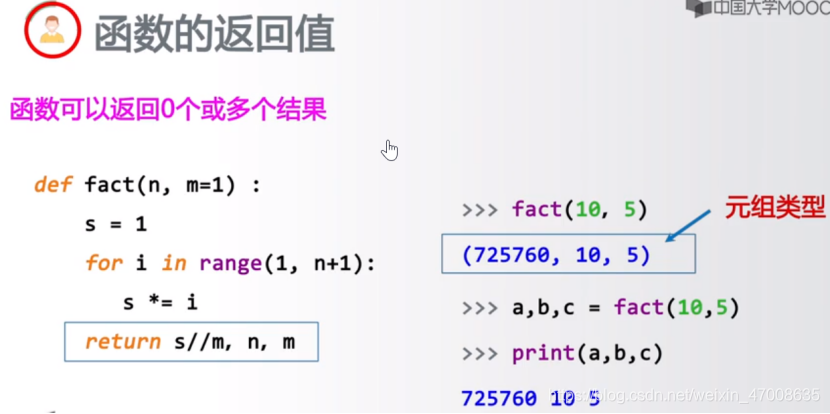
- return返回值:如果需要返回值,使用保留字return和返回值列表
- 一个函数可以有零个、一个、多个return
- 当有return时,可以有零个、一个、多个返回值
- 当有return时,当返回多个值时,这些值形成一个元祖数据类型
# 定义一个对整数n求阶乘的函数
def fact(n):
s = 1
for i in range(1, n+1):
s *= i
return s
三、调用函数
函数定义后不能直接运行,需要调用才能运行,函数调用方式:
<函数名>(<实际赋值参数列表>)
- 对函数的各个参数赋予实际值,实际值可以是实际数据,也可以是在调用函数前已经定义过的变量。
- 函数返回:函数执行结束后,根据return保留字决定是否返回结果,如果返回结果,则结果将被放置到函数被调用的位置,函数调用就此完毕

# 定义一个对整数n求阶乘的函数
def fact(n):
s = 1
for i in range(1, n+1):
s *= i
return s
print("值是:", fact(10))
输出:
值是: 3628800
- 函数式编程;尽量把程序写成一系列函数调用,在编程中大量使用函数已成为一种编程范式,叫作函数式编程
1. 函数类型
- 在Python中,函数也是有类型的,可以通过type()获得函数类型,
- 函数类型为function类型,这是一种Python的内置类型
- 如果调用函数,则类型为返回值的类型

2. 最小函数
Python语言最小函数可以不表达任何功能:

保留字pass表示不进行任何操作,起到占位的作用。对f()的调用不实现任何功能。

此处的16进制数0x000001DF7C674E58表示f()的内存地址,转换成十进制就是2059376479832。
四、函数参数:可选参数


可选参数要放置在必选参数的后面,即定义函数时,先给出所有非可选参数,然后再分别列出每个可选参数及对应的默认值。

函数的参数在定义时可以指定默认值,当函数被调用时,如果没有传入对应的参数值,则使用函数定义时的默认值替代。
五、函数参数:可变参数

确定要给的参数放在前面,不确定的参数放在后面

def fact(n, *c):
s = 1
for i in range(1, n+1):
s *= i
for item in c:
s *= item
return s
print(fact(4)) 输出:24
print(fact(4, 2)) 输出:48
print(fact(4, 2, 5)) 输出:240
print(fact(4, 2, 5, 3)) 输出:720
max(), min()的参数就是可变参数,在函数定义时参数就是设定为不确定的 *b方式
六、函数参数:参数传递
- 按位置传递参数:默认按照位置顺序的方式传递参数
- 按参数名称传递参数,采用名称参数方式不需要保持参数传递的顺序,只需要对每个必要参数赋予实际值即可,这种方式会显著增强程序的可读性

