关于MongoDB数据库:
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
MongoDB 可在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 可为Web应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储在灵活的json文档中,这意味着可以直接得到从文档到文档的数据、结构等。
MongoDB 是免费使用的(MongoDB分 社区版[在所有环境下都免费] 和 企业版[在开发环境免费,生产环境收费]两个版本)。
MongoDB 数据库具有可伸缩性和灵活性,可帮助你快速查询和索引你需要数据。
MongoDB数据库下载:


在这里根据自己的需要,选择下载对应系统的MongoDB数据库版本(注:在MongoDB版本中,是偶数:如3.2.x、3.4.x、3.6.x表示正式版【可用于生产环境】,是奇数:3.1.x、3.3.x、3.5.x表示开发版,而OS系统版本:自动给你推荐你当前适合的MongoDB数据库版本)。
然后点击 Download按扭后,进入下载页面:

注:进入上面这个下载页面后,会自动开始下载!!!(如没反应就F5 刷新一下当前页面,由于是外网,所以就耐心点吧!)。
除了上面的下载方式以外,也可以试试下面的下载链接!!
- MongoDB Windows系统64位下载地址:http://www.mongodb.org/dl/win32/x86_64
- MongoDB Windows系统32位下载地址:http://www.mongodb.org/dl/win32/i386
- MongoDB 全部版本下载地址:http://www.mongodb.org/dl/win32
安装MongoDB数据库:
MongoDB的安装非常简单,在下载完成后,接直接双击下载好的MongoDB安装包,进入MongoDB安装界面,点击Next下一步、同意条款、选择安装路径 和 日志路径、勾选是否安装MongoDB Compass(MongoDB数据库图形管理工具,类似MySQL的Navicat ),其它的步骤一直点下一步直到完成安装就OK啦。
