sigmoid_cross_entropy_with_logits
TensorFlow最早实现的交叉熵算法。这个函数的输入是logits和targets,logits就是神经网络模型中的 W * X矩阵,注意不需要经过sigmoid,而targets的shape和logits相同,就是正确的label值,例如这个模型一次要判断100张图是否包含10种动物,这两个输入的shape都是[100, 10]。注释中还提到这10个分类之间是独立的、不要求是互斥,这种问题我们称为多目标。
softmax_cross_entropy_with_logits
Softmax本身的算法很简单,就是把所有值用e的n次方计算出来,求和后算每个值占的比率,保证总和为1,一般我们可以认为Softmax出来的就是confidence也就是概率,softmaxcrossentropywithlogits和sigmoidcrossentropywithlogits很不一样,输入是类似的logits和lables的shape一样,但这里要求分类的结果是互斥的,保证只有一个字段有值,例如CIFAR-10中图片只能分一类而不像前面判断是否包含多类动物。在函数头的注释中我们看到,这个函数传入的logits是unscaled的,既不做sigmoid也不做softmax,因为函数实现会在内部更高效得使用softmax,对于任意的输入经过softmax都会变成和为1的概率预测值,这个值就可以代入变形的Cross Entroy算法- y * ln(a) - (1 - y) * ln(1 - a)算法中,得到有意义的Loss值了。如果是多目标问题,经过softmax就不会得到多个和为1的概率,而且label有多个1也无法计算交叉熵,因此这个函数只适合单目标的二分类或者多分类问题。
在计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_entropy_with_logits,那么它到底是怎么做的呢?
首先明确一点,loss是代价值,也就是我们要最小化的值
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
除去name参数用以指定该操作的name,与方法有关的一共两个参数
:
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes
softmax的公式是:
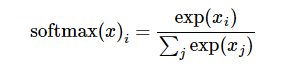
至于为什么是用的这个公式?这里不介绍了,涉及到比较多的理论证明
第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵,公式如下:
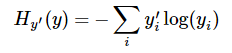
其中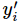
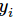
softmax的输出向量[Y1,Y2,Y3...]
显而易见,预测
注意!!!这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到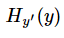 ,如果求loss,则要做
,如果求loss,则要做
果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到,如果求loss,则要做一步tf.reduce_mean操作,对向量求均值!
一步tf.reduce_mean操作,对向量求均值!预测获得的结果值越大,表示属于这个类的可能性更大。