七、函数返回值
- return返回值:如果需要返回值,使用保留字return和返回值列表
- 一个函数可以有零个、一个、多个return
- 当有return时,可以有零个、一个、多个返回值
- 当有return时,当返回多个值时,中间用逗号分隔,这些值形成一个元祖数据类型

def add(x, y):
z = x + y
print(add(2, 3))
输出:
None # 没有return保留字,输出None
def add(x, y):
z = x + y
return
print(add(2, 3))
输出:
None # 有return保留字,但没有列返回值,输出None
八、变量作用域:局部变量
- 根据变量在程序中的位置和作用范围,变量分为局部变量和全局变量。
- 局部变量仅在函数内部,且作用域也在函数内部;全局变量的作用域跨越多个函数。
- 基本数据类型的变量,无论是否重名,局部变量与全局变量不同
- 可以通过global保留字在函数内部声明全局变量
- 组合数据类型的变量:如果局部变量未真实创建,则是全局变量
- 局部变量:局部变量指在函数内部定义的变量,仅在函数内部有效,当函数退出时变量不再存在。
def multiply(x, y = 10):
z = x * y # z是函数内部的局部变量
return z
s = multiply(99, 2)
print(s)
print(z)
输出:
198
Traceback (most recent call last):
File "C:/Users/520/PycharmProjects/pythonProject1/exercise.py", line 6, in <module>
print(z)
NameError: name 'z' is not defined
九、变量作用域:全局变量
- 全局变量是在函数之外定义的变量,在程序执行全过程有效,全局变量在函数内部使用时,需要提前使用保留字global声明
语法:global<全局变量>

n = 2 # n是全局变量
def multiply(x, y = 10):
global n # 声明全局变量n
n = x * y # 声明全局变量n
return x * y * n # 使用全局变量n
s = multiply(5, 3)
print("s的值是:", s)
print("n的值是:", n)
输出:
s的值是: 225
n的值是: 15
如果未使用保留字global声明,即使名称相同,也不是全局变量,程序将其作为局部变量处理:
n = 2 # n是全局变量
def multiply(x, y = 10):
n = x * y # n变量名相同,没有声明为全局变量,直接使用,是局部变量
return x * y * n
s = multiply(5, 3)
print("s的值是:", s)
print("n的值是:", n)
输出:
s的值是: 225
n的值是: 2 #不改变外部全局变量的值



十、变量作用域:全局变量(组合数据类型)

十一、lambda函数
(一)lambda函数
匿名函数(lambda函数):lambda函数是一种快速定义单行的最小函数,是从Lisp借用来的,可以用在任何需要函数的地方。