点击开始安装:

选择MongoDB安装方式:

选择MongoDB安装路径:

选择MongoDB数据库图形化界面管理工具:

然后就一直下一步、Next 直到 Flnish 安装完毕,到此就MongoDB就安装结束啦!

MongoDB数据库图形化管理工具:
下载地址:https://www.mongodb.com/try/download/compass

注:在MongoDB Compass选择下载时,可选择对应的系统版本(这里以windows系统为例):
- zip绿色版(免安装,解压后就可以用)
- msi安装版(Windows Installer的数据包,需要一步步安装到本地)
- exe安装版(可执行文件,需要一步步安装到本地)
下面是Msi安装版,安装界面:

MongoDB Compass的安装没有什么好配置的,直接点击 Next 至到 Flnish 就安装结束啦!

MongoDB数据库的图形化的数据库管理工具,可以在这里面对数据进行很友好的操作:如查看、编辑、导入、导出等相应的。

文件功能解释:
MongoDB v3.6版 安装目录:C:\Program Files\MongoDB\Server\3.6\bin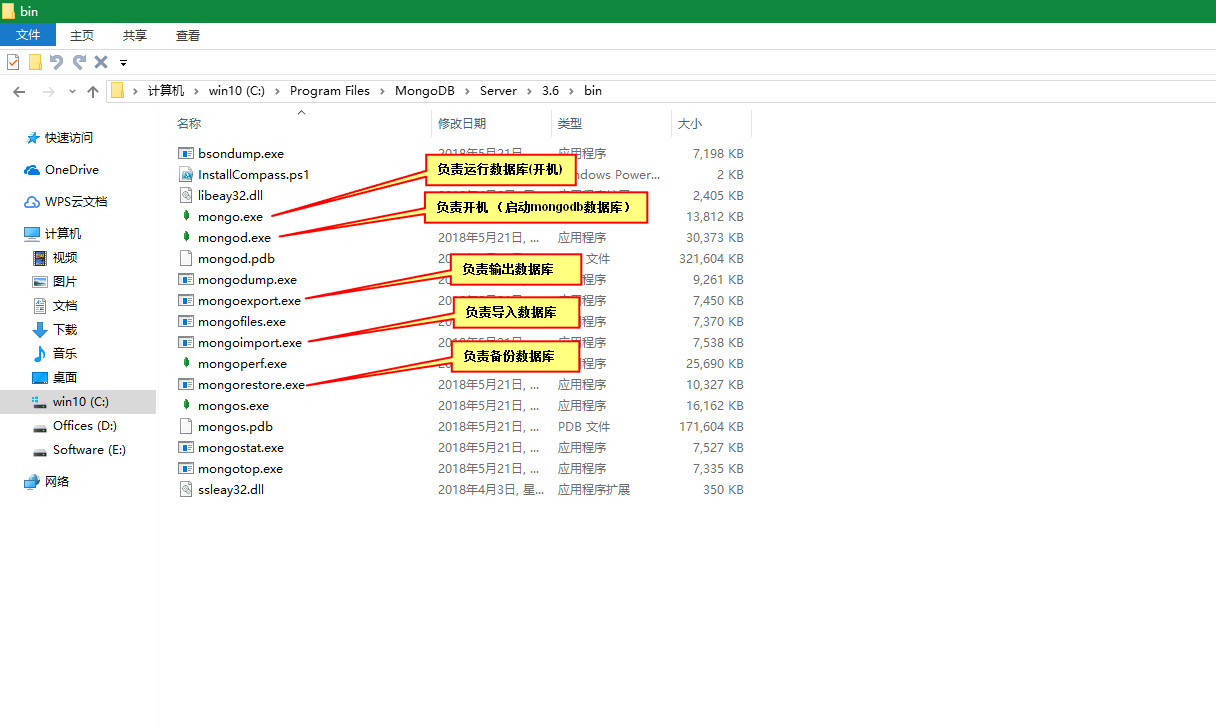
MongoDB v4.4版 安装目录:C:\Program Files\MongoDB\Server\4.4\bin
配置全局环境变量:
配置MongoDB全局环境变量(就是在电脑中任何地方都可以合用mongo、mongod等命令)!
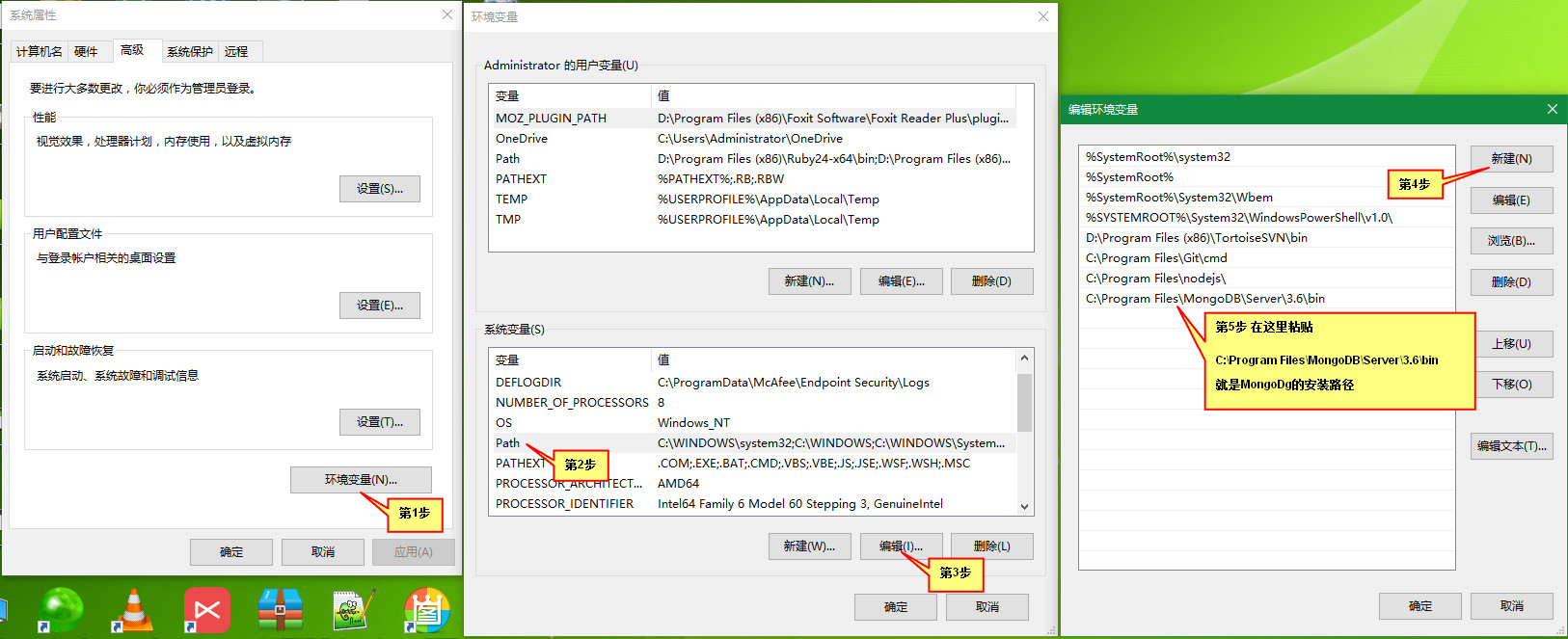
注:配置完成后,重启电脑, 环境变量才生效哦!重启后,我们就能在系统的任何位置,使用mongo命令了:
如:查看MongoDB数据库存的版本:
mongod -version
// 该命令会显示MongoDB数据库的相关信息,如果能显示信息,就表示已安装成功了!!!MongoDB数据库中的常用述语:
1、在MongoDB中,数据库是以文件形式存储的,数据库目录中存储了相应的数据库!
