时间序列预测中的机器学习方法(四):自回归差分移动平均模型(Auto ARIMA)
本文是“时间序列预测中的机器学习方法”系列文章的第四篇,如果您有兴趣,可以先阅读前面的文章:
【数据分析】利用机器学习算法进行预测分析(一):移动平均(Moving Average)
【数据分析】利用机器学习算法进行预测分析(二):线性回归(Linear Regression)
【数据分析】利用机器学习算法进行预测分析(三):最近邻(K-Nearest Neighbours)
自回归差分移动平均模型(ARIMA,Auto Regressive Integrated Moving Average Model)是一种非常流行的时间序列预测统计方法。ARIMA模型将过去的值考虑在内,以预测将来的值。ARIMA中有三个重要参数:
- p(用于预测下一个值的过去值)
- q(用于预测未来值的过去预测误差)
- d(差分顺序)
ARIMA的参数调整会花费大量时间。因此,我们使用Auto ARIMA自动选择误差最小的(p,q,d)最佳组合。
数据集和前面写的三篇文章相同,目的是为了比较不同算法对同一数据集的预测效果。数据集和代码放在了我的GitHub上,需要的朋友可以自行下载。
导入包,并读入数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('NSE-TATAGLOBAL11.csv')
将日期作为索引。
# setting the index as date
df['Date'] = pd.to_datetime(df.Date,format='%Y-%m-%d')
df.index = df['Date']
将原始数据划分为训练集和预测集。
data = df.sort_index(ascending=True, axis=0)
train = data[:987]
valid = data[987:]
training = train['Close']
validation = valid['Close']
导入模型,自动寻找最佳参数p,q,d。
from pmdarima import auto_arima
model = auto_arima(training, start_p=1, start_q=1, max_p=3, max_q=3, m=12, start_P=0, seasonal=True, d=1, D=1, trace=True, error_action='ignore', suppress_warnings=True)
model.fit(training)
forecast = model.predict(n_periods=248)
forecast = pd.DataFrame(forecast, index = valid.index, columns=['Prediction'])
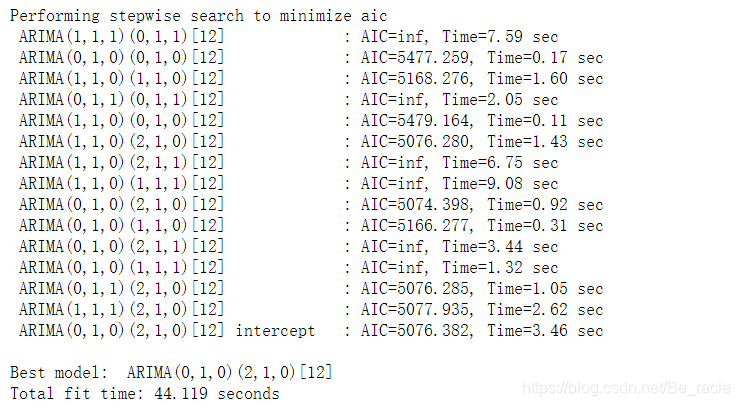
RMSE的大小一定程度上反映了误差大小。
rmse = np.sqrt(np.mean(np.power((np.array(valid['Close'])-np.array(forecast['Prediction'])),2)))
rmse
通过绘图直观地观察预测情况。
#plot
plt.figure(figsize=(16,8))
plt.plot(train['Close'])
plt.plot(valid['Close'])
plt.plot(forecast['Prediction'])
plt.show()
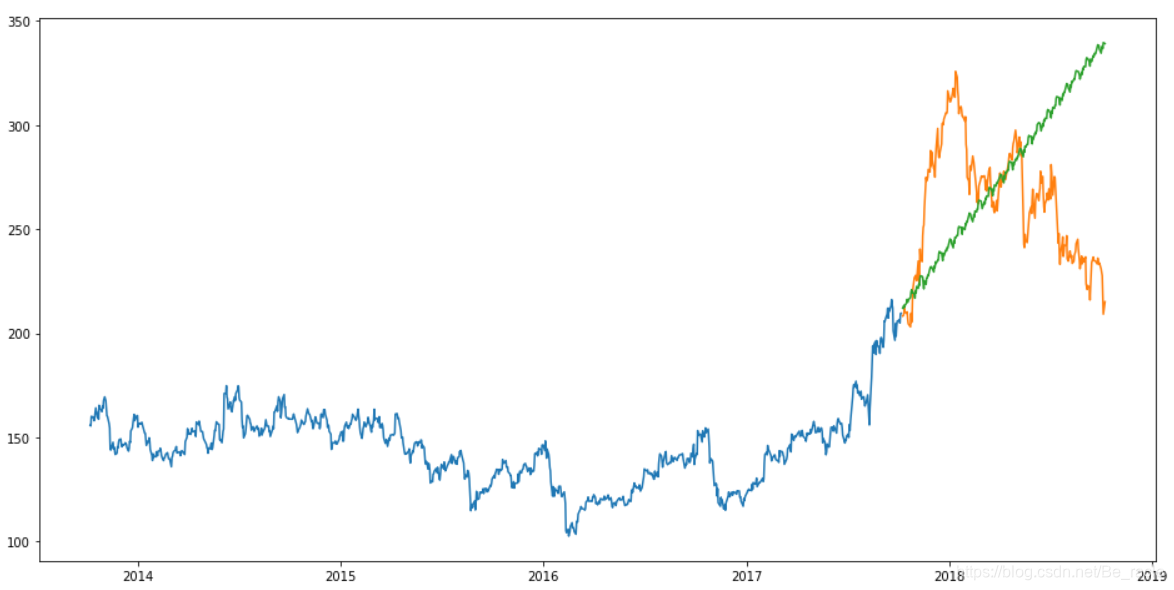
可以看到AutoARIMA算法在这个数据集上的预测效果也不是很好。但是,该模型已捕捉到该时间序列的趋势,因为并未关注季节性变化影响,所以预测得不够准确。