(二)lambda函数语法

1、lambda函数的参数可有可⽆无、可一个可多个,但只能返回⼀个表达式的值。
2、lambda函数的参数与def函数的参数写法是一样的
3、如果函数只有一个返回值,只有一行代码,可使用lambda简化代码量。
4、lambda函数比普通函数占用的内存空间更小
lambda函数与def函数的区别:
- lambda函数使用返回值作为函数名,不适用return保留字,它的表达式相当于def函数的函数体
(三)lambda函数实例1
f = lambda x, y: x + y # 定义一个lambda函数f,进行加法运算
print(f(10, 15))
输出: 25
f = lambda: "lambda函数" # lambda函数可以没有参数
print(f())
输出:lambda函数
# 普通函数
def fn1():
return 100
print(fn1)
print(fn1())
输出:
<function fn1 at 0x000001FB1F6A6AF8> # 如果print只是函数名,返回函数的内存地址
100 # 函数名(),是调用函数
# lambda函数,简化代码量
fn2 = lambda : 200 # 参数可有可无,如果没有参数表示只是返回值
print(fn2)
print(fn2())
输出;
<function <lambda> at 0x000001FB1F6C7288> # 如果print只是函数名,返回函数的内存地址
200 # 函数名(),是调用函数
(三)lambda函数实例2
# 计算两个数之和
def add(a, b):
return a + b
print(add(1 , 2))
add2 = lambda c, d : c + d
print(add2(1, 2))
输出;
3
3
(四)lambda函数的参数
1、无参数
fn1 = lambda : 100
print(fn1())
输出:100
fn1 = lambda : 100
print(fn1(1))
输出:报错
Traceback (most recent call last):
File "C:/Users/520/PycharmProjects/pythonProject1/111.py", line 2, in <module>
print(fn1(1))
TypeError: <lambda>() takes 0 positional arguments but 1 was given
2、一个参数
fn2 = lambda a : a*2
print(fn2("Hello Word"))
输出:
Hello WordHello Word
3、(缺省)默认参数
fn3 = lambda a, b, c = 100: a + b + c
print(fn3(10, 20))
print(fn3(10, 20, 200))
输出:
130
230
4、可变参数 *args(接收不定长位置参数,返回值是一个元组)
fn4 = lambda *args: args
print(fn4()) # 接收零个参数
print(fn4(1)) # 接收1个参数
print(fn4(1, 2, 4)) # 接收多个参数
输出:一个元组
()
(1,)
(1, 2, 4)
5、可变参数 **kwargs(接收不定长关键字参数,返回一个字典)
fn5 = lambda **kwargs: kwargs
print(fn5())
print(fn5(name=123))
print(fn5(name1=1, age=3))
输出:一个字典
{
}
{
'name': 123}
{
'name1': 1, 'age': 3}
.
(五)lambda函数的应用
1、带判断的lambda函数
fn1 = lambda a, b: a if a > b else b
print(fn1(100, 200))
输出:200
2、列表内字典数据排序
students = [
{
"name": "rose", "age": 10},
{
"name": "tom", "age": 20},
{
"name": "jack", "age": 30}
]
print(students)
# 1、按name key对应的值排序,sort()默认reverse=False升序排序
students.sort(key=lambda x:x["name"])
print(students)
输出:
[{
'name': 'rose', 'age': 10}, {
'name': 'tom', 'age': 20}, {
'name': 'jack', 'age': 30}]
[{
'name': 'jack', 'age': 30}, {
'name': 'rose', 'age': 10}, {
'name': 'tom', 'age': 20}]
students = [
{
"name": "rose", "age": 10},
{
"name": "tom", "age": 20},
{
"name": "jack", "age": 30}
]
print(students)
# 2、按name key对应的value排序,sort()降序排序
students.sort(key=lambda x:x["name"], reverse=True)
print(students)
输出:
[{
'name': 'rose', 'age': 10}, {
'name': 'tom', 'age': 20}, {
'name': 'jack', 'age': 30}]
[{
'name': 'tom', 'age': 20}, {
'name': 'rose', 'age': 10}, {
'name': 'jack', 'age': 30}]
students = [
{
"name": "rose", "age": 10},
{
"name": "tom", "age": 40},
{
"name": "jack", "age": 30}
]
print(students)
# 3、按age key对应的value排序,sort()升序排序
students.sort(key=lambda x:x["age"])
print(students)
输出:
[{
'name': 'rose', 'age': 10}, {
'name': 'tom', 'age': 40}, {
'name': 'jack', 'age': 30}]
[{
'name': 'rose', 'age': 10}, {
'name': 'jack', 'age': 30}, {
'name': 'tom', 'age': 40}]

- 一般在编写代码时,哪怕这个函数只有一行,也建议使用def和return这种方法来定义,要谨慎使用lambda函数。
- lambda函数不是定义函数的常用形式,它的存在主要是用作一些特定的函数或方法的参数,有一些非常复杂的函数,它的某一个参数就是一个函数,这种情况下使用lambda函数。
小结:

十二、高阶函数
(一)高阶函数概述
把一个函数作为另外一个函数的参数传入,这样的函数称为高阶函数,高阶函数是函数式编程的体现。可以化简代码,代码复用。
print(abs(-10)) 输出10
print(round(1.2)) 输出1
print(round(1.9)) 输出2
print(round(-1.7)) 输出-2
# 需求:任意两个数字,先按照指定要求进行整理,再求和
# 法一:
def op_sum(a, b):
return abs(a) + abs(b)
op_sum_result = op_sum(-1.2, 3.9)
print(op_sum_result) 输出:5.1
# 问题:如果要先四舍五入再求和,需要把上述代码再写一遍
# 需求:任意两个数字,先按照指定要求进行整理,再求和
# 法二:用高阶函数
def op_sum(a, b, f):
return f(a) + f(b)
op_sum_result = op_sum(-1.2, 3.9, abs)
print(op_sum_result) 输出:5.1
op_sum_result = op_sum(-1.2, 3.9, round)
print(op_sum_result) 输出:3
(二)内置高阶函数之map()
map(function, iterable),将传入的函数变量func作用到iterable(如list列表)变量的每一个元素,并将结果返回一个map对象迭代器。如果要转换为列表,可使用list()转换。
ls = [1, 2, 3, 4, 5]
def x2(a):
return a ** 2
result = map(x2, ls)
print(result)
print(list(result))
输出:
<map object at 0x000001D93D9AFD08>
[1, 4, 9, 16, 25]
(三)内置高阶函数之filter()
filter(function, iterable),用于过滤掉iterable中不符合条件的元素,返回一个filter对象。如果要转换为列表,可使用list()转换。
ls = [1, 2, 3, 4, 5, 6, 7, 8]
# 1.定义功能函数
def func(x):
return x % 2 == 0
# 2.调用filter()
result = filter(func, ls)
print(result)
print(list(result))
输出:
<filter object at 0x000001D68FADED88>
[2, 4, 6, 8]
(四)内置高阶函数之reduce()
reduce(function(x,y), sequence, initial),其中func必须有两个参数,每次func的结果继续和序列的下一个元素做累积处理。
# 计算list序列中各个数字的累加和
ls = [1, 2, 3, 4, 5]
# 1.导入模块
import functools
# 2.定义功能函数
def sum(a, b):
return a + b
# 3.调用reduce函数,累积处理序列的每个元素
result = functools.reduce(sum, ls)
print(result)
输出:15
s = "python123"
# 1.导入模块
import functools
# 2.定义功能函数
def sum(a, b):
return a + "-" + b
# 3.调用reduce函数,累积处理序列的每个元素
result = functools.reduce(sum, s)
print(result)
输出:p-y-t-h-o-n-1-2-3
(五)函数小结
1、递归
- 函数内部自己调用自己
- 必须有出口,否则报错
2、lambda函数(只有一行代码一个返回值)
- 语法:函数名=lambda 参数:返回值
- lambda函数的参数:无参数(lambda :返回值)、一个多个参数(同def写法)、默认参数(lambda key=value: 返回值)传参则覆盖默认值,不传参则使用默认值、不定长位置参数(lambda *args:返回值)返回一个元组、不定长关键字参数(lambda **kwargs: 返回值)返回一个字典
3、高阶函数
- 作用:把函数作为参数传入,简化代码
- 内置高阶函数:map(func, iterable), filter(func, iterable), reduce(func(x,y), sequence, initial)
十二、代码复用和模块化设计


-
可以把编写的代码当做一种资源,并且对这种资源进一步抽象,实现代码的抽象化。代码抽象化指的是使用函数等方法对代码赋予更高级别的定义。对同一份代码在需要时被重复使用就构成了代码复用,而代码复用是需要将代码进行抽象才能达到的效果。
-
在不同的程序设计语言中,都有代码复用的相关功能。一般来说,我们使用函数和对象这两种方法来实现代码复用。可以认为这两种方法是实现代码复用的方法,也可以认为这两种方法是对代码进行抽象的不同级别。函数能够命名一段代码,在代码层面建立初步抽象,但这种抽象级别比较低,因为它只是将代码变成了一个功能组。对象通过属性和方法,能够将一组变量甚至一组函数进一步进行抽象。
-
在代码复用的基础上,我们可以开展模块化设计。模块化设计是基于一种逻辑的设计思维,它的含义是通过封装函数或对象将程序划分为模块以及模块之间的表达。
-
模块化设计:通过函数和对象可以实现模块化设计,分而治之


– 紧耦合:尽可能合理划分功能块,功能块内部耦合紧密
– 松耦合:模块间关系尽可能简单,功能块之间耦合度低
– 紧耦合的缺点在于更新一个模块可能导致其他模块变化,复用较困难;松耦合一般基于消息或协议时间,系统间交互简单。
– 松耦合代表了模块化,从系统观点来看,松耦合是总体设计原则 -
一般来说,完成特定功能或被经常复用的一组语句应该采用函数来封装,并尽可能减少函数间参数和返回值的数量。
-
一般编写程序时,通过函数来将一段代码与代码的其他部分分开,那么函数的输入参数和返回值就是这段函数与其他代码之间的交流通道,这样的交流通道越少越清晰,那么定义的函数复用可能性就越高。所以在模块化设计过程中,对于模块内部,也就是函数内部,尽可能的紧耦合,它们之间通过局部变量可以进行大量的数据传输。但是在模块之间,也就是函数与函数之间要尽可能减少它们的传递参数和返回值,让它们之间以松耦合的形式进行组织,这样每一个函数才有可能被更多的函数调用,它的代码才能更多的被复用。
十三、函数递归
(一)理解递归
递归是一种编程思想,应用场景:
1、如果要遍历一个文件夹下面的所有文件,通常会使用递归来实现
2、很多算法都离不开递归,如快速排序
递归的特点:
1、函数内部自己调用自己
2、必须有出口,否则会形成死循环