2、在MongoDB中,把传统数据库中的 "表" 叫作:Collections "集合"!
3、在MongoDB中,向集合存储数据时,直接以JSON格式,进行存取操作!
4、在MongoDB中,集合中的数据叫作:Documents "文档"!
进入MongoDB数据库的语法环境:
在命令窗口中,输入 mongo 回车, 就进入了MongoDB数据库的语法环境了!

MongoDB数据库常用命令:
上面就是MongoDB数据库的语法环境了,现在我们可以在命令窗口中执行一些MongoDB数据库的命令、语法啦!下面例出了一些常用的MongoDB数据库操作命令!
1、查看所有数据库:
show dbs2、查看当前所在数据库:
db3、查看当前所在数据库中所有集合:
show collections
// 查看user集合(用户表)中的所有记录
db.user.find().pretty()
// 加上.pretty() 让显示结果更友好明了!4、查看当前数据库相关信息(名称、文档个数、视图、索引、大小等):
db.stats()
5、创建、打开、切换 数据库:
use 数据库名字
// 如:use mydbuse 这个命令很特殊:
use命令具有打开、 切换、 创建数据库的功能:
- 如果打开的这个数据库存在就是打开这个数据库。
- 如果打开的是一个不存在的数据库(没有这个数据库名字),那么就会创建一个同名的数据库。
注:在MongoDB中创建一个新的数据库时,需要向数据库中创建一个集合(collections【就像关系数据库中的表】),并且插入一条数据,这个数据库才能创建成功!!
如:往集合中插入一条数据。可以不用先创建集合,直接往里添加数据即可:
db.user.insert({"name": "xiaoming"}) // user 就是集合(表)名
或
db.user.save({name:"沐枫", job:"Web前端"}) // 效果和上面一样,都是添加数据当命令执行后,数据库系统发现student是一个数据集合不存的,就自动创建一个集合,并随着数据的插入,数据库和集合也就真正的创建成功了。
6、删除数据库(注:这里是删除当前所在的数据库)
注:这个命令一定要慎用,一旦该命令一执行一下当前所在数据库中的所有数据都玩完了!!!,除非您想删库跑路,哈哈!!
db.dropDatabase()7、清屏(这是Dos的命令,当窗口中的内容太多时,可以使用该命令,清除屏幕内容,保持界面清晰):
cls8、导入数据
当要插入的数据太多时,一条一条的insert在繁琐了。所以,我们可以在代码编辑器中以JSON格式编辑好要插入的数据,以.json文件格式保存,然后导入数据库:
下面就是将mydata.json文件,导入到test数据库的student集合中。
mongoimport --db mydb --collection user --drop --file mydata.json
mongoimport 导入命令参数据说明:
--db mydb // 导入到mydb数据库
--collection user // 导入到user集合中
--drop // 导入前把集合中的数据清空
--file mydata.json // 要导入的那个json文件
一般情况是先准备要导入的json文件,然后用mongoimport命令进行导入,也可以用MongoDB Compass数据库图形管理工具中去导入、输入数据等,这里只是为了演示导入命令哦!。
9、操作帮助命令(列出MongoDB数据库所有的操作方法)
db.help()DB methods:
db.adminCommand(nameOrDocument) - switches to 'admin' db, and runs command [just calls db.runCommand(...)]
