前言
这是2020年博主参加的第一个竞赛,kaggle上面的小麦检测。这场比赛是对小麦头进行目标识别,kaggle大赛官方说是意义重大,可以更好的评估粮食产量,为全人类做贡献,简直是厉害了。这个比赛结束后我就一直没有复盘,现在趁着做竞赛复盘系列把这些从我指间漏掉的知识种子一粒粒
的重新收起来。

这个比赛的中后期被yolov5霸榜了,但是后来被kaggle官方禁用了。按照惯例大家先一起深吸一口欧气,我们就开始本次复盘。
首先是竞赛的传送门,请大家阅读本文前先去熟悉下赛题:

现在开始复盘这个比赛。
第一名 (吸到4点欧气)
1.Custom mosaic augmentation
一种基于mosaic的创新,只对图片的四个角进行裁剪后拼接,这样可以更好的保持住边界的信息。

从图中可以看出来,每张裁剪的四个边中有两个边是保留了比较完整的边界信息。而传统的mosaic的四个边都会裁到框而造成一些难分的情况。
2.heavy augmentation
冠军用到了以下的augmentation:
RandomCrop, HorizontalFlip, VerticalFlip, ToGray, IAAAdditiveGaussianNoise, GaussNoise, MotionBlur, MedianBlur, Blur, CLAHE, Sharpen, Emboss, RandomBrightnessContrast, HueSaturationValue
在数据集比较少而问题较为复杂的时候,比如这次的小麦检测比赛就背景十分复杂,肉眼都比较难分辨小麦头。这时去尝试增加heavy augmentation就能减小模型的方差,收获到效果。看到有些用了heavy augmentation的思路中提到了heavy augmentation的好处之一就是可以增强model的roubustness来减少private LB的shake发生。除了以上的augmentation,也应该关注一些较为少见的比如grid mask、channel shuffle、cutout等等,有些augmentation在特定的数据集上会有很大的提分能力。
这场比赛因为小麦之间很容易互相重叠,所以mixup带来的效果被证实非常不错。