基例:基础实例,指存在的一个或多个不需要再次递归的实例,处于递归的最末端

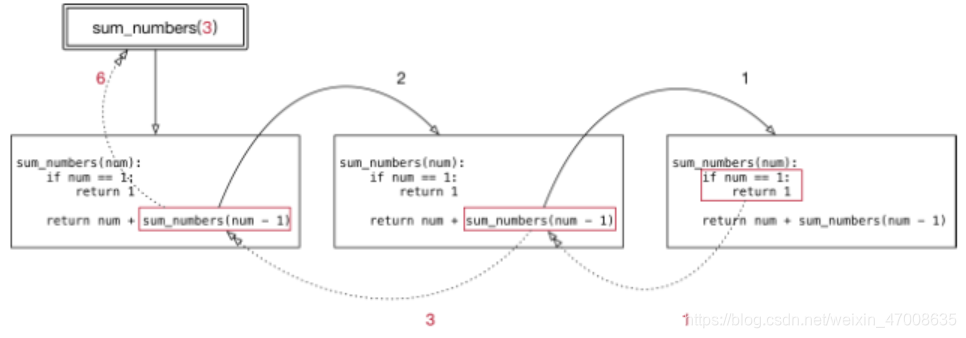
(二)递归实例1
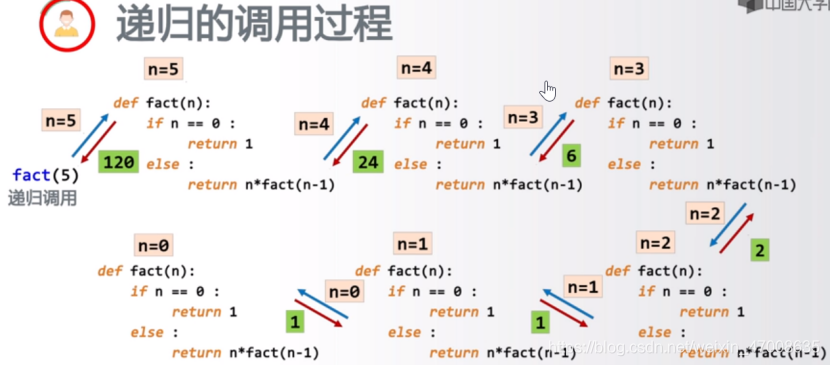
# 3 + 2 + 1
def sum_numbers(num):
if num == 1:
return 1 # 如果是1,直接返回1--出口
return num + sum_numbers(num - 1) # 如果不是1,重复执行并返回结果
sum_result = sum_numbers(3)
print(sum_result)
递归,如果没有出口,会报错
(三)递归实例2


(四)递归实例3

(五)递归实例4 Fibonacci sequence:


FibonacciV1:
def f(n):
if n == 1 or n == 2:
return 1
else:
return f(n-1) + f(n-2)
print(f(6))
FibonacciV2:
a, b = 0, 1
i = 0
while a < 20:
# print(a, end=",")
print("第{}个数是{}".format(i, a), end=",")
i += 1
a, b = b, a + b
输出:
8
第0个数是0,第1个数是1,第2个数是1,第3个数是2,第4个数是3,第5个数是5,第6个数是8,第7个数是13,
(六)递归实例5
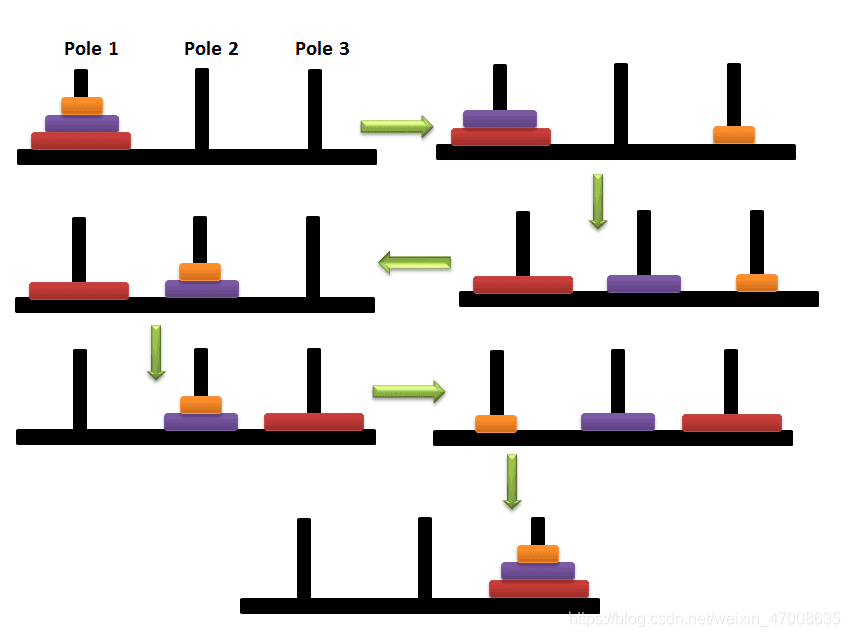
汉诺塔(Hanoi Tower)问题:https://baike.baidu.com/item/汉诺塔问题/1945186?fr=aladdin



