一、整体效果
Yarn的监控最主要是能看到目前活跃的ResourceManager,同时能够显示目前的Nodemanager的活跃情况。其次是能够看到RM和NM的可用内存、可用Cpu、GC、RPC等的监控。还有就是比如namenode挂掉就能报警等。

二、举几个案例可用自行配置
简单的配置左Y轴右Y轴的单位,rate()方法的使用等简单的操作自行百度其他文章,这些分享一些骚操作。
1、怎么显示RM的状态
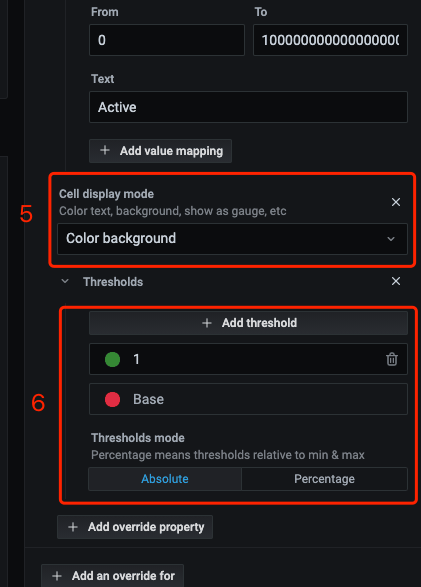
(1)首先要配置出下图这个样子

a、选择你的数据源Promethues
b、在metric里选择Hadoop_ResourceManager_AvailableMB这个metric,因为这个metric当RM为standby时他的值为0,Active大于0,所以就可以利用这个待会来做文章
c、将format改为Table
d、将Instant,这个意思是瞬时,就是基于当前最新的一个值,如果不点,就会显示历史的所有值
(2)利用上面Value的值0和不为0的值变为绿色的Active和变为红色的Standby
就不详细叙述了,跟着点就行

2、配置Nodemanager挂掉的Dashboard
这个最主要的实现功能是这个Promethues的absent这个fuction,支持instant-vector即瞬时变量就是当前的值,这个方法作用是当哪个instance没有值了就会返回向量一,详细解释见官网。有了这个function当dashboard显示某个Nodemanager的值为1,则证明此时没有值了即Nodemanager可能挂掉了,需要进行告警排查。

3、基于步骤二实现Nodemanager挂掉告警Alert
报警很简单,就是如果值大于0就说明挂了,那规则就是IS ABOVE 0;
注意:取名一个天坑,就是一定要记得当你配置哪个任务挂掉的那种类型,一定要记得把这个状态设置为Ok,某则你选其他值的话,当你的各个节点都正常,此时你的DashBoard就是显示为no data,那就会给你疯狂报警,所以配置哪个任务挂掉的那种类型的Alert记得设置为Ok。