3.Plabel
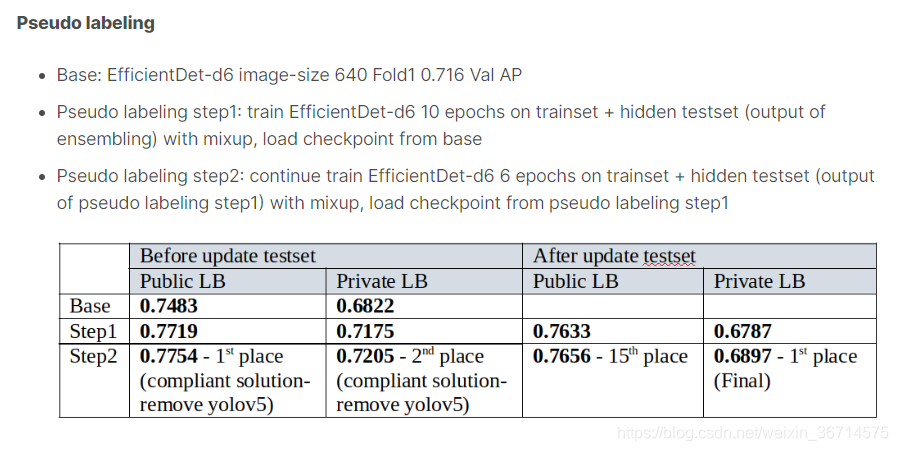
Plabel大家都知道是个笨方法,这里主要是学习下冠军是怎么做Plabel的,没那么容易跑偏。
ensemble做test set的plabel,然后train efficientdetD6 (A),得到stage1 model.
stage1 model做plabel,然后继续train A。
4.其他idea
- 使用外部数据集:如果有外部数据集available一定要去尝试,但是一定要确定外部数据集的license,之前有因为数据集的license问题被取消第一名成绩的。如果不确定的话需要致信原作者去确认。在这场比赛中冠军就是确认了两个外部数据集的使用权限。然后进行了人工的标注。
- 删除了小的bounding-box(<10pixel),这种做法我在两次目标检测竞赛中都有确认过有效。
- 模型融合
Model
5 folds, stratified-kfold, splitted by source(usask_1, arvalis_1, arvalis_2…)
Optimizer: Adam with initial LR 5e-4 for EfficientDet and SGD with initial LR 5e-3 for Faster RCNN FPN
LR scheduler: cosine-annealing
Mixed precision training with nvidia-apex
Performance
Valid AP/Public LB AP
EfficientDet-d7 image-size 768: Fold0 0.709/0.746, Fold1 0.716/0.750, Fold 2 0.707/0.749, Fold3 0.716/0.748, Fold4 0.713/0.740
EfficientDet-d7 image-size 1024: Fold1,3
EfficientDet-d5 image-size 512: Fold4
Faster RCNN FPN-resnet152 image-size 1024: Fold1
Ensemble 9 models above using wbf can achieve 0.7629 Public LB/0.7096 Private LB (before update testset)
从冠军分享可以看出他ensemble了9个model,回想起一些别的比赛,往往第一名都是4-6个模型起步。虽然这种做法毫无工业价值,但是也提示我们在竞赛中,如果题目要求允许,至少要整3个尺度,3类模型去测试。(好蛋疼)
第二名(吸到5点欧气)
首先开源了代码,见如下传送门:
1.关于数据异常noisy的思路
第二名大佬分享了一堆思路,大篇大篇的English非常的头疼,但是读完博主还是觉得有必要分享这位大佬的思路。大佬认为数据集极为的noisy,所以选择到非常好的train-val切分的strategy是几乎不可能的,在这种情况下大佬的思路如下:整体上相信LB分数,但是按照如下原则:
1) I believe that it is accurate within 1% of range, e.g. a 0.77 model is comparable to a 0.76 one, but anything in between is sketchy.
亚军认为0.01分以内的差距是值得信赖的,但是任何小于0.01的差距都是值得怀疑的。
2) I don’t believe that any form of K-fold will work for the competition. First, the training/test sets are analogous but different distributions, which will break some of the underlying assumptions of Kfold. Additionally, the n-times overhead brought about by training multiple folds is too much for people running heavy models (unless you are doing weight-space averaging, which could also mess up your score). I suggest sticking to a pre-defined train/valid split. (I could also be horribly wrong on this one)
亚军放弃了K-fold Strategy,因为一方面训练集和测试集同类但不同分布,这会打破k-fold的假设条件。同时k-fold带来的巨大开销很难在大模型上面开展。所以亚军建议坚持简单的holdout划分即可。