设h(n)为汉诺塔问题的最少移动次数,则h(1) = 1, h(2) = 3, h(n) = 2 * h(n - 1) + 1, 使用数学归纳法可得:
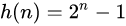
思考:主要难点在else部分,迭代地调用hanoi(n-1, src, mid, dst),此处调用hanoi函数,默认按照参数的位置传递实参,这里n-1次迭代,mid传递给dst,dst传递给mid。随着递归的进行,src柱子,dst柱子,mid柱子,在过程中相互不断变换角色的,同时遵循“每次只能移动一个圆盘;大盘不能叠在小盘上面”的规则,对照代码和图示很好理解。
单纯看代码还是有些绕,求大神给一个简单清晰的解释,跪谢!
count = 0
def hanoi(n, src, dst, mid):
global count
if n == 1:
print("{}:{}->{}".format(1, src, dst))
count += 1
else:
hanoi(n-1, src, mid, dst)
print("{}:{}->{}".format(n, src, dst))
count += 1
hanoi(n-1, mid, dst, src)
hanoi(2, "A", "B", "C")
print(count)
输出:
1:A->C
2:A->B
1:C->B
def move(n, From, Buffer, To):
if n == 1: # 1个盘子,直接打印出移动动作
print("move", n, "from", From, "to", To)
else: # n > 1时,用抽象出的3步来移动
move(n-1, From, To, Buffer) # c作为缓冲,移动n-1个a->b暂存在这(即把除了最大的盘子之外的盘子从A移到B)
move(1, From, Buffer, To) # b作为缓冲, 移动1个a->c(即把最大的盘子从A移到C)
move(n-1, Buffer, From, To) # a作为缓冲,移动暂存在b的n-1个b->c(即把除了最大的盘子之外的盘子从B移到C)
move(3,"A", "B", "C")
与把大象关进冰箱类似,一共就三步
- 把 n-1 号盘子移动到缓冲区
- 把1号从起点移到终点
- 然后把缓冲区的n-1号盘子也移到终点
要从a到b 那c就是缓冲 move(n-1,from,to,buffer)
要从a到c 那b就是缓冲 move(1,from,buffer,to)
要从b到c 那a就是缓冲 move(n-1,buffer,from,to)

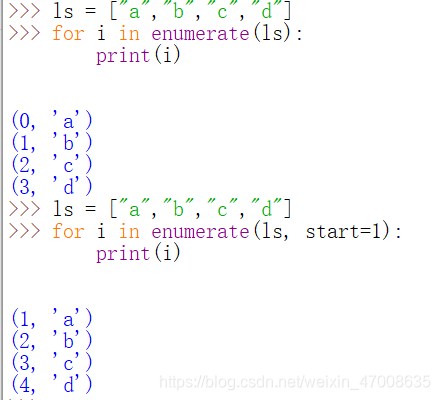
十四、enumerate()函数

enumerate(iterable[,start=0])函数
- enumerate()返回的是一个元组,元组第一个数是iterable的下标,元组第二个数是iterable的元素
- 用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用于for循环中;
- start参数用来设置返回数据下标的起始值,默认为0
PS. source, python123, zhihu, bilibili