自然语言处理大作业-三种中文分词方法的性能对比与评分
项目地址
https://github.com/ImViper/nlp_Chinese_word_segmentation
文档在doc文件夹里。自行fork或者star下载。
需要环境
- python3
- numpy
安装方法:
pip3 install --user numpy scipy matplotlib
或者使用Anaconda集成环境。
项目结构
| 类名 | 作用 |
|---|---|
| dict_generator.py | 将标准数据集生成为json格式的文件,供后续的分词使用 |
| hmm_seg.py | 采用隐式马尔可夫模型的中文分词器 |
| mm_seg.py | 基于最大匹配法(Maximum Matching)的中文分词器 |
| unigram_seg.py | 基于词典以及1-gram的中文分词器 |
| demo.py | 测试用例 |
| seg.py | 分词器,生成分词结果 |
| score.py | 评分器,评定不同分词方法的精确率、召回率、f1score |
使用方法
1.dict_generator.py
首先使用dict_generator.py,将需要使用的数据集转换为json格式的字典。这里采用的是PKU数据集。也一起上传到项目中了。
修改其中的parser,修改到你想要的数据集位置,以及生成的文件名。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--corpus_path', default='datasets/pku/pku_training_words.utf8')
parser.add_argument('--dict_path', default='dicts/pku_dict.json')
parser.add_argument('--encoding', default='utf-8')
args = parser.parse_args()
corpus_dict = generate_dict(args.corpus_path, encoding=args.encoding)
dict_save(corpus_dict, save_path=args.dict_path)
print("Preview: (First 50 items)")
count = 0
for pair in corpus_dict.items():
print(pair)
count += 1
if count == 50:
break
2.seg.py
修改seg,py里的参数,选择你要采用的中文分词方法,生成不同的结果。修改红色框框选中部分。结果保存在test_data文件夹中。
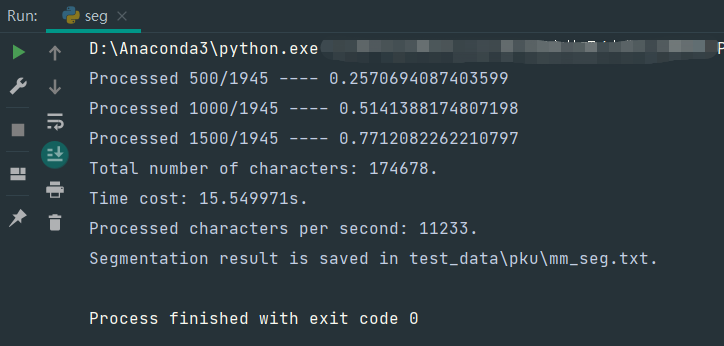
运行结果如下
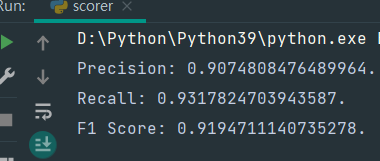
3.score.py
对不同的分词方法所产生的结果进行评分。修改选定文件的路径,以及你所用数据集的正确数据的文档路径即可。
结果如下
问题解决
- 山西分词语料库的读取问题
生成字典的时候,需要根据数据集提取词语。山西数据集是用空格进行分割,但又不是一个空格,因此不能用方法1进行切割。
使用方法2,split()默认分割方式为任何空白,因此能够正确分割。
#方法1:
line.strip().split(' ') # 错误
#方法2
line.strip().split() #正确
- 人民日报语料库的编码问题
通过文本编辑器查看人民日报语料库的编码时,其显示为gb2312,但在python中使用该编码进行读取会出现如下错误
UnicodeDecodeError: 'gb2312' codec can't decode byte 0xe9 in position 7524: illegal multibyte sequence
改为使用gbk编码进行解码,则能够正确读取。
- 搜狗词典的编码问题
通过文本编辑器查看SogouLabDic.dic的编码时,其显示为gb2312,但在python中使用该编码进行读取会出现如下错误
UnicodeDecodeError: 'gb2312' codec can't decode byte 0xb2 in position 6549: illegal multibyte sequence
改用gbk进行读取仍然报错
UnicodeDecodeError: 'gbk' codec can't decode byte 0xfa in position 799: illegal multibyte sequence
通过一阵google,终于在知乎上找到了这个问题的解决方法。
使用gbk的超集gb18030尝试,解码成功!