db.aggregate([pipeline], {options}) - performs a collectionless aggregation on this database; returns a cursor
db.auth(username, password)
db.cloneDatabase(fromhost)
db.commandHelp(name) returns the help for the command
db.copyDatabase(fromdb, todb, fromhost)
db.createCollection(name, {size: ..., capped: ..., max: ...})
db.createView(name, viewOn, [{$operator: {...}}, ...], {viewOptions})
db.createUser(userDocument)
db.currentOp() displays currently executing operations in the db
db.dropDatabase()
db.eval() - deprecated
db.fsyncLock() flush data to disk and lock server for backups
db.fsyncUnlock() unlocks server following a db.fsyncLock()
db.getCollection(cname) same as db['cname'] or db.cname
db.getCollectionInfos([filter]) - returns a list that contains the names and options of the db's collections
db.getCollectionNames()
db.getLastError() - just returns the err msg string
db.getLastErrorObj() - return full status object
db.getLogComponents()
db.getMongo() get the server connection object
db.getMongo().setSlaveOk() allow queries on a replication slave server
db.getName()
db.getPrevError()
db.getProfilingLevel() - deprecated
db.getProfilingStatus() - returns if profiling is on and slow threshold
db.getReplicationInfo()
db.getSiblingDB(name) get the db at the same server as this one
db.getWriteConcern() - returns the write concern used for any operations on this db, inherited from server object if set
db.hostInfo() get details about the server's host
db.isMaster() check replica primary status
db.killOp(opid) kills the current operation in the db
db.listCommands() lists all the db commands
db.loadServerScripts() loads all the scripts in db.system.js
db.logout()
db.printCollectionStats()
db.printReplicationInfo()
db.printShardingStatus()
db.printSlaveReplicationInfo()
db.dropUser(username)
db.repairDatabase()
db.resetError()
db.runCommand(cmdObj) run a database command. if cmdObj is a string, turns it into {cmdObj: 1}
db.serverStatus()
db.setLogLevel(level,<component>)
db.setProfilingLevel(level,slowms) 0=off 1=slow 2=all
db.setWriteConcern(<write concern doc>) - sets the write concern for writes to the db
db.unsetWriteConcern(<write concern doc>) - unsets the write concern for writes to the db
db.setVerboseShell(flag) display extra information in shell output
db.shutdownServer()
db.stats()
db.version() current version of the server启动 或 创建 指定的MongoDB数据库:
MongoDB数据库是以文档形式存储的,我们可以根自己的项目需要,在各自不同的项目中,指定MongoDB数据库目录(如在Vue 或 React 项目的根目录,和 package.json文件同级的目录中,创建一个名为database的文件夹)中去创建MongoDB数据库的存储目录!
使用 mongod 命令: 创建 或 启动 指定的MongoDB数据库!
mongod这个命令很特殊,和use命令一样,如果指定的目录中有数据库就是启动,没有就是创建并启动!
mongod --dbpath 数据库目录
// 如: mongod --dbpath D:\Vue\myapp\database如果mongodb数据库路径太长,要输入很久,还可这样做
1、在dos命令行中先输入以下命令:
mongod --dbpath
2、需要注意思的是,在--dbpath的后面加上一个空格
3、找到数据库所在的目录文件夹,直接将这个文件夹拖到命令窗口中去
4、此时,数据库的路径有自动有啦!!
注意:
启动成功后,一定不要关闭这个命令窗口,而且这个命令窗口中也不能再做其他操作了,然后就可以在MongoDB图形化管理工具中看查数据库 或 在项目中链接使用MongoDB数据库啦。
当然在有些时候,如果想要用命令行操作MongoDB数据库的话,就要再打开一个新Dos窗口!!!
输入mongo命令就进入了MongoDB数据库的语法环境了(一定要先启动MongoDB数据库后,在进行MongoDB数据库的操作)。

MongoDB数据库-复制集
为什么要用复制集?
为了保证数据的安全,推荐使用复制集的方式来存储数据,一般复制集节点数至少要有3个,就相当于有3个MongoDB数据库,一主两从,这样一来,即便是当主节点宕机了,其他的从节点通过投票选举(所以,一般复制集节点数量不能是偶数,不然就会出现评局的状态),选出一个新的主节点出来继续工作,而且数据也不会丢失!!
在windows系统下搭建MongoDB复制集:
1、新建MongoDB复制集节点目录,如:在D盘下的MongoDB目录下,新建3个文件夹,分别命名为:db1,db2,db3 用于存放复制集节点
2、分别在db1,db2,db3这3个文件夹中新建一个文件命名为:mongod.conf 内容如下:
# mongod.conf 文件
systemLog:
destination: file
path: D:\MongoDB\db1\mongod.log # 设置日志文件存放路径
logAppend: true
storage:
dbPath: D:\MongoDB\db1 # 数据存储目录
net:
bindIp: 0.0.0.0 # 数据库地址:0.0.0.0 表示所有
port: 28017 # 数据库端口号
replication:
replSetName: rs0 # 复制集节点名称注:
* path 和 dbPath 配置项中的路径一定要和当前所有的目录名对应!如:db1,db2,db3
* port 数据库端口号也不能重复!如:28017,28018,28019如:db2目录下的mongod.conf 内容如下
# mongod.conf 文件
systemLog:
destination: file
path: D:\MongoDB\db2\mongod.log # 设置日志文件存放路径
logAppend: true
storage:
dbPath: D:\MongoDB\db2 # 数据存储目录
net:
bindIp: 0.0.0.0 # 数据库地址:0.0.0.0 表示所有
port: 28018 # 数据库端口号
replication:
replSetName: rs0 # 复制集节点名称3、启动复制集节点
注:由于windows系统不支持fork,以所要分别用不同的命令窗口来启动,如这里有3个复制集节点,所有就要开3个命令窗口来打开,这样就会启动3个mongodb进程,并且启动后不能关闭该命令窗口,否则进程也会随之结束!!