3) Some images are more noisy than others, and some images look “more similar” to the test images than others.
4) By the nature of a competition, the goal is never to find a “well generalized” model, but the model that performs the best on the private test set. This is partially why pseudo-labeling works so well, not just because it is generally a form of consistency regularization, but it also takes into account our desired distribution.
亚军认为我们比赛的目标并不是找到最“泛化”的model,而是找到在private test set上表现最好的model。这也是为什么Plabel表现好的原因。这里亚军指的应该是在private test set上面做的plable能够让模型熟悉测试集分布。
2.tricks
Proposal-suppression-based object detection is usually extremely sensitive wrt. to the choice of box suppression method and threshold, which has an interesting interaction with incremental development of tricks and models. Here is something I observed when probing the public LB. We already know that is pretty noisy, but naturally we may be able to “incrementally” test if some tricks works, like this:
亚军认为基于Proposal抑制的目标检测算法(各种NMS、softnms、WBF之类的)对于框抑制算法和阈值非常的敏感。也就是我们对比一个trick的时候,可能会受到不同NMS阈值的影响:
这里可以这样理解,比如加入“multiscale”这个trick训练一个yolov5,如果在LB上比不加的yolov5分数低,能够说明multiscale这个trick不work吗?大佬理解是不能的,而是应该按照如下的方法去实验:
1) train a naive model, obtain local performance l_0, and submit under a set of box suppression hyper-parameter (denoted A), we obtain a performance measure P
2) retrain the same model with trick t_1 and get l_1, if l_1 is lower than l_0, evaluate under A and minor variations of it and obtain a set of P_1s
3) Most of P_1 should be better than P_0, and if l_n is better than l_m, P_n should be better than P_m
…. and so on, and you may wanna do combinations of tricks like t_12 and P_12 to figure out interactions between them.
这段我理解意思就是判断一个trick 是否work应该小范围调解nms阈值,因为不同的trick work的nms阈值很敏感。不能直接下结论就说不行。
下面亚军列举了work和不work的调参结果:
work:
hyper-parameters of an LR method
hyper-parameters of an augmentation
existence, or lack thereof, of an augmentation
loss function
data sources
不work:
input-altering techniques
choice of LR schedule
optimizing techniques
3.模型的选择
亚军尝试了DetectorRS和EfficientDet系列,最后选择了D6(coco pretrained)。
- 为什么不用D1-D5?
模型对于该问题精度不足。 - 为什么不用D7?
因为D7是通过1536尺寸训练获得的精度,基于算力考虑,未选择D7。 - 为什么不用D6 with noisy student/AdvProp pretrained?
发现这些pretrained较难收敛。
I tried over 10 different techniques by dissecting the timm-efficientdet repo line by line and hacking into them, but turned out simplicity and elegance prevailed. The best performance is achieved by the default setting of the D6 model (with anchors unchanged; I tried KNN clustering of anchors in train set but it gave worse results), with default huber loss and focal loss.
亚军对于D6进行了魔改但是收效甚微,尝试了KNN聚类anchor,精度反而变差了。
4.augmentation
A.Compose(
[
A.RandomSizedCrop(min_max_height=(800, 1024), height=1024, width=1024, p=0.5),
A.OneOf([
A.HueSaturationValue(hue_shift_limit=0.2, sat_shift_limit= 0.2,
val_shift_limit=0.2, p=0.9),
A.RandomBrightnessContrast(brightness_limit=0.2,
contrast_limit=0.2, p=0.9),
],p=0.9),
A.ToGray(p=0.01),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.Transpose(p=0.5),
A.JpegCompression(quality_lower=85, quality_upper=95, p=0.2),
A.OneOf([
A.Blur(blur_limit=3, p=1.0),
A.MedianBlur(blur_limit=3, p=1.0)
],p=0.1),
A.Resize(height=1024, width=1024, p=1),
A.Cutout(num_holes=8, max_h_size=64, max_w_size=64, fill_value=0, p=0.5),
ToTensorV2(p=1.0),
],
p=1.0,
bbox_params=A.BboxParams(
format='pascal_voc',
min_area=0,
min_visibility=0,
label_fields=['labels']
)
)
cutmix/mixup/normal的比例:
if self.test or random.random() > 0.33:
image, boxes = self.load_image_and_boxes(index)
elif random.random() > 0.5:
image, boxes = self.load_cutmix_image_and_boxes(index)
else:
image, boxes = self.load_mixup_image_and_boxes(index)
5.jigsaw:getting more data by restoring original image
首先附上一个jigsaw的notebook:
jigsaw适合某些比赛,比如提供了原始大图的切片数据。通过jigsaw算法可以恢复原始大图,这样再做overlap切割的时候就可以调整overlap获得更多的图片了。
但是做jigsaw的时候,发现了两个问题:
-
Boxes over the edge are fractured in the sense that if a wheat head appears in half in one image and in half in another, there will be two boxes in the final image. This will generate huge amount of noise and will certainly degrade model performance.
边框如果被切断,那么恢复为大图的时候就出现了两个框。 -
This is more subtle. Remark that in the data insight section I talked about the conundrum of boxes over the edge. Now, if we are now cropping 1024 patches from the larger image, the resulting distribution is actually different than the one represented by what we now can see as crops at special positions. I didn’t really document the changes in model performance, but it is indeed significant enough for training.
-
重新切割会导致框的分布不同。

这块我还没有特别的弄明白,如果有大佬看懂的,不吝赐教。
查看了后面一些方案的设计,我发现方案普遍很乱,可能是因为这个赛题本身数据的原因,所以大家的获胜方案都有些tricky,没有那么的insight,因此我决定暂时不分析后面的方案了。
正在把第二名的方案源码进行分析,应该后面会重点分析这个solution的源码。谢谢大家支持!