4.分词源码的单个测试问题
如果想要在hmm_seg.py等分词方法里测试此方法是否正常。需要修改文件首部的Import。将from shared import hmm改为import hmm
# coding=utf-8
import os
import sys
sys.path.append('..')
from shared import hmm
# import hmm
5.日期,时间的的额外处理
分析五个模型的分词结果,我们发现不管是基于词典的最大匹配法,基于统计的隐式马尔可夫模型,还是二者混合的 Unigram 模型,均无法有效的将时间,数字,人名和地名准确的切分处理。其原因在于最大匹配是基于字典的切分方式,当遇到字典中未出现的词语时,最大匹配法无法正确的切分。
解决方法:因为数字和日期的出现规律较为单一,所以采用人工规定义规则的方式,增加了基于规则的数字,日期匹配算法。将所有的数字单独分做一个词。如果数字末尾有年、月、日,则和其合并为一个词。
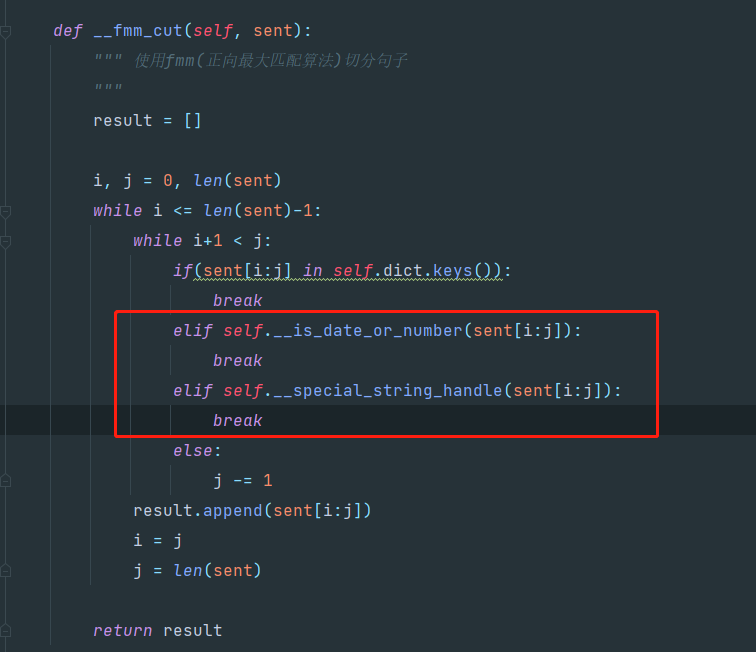
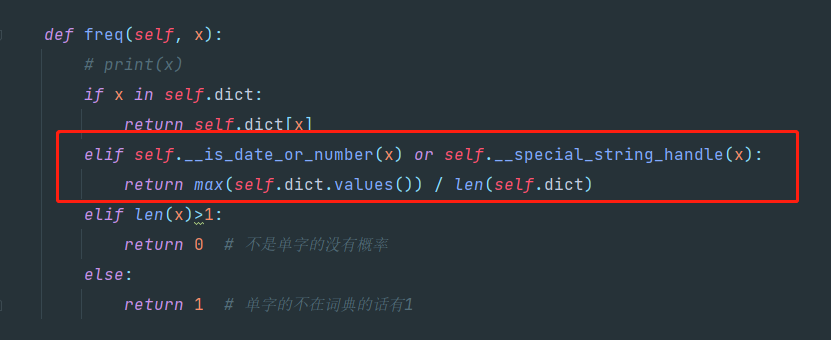
在代码中修改以下地方可以自由选择是否进行额外处理。
将截图中红色框内的代码注释掉即可。
mm_seg.py
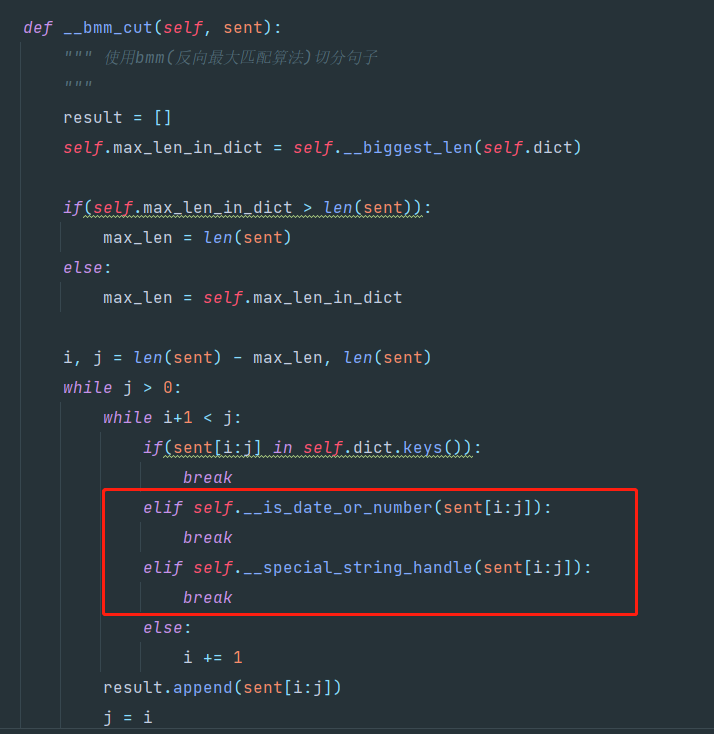
unigram_seg.py
结果展示
数据集:以下实验使用的数据集为Bakeoff 2005的PKU数据集。
性能指标:准确率,召回率,F1Score,处理速度。
实验中发现有大量日期和数字没有能够正确分词,因此采用了人工定义规则的方法去改进,改进后评分得到挺大提升。
人工定义规则:所有数字单独分做一个词。若数字末尾有"年",“月”,“日”,和其合并成一个词。缺点:不能覆盖所有情况,以文字出现的日期和数字情况多样,难以用规则描述。如,上千,一两等等
结果:最大匹配法,Unigram以及隐式马尔可夫模型如下列各表所示。
最大匹配法结果:
表1 最大匹配法结果展示
| 模型 | Precision | Recall | F1 | 速度(字/s) |