# 命令窗口1
mongod -f D:\MongoDB\db1\mongod.conf
# 命令窗口2
mongod -f D:\MongoDB\db2\mongod.conf
# 命令窗口3
mongod -f D:\MongoDB\db3\mongod.conf通过以上命令启动好3个复制集节点后,可以在命令窗口中查看,mongodb的进程情况
ps mongo4、关联复制集节点
上面虽然创建了3个复制集节点,但它们之间还没有任何关系,还是相互独立的,所以要将们关联起来,当有数据入后3个节点都会有数据,这样一来,即便是当主节点宕机了,其他的从节点通过投票选举(所以,一般复制集节点数量不能是偶数,不然就会出现评局的状态),选出一个新的主节点出来继续工作,而且数据也不会丢失!!
-
再新开一个命令窗口操作,在windows系统中查看当前hostname 主机名
hostname # MuGuiLin //这是我在windows系统中查看当前hostname 主机名注:如果各个复制集节点之间不是在同一台服务器上(当然推荐分开部署,这里为了演示所以就在一台电脑上),就需要对应的服务器IP 或域名
-
然后进入28017节点
mongo localhost:28017 -
设置复制集主节点,在没有设置复制集主节点之前,各个节点都是一样平级的,但一般情况下,我们都将第1个端口号的节点做为主节点!
rs.initiate() # 执行以上命令后就进入复制集节点状态了 rs0:SECONDARY> 回车 # 默认是从节点状态,按回车键可切换到主节点状态 rs0:PRIMARY> # PRIMARY 表示进入主节点状态了 -
查看复制集节点状态信息 和 配置信息
rs0:PRIMARY>rs.status() rs0:PRIMARY>rs.config() # 通过以上命令可以查看复制集节点的相关信息,其中"members":[...] 数组中就是各个节点的信息,由于还没有关联其他的节点,所以现在只有一个 -
分别关联端口为28018 和 28019 的这两个复制集节点
rs0:PRIMARY>rs.add("MuGuiLin:28018") rs0:PRIMARY>rs.add("MuGuiLin:28019") # 执行以上命令后,再查看复制集节点,在"members":[] 数组中应该就有3个节点信息了 rs0:PRIMARY>rs.status()到此复制集节点的关联工作就完成了!
5、查看从节点是否正常同步数据
1、先在28017主节点上插入一条数据
# 进入28017节点
mongo localhost:28017
# 查看所以数据库
rs0:PRIMARY>show dbs
# 向test数据库中的test集合插入一条数据
rs0:PRIMARY>db.test.insert({name: "OK 666 MongoDB 数据库 复制集"})
# 查看当前数据库下的所有集合
rs0:PRIMARY>show collections
# 查看test集合中的所有数据
rs0:PRIMARY>db.test.find().pretty()writeConcern 数据写入配置:
注意:默认情况下插入数据时只要写入主节点(不管是否同步到从节点)就返回提示数据写入成功。
所以:如果要保证在写入数据时,所的的节点 或 指定的节点都落盘(成功写入)后,才返回提示数据写入成功。
writeConcern 决定一个写操作落到多少个节点上才算成功。writeConcern 的取值包括:
- 0 表示发起写操作,不关心是否成功;
- 1~集群最大数据节点数 表示写操作需要被复制到指定节点数才算成功;
- majority 表示写操作需要被复制到大多数节点上才算成功。 发起写操作的程序将阻塞到写操作到达指定的节点数为止
例如:指定写入3个节点才算成功
rs0:SECONDARY>db.test.insert({name: "插入一条测试数据 -> 我要等3个复制集节点都插入成功了,我才返回功能!"},{writeConcern:{w:3}})
# writeConcern 参数说明:
w: 节点数
w: "majority" # 大多数节点确认模式(一半以上: 共3有个节点,只要2个节点写入成功即可)
w: "all" # 全部节点确认模式
writeConcern中的另一个参数:j 可以决定写操作到达多少个节点才算成功,journal 则定义如何才算成功。
取值包括:
j: true 表示写操作落到 journal 文件中才算成功!
j: false 表示写操作到达内存即算作成功!writeConcern注意事项:
- 虽然多于半数的 writeConcern 都是安全的,但通常只会设置 majority,因为这是 等待写入延迟时间最短的选择;
- 不要设置 writeConcern 等于总节点数,因为一旦有一个节点故障,所有写操作都 将失败;
- writeConcern 虽然会增加写操作延迟时间,但并不会显著增加集群压力,因此无论 是否等待,写操作最终都会复制到所有节点上。设置 writeConcern 只是让写操作 等待复制后再返回而已;
- 应对重要数据应用 {w: “majority”},普通数据可以应用 {w: 1} 以确保最佳性能;
2、在从节点28018 或 28019中查看是否有数据同步过来
# 进入28019节点
mongo localhost:28019
# 开启从节点读的权限,默认情况下,从节点是不能读取的,所以要开启读的权限rs.slaveOk()
rs0:SECONDARY> rs.slaveOk()
# 查看test集合中的所有数据
rs0:SECONDARY>db.test.find().pretty()
# 执行以上查看命令后,如果能够正常显示在主节点28017上插入的数据,就表示数据已经同步过来啦!!!注:由于所有点节点都是在同一个电脑上或在同一个局域网内的,节点之间的数据同步速度是非常快的,一般在10ms内就能同步完成,如果是跨区域的、或是在不同的数据中心的,会受物理条件的影响,同频时间可能会延时长一点!!
MongoDB数据库-模型设计
什么是数据模型?
数据模型是一组由符号、文本组成的集合,用以准确表达信息,达到有效交流、沟通的目的。
数据模型的三要素:
实体、属性、关系
基础的建模实际上就是对关系的各种表达:1:1 (一对一),1 :N (一对多),M :N (多对多);
而在MongoDB的文档中基本上都可以用内嵌方式、数据方式来完成这些关系的表述,就不用像传统的关系型数据库去做分表存储啦!而且:MongoDB也可以进行分集合(表)存储的哦!!!;
// 可以用对象、数组来处理一对多 或 多对多的关系
{
"username": "沐枫",
"sex": "男",
"job": "Web全栈",
"image": {
"live": "https:www.xxx.com/update/xxx.jpg",
"travel": "https:www.xxx.com/update/xxx.jpg",
"working": "https:www.xxx.com/update/xxx.jpg"
},
"addresses": [
{"type": "住址"},
{"type": "公司"},
{"type": "老家"}
],
"hobbys": [
{"name": "打球"},
{"name": "看书"},
{"name": "上网"},
{"name": "旅游"}
]
}上面这种处理方式虽然好用,但是 例如:当hobby子文档数据量很多时,数据就会很冗余,好的是MongoDB从3.2版开始也可以进行分集合(表),将hobby文档抽离成一个独立的集合user_hobby,然后进行关联查询!
// users集合 把原来的users集合中的hobbys字段抽离到独立的user_hobby集合中
{
"username": "沐枫",
"sex": "男",
"job": "Web全栈",
"image": {
"live": "https:www.xxx.com/update/xxx.jpg",
"travel": "https:www.xxx.com/update/xxx.jpg",
"working": "https:www.xxx.com/update/xxx.jpg"
},
"addresses": [
{"type": "住址"},
{"type": "公司"},
{"type": "老家"}
],
"hobbys": [1, 2, 3, 4]
}
// 新抽离出来的user_hobby集合
{
{hobby_id": 1, "name": "打球"},
{hobby_id": 2, "name": "看书"},
{hobby_id": 3, "name": "上网"},
{hobby_id": 4, "name": "旅游"}
}通过引用方式 aggregate聚合框架中的 $lookup操作符 来进行关联查询
例如:users集合 和 user_hobby集合 将这两个集合进行关联查询
// users集合关联user_hobby集合
db.users.aggregate([
{
$lookup:
{
from: "user_hobby", //目标关联集合
localField: "hobbys", //当前集合要关联的字段
foreignField: "hobby_id", //目标集合要关联的字段
as: "new_hobby" //查询后返回数据存放的字段名(这是动态生成的,在原来的users集合中是不存在的)
}
},
{
// ... 如果还有更多的集合需要关联查询,还可以继续关联查询下去。。。!
}
])
什么时候才应该使用引用方式(拆分集合(表)):
- 当内嵌文档(子文档)太大时,如数量很多 或 占用空间超过16MB时(目前最大限度16MB);
- 当内嵌文档 或 数组等元素会频繁更新修改时;
- 当内嵌数组中的元素数量是未知的(后期可以会持续增加,没有封顶)时;
MongoDB 引用是有限制的:
- MongoDB 对使用引用的集合之间并无主外键检查;
- MongoDB 使用聚合框架的 $lookup 来模仿关联查询;
- $lookup 只支持 left outer join
- $lookup 的关联目标(from)不能是分片集合(表);
数据模型的三层深度:
概念模型,逻辑模型,物理模型
传统数据库模型设计:从概念到逻辑到物理,它们之间其实就是从概念模型 到 物理模型 的一个逐步细化的过程!
| 项目 | 概念模型 CDM | 逻辑模型 LDM | 物理模型 PDM |
| 目的 | 描述业务系统要管理的对 象 | 基于概念模型,详细列出 所有实体、实体的属性及 关系 | 根据逻辑模型,结合数据库 的物理结构,设计具体的表 结构,字段列表及主外键 |
| 特点 | 用概念名词来描述现实中 的实体及业务规则,如 “联系人” | 基于业务的描述 和数据库无关 | 技术实现细节 和具体的数据库类型相关 |
| 主要使用者 | 用户 需求分析师 | 需求分析师 架构师及开发者 | 开发者 DBA |
MongoDB 文档模型设计的三个误区 :
- 不需要模型设计
- MongoDB 应该用一个超级大文档来组织所有数据
- MongoDB 不支持关联或者事务
所以严格来讲,MongoDB 同样需要概念/逻辑建模的,文档模型设计的物理层结构可以和逻辑层类似,可以省略物理建模的具体过程。
关系模型 VS 文档模型:
| 项目 | 关系数据库 | JSON 文档模型 |
| 模型设计层次 | 概念模型 逻辑模型 物理模型 |
概念模型 逻辑模型 |
| 模型实体 | 表 | 集合 |
| 模型属性 | 列 | 字段 |
| 模型关系 | 关联关系,主外键 | 内嵌数组,引用字段 |
MongoDB数据的操作:(和关系型数据库一样,就是增、删、查、改)
1、插入数据:insert()、insertOne()、insertMany()
语法:
db.<集合>.insertOne(<JSON对象>)
db.<集合>.insertMany([<JSON 1>,<JSON 2>,<JSON 3>,...<JSON n>])
- 插入数据:这里以student集合【学生表】为例!
db.student.insert({"name": "muguilin", "age": 28, "sex": "男", job: "Web前端"});
// 插入1条数据
db.student.insertOne({"name": "muguilin", "age": 28, "sex": "男", job: "Web前端"});
// 插入多条数据
db.student.insertMany([
{"name": "zhangsan", "age": 32, "sex": "男", job: "JAVA"},
{"name": "lisi", "age": 28, "sex": "女", job: "PHP"},
{"name": "wanger", "age": 16, "sex": "男", job: "Web前端"},
]);2、查找数据:find()
语法:
db.<集合>.find(<查询条件>)
find()还支持合用 field.sub_field 的形式查询子文档
- 查找数据,如果find()中没有参数,那么将列出这个集合中的所有文档:注:find()返回的是游标
db.student.find()
//相当于下面关系数据库中的语法:
select * from test.student
// 在查询返回的结果后面加上.prettys()方法可以让显示效果更友好!
db.student.find().pretty()- 指定查询返回的字段 (例如:查询学生集合(表)中所有的女同学,不显示id,只显示名字 和 年龄 <字段名:0不显示,1显示>)
db.student.find({sex: "女"}, {_id:0, name: 1, age: 1});- 子文档查询
db.student.find({"score.shuxue": 60 });
// 子文档查询
db.student.find({"score": {"shuxue": 60 }});
// 多个子文档查询 $elemMatch 表示必须是同一个子对象满足多个条件
db.student.find({"score": {$elemMatch: {"yuwen": 80, "shuxue": 60, "yinyu": 70 });
条件查询:
- 精确匹配查询:
db.student.find({"uid":"u10010"});
或:
db.student.find({"name":"沐枫"});- 多条件查度
// 多条件and查询
db.student.find({"score":70 , "age":12})
// and查询的另一种形式
db.student.find({$and: [{"score":70}, {"age":12 }]})
// 多条件or查询
db.student.find({$or: [{"score":80}, {"age":16 }]})
// 大于查询
db.student.find({"score":{$gt:60}})
// 正则表达式查询(查找名字中以 “沐” 开头的记录)
db.student.find({"name": /^沐/g})- 条件查询对照:(MongoDB 与 传统数据库 比对)
| SQL(MySql、SqlServer) | MQL(MongoDB) | ||
| a = 1 | 等于 | { a : 1} | 等于 |
| a <> 1 | 不等于 | { a : { $ne : 1 }} | 不等于 $ne:不存在 或 存在 但 不等于 |
| a > 1 | 大于 | { a : { $gt : 1 }} | 大于 $gt:存在 并 大于 |
| a >= 1 | 大于等于 | { a : { $gte : 1 }} | 大于等于 $gte:存在 并 大于等于 |
| a < 1 | 小于 | { a : { $lt : 1 }} | 小于 $lt:存在 并 小于 |
| a <= 1 | 小于等于 | { a : { $lte : 1 } } | 小于等于 $lte:存在 并 小于等于 |
逻辑查询:
- 逻辑与 并且:$and
db.student.find({"score":60})
// 另一种and形式
db.student.find({$and:[{"score":60 , "age":12}, {"score":80 , "age":15}]})- 逻辑或:$or(只需满足1个条件),查找所有年龄是9岁,或者11岁的学生
db.student.find({$or:[{"age":9}, {"age":11}]})- 查询逻辑对照:(MongoDB 与 传统数据库 比对)
| SQL(MySql、SqlServer) | MQL(MongoDB) | ||
| a = 1 AND b = 1 | 并且 | { a : 1,b : 1 } 或者是 { $and : [ { a : 1 }, { b :1 } ] } | 并且 $and:匹配所有指定条件 |
| a =1 OR b = 1 | 或 | { $or : [ { a : 1 } , { b : 1 } ] } | 或 $or:匹配指定的2个 或 多个条件中的1个 |
| a IS NULL | 不存在 | { a : { $exists : false } } | 不存在 |
| a IN (1,2,3) | 存在 | { a : { $in: [1, 2, 3] } } | 存在 $in:存在 并 并在指定的数组中 不存在 $nin:不存在 或 不在指定的数组中 |
聚合查询:
MongoDB聚合框架(Aggregation Framework)是一个计算框架,它可以:
- 可作用在一个 或 几个集合上
- 对集合中的数据进行一系列的运算
- 可将数据转化为所期望数据形式,如(数学计算,统计,类型,格式处理等)
对效果而言,聚合查询相录于传统SQL查询中的,ORDER BY,GROUP BY,LIMIT,LEFT OUTER JOIN,AS等!
- 聚合查询对照:(MongoDB 与 传统数据库 比对)
| 步骤 | 作用 | SQL等价运算符 |
| $match | 过滤 | WhERE |
| $project | 投影 | AS |
| $sort | 排序 | ORDER BY |
| $group | 分组 | GROUP BY |
| $skip | 结果限制 | SKIP |
| $limit | 结果限制 | LIMIT |
| $lookup | 左外连接(多表操作) | LEFT OUTER JOIN |
| $graphLookup | 图搜索 | N/A |
| $facet | 分面搜索 | N/A |
| $bucket | 分面搜索 | N/A |
| $unwind | 展开数组 | N/A |
- 升降排序查找:
db.student.find().sort({"score": 1, "age": 1});- 展开数据查询:查询某个学生各个学科的成绩
db.student.aggregate([{$unwind: '$score'}])- 查询结果限制: 例如:查询学生集合(表)中的所有女生的姓名和年龄!
db.student.aggregate([
{$match: "sex": "女"}, // 只取性别为女性的
{$skip: 100}, // 跳过100条
{$limit: 30}, // 只取30条
// 只返回姓名 和 年龄这两个字段
{$project: {
'姓名': 'name',
'年龄': 'age'
}}
])
3、修改数据:update()
语法:
db.<集合>.update(<查询条件>,<更新字段>)
db.<集合>.updateOne(<查询条件>,<更新字段>) 表示无论条件匹配多少记录,始终只更新第1条记录
db.<集合>.updateMany([<查询条件>,<更新字段>]) 表示 条件匹配多少条 就 更新多少条
注:在修改(更新)时,如果要更新的字段名存在 则更新数据,如果不存在 则创建并写入数据!!
注:update(),updateOne(),updateMany() 方法要求更新条件部分必须具有以下参数之一,否则就报错!!
| 参数 | 说明 |
| $set | 增加 |
| $unset | 删除 |
| $push | 增加一个对象到数组底部 |
| $pushAll | 增加多个对象到数组底部 |
| $pop |
从数组底部删除一个对象 |
| $pull | 如果匹配到指定的值,从数组中删除相应的对象 |
| $pullAll | 如果匹配任意值,从数组中删除相应的对象 |
| $addToSet | 如果不存在就增加一个值到数组 |
- 修改名字叫做小明的,把年龄更改为