|---|---|---|---|---|
| 前向 | 0.851 | 0.915 | 0.882 | 56000+ |
| 后向 | 0.852 | 0.917 | 0.884 | 19000+ |
| 双向 | 0.953 | 0.918 | 0.884 | 15000+ |
特殊字符处理
分析五个模型的分词结果,我们发现不管是基于词典的最大匹配法,基于统计的隐式马尔可夫模型,还是二者混合的 Unigram 模型,均无法有效的将时间,数字,人名和地名准确的切分处理。其原因在于最大匹配是基于字典的切分方式,当遇到字典中未出现的词语时,最大匹配法无法正确的切分。
解决方法:因为数字和日期的出现规律较为单一,所以采用人工规定义规则的方式,增加了基于规则的数字,日期匹配算法。将所有的数字单独分做一个词。如果数字末尾有年、月、日,则和其合并为一个词。
缺点是不能覆盖所有的情况,以文字出现的日期和数字情况多样,难以用规则描述。如:上千、一两等等。
通过实验,我们取得了 3%的 F1 值提升。 具体结果如下表所示。
表3 加入日期数字后最大匹配法结果展示
| 模型 | Precision | Recall | F1 | 速度(字/s) |
|---|---|---|---|---|
| 前向 | 0.907 | 0.931 | 0.919 | 9300+ |
| 后向 | 0.909 | 0.933 | 0.921 | 17000+ |
| 双向 | 0.910 | 0.933 | 0.921 | 5700+ |
Uni-Gram模型
表2 n-gram结果展示
| 模型 | Precision | Recall | F1 | 速度(字/s) |
|---|---|---|---|---|
| 普通 | 0.844 | 0.922 | 0.881 | 8400+ |
| 识别数字/日期 | 0.892 | 0.937 | 0.914 | 3600+ |
HMM隐马尔可夫
| 模型 | Precision | Recall | F1 | 速度(字/s) |
|---|---|---|---|---|
| 隐马尔可夫 | 0.**777 | 0.792 | 0.785 | 20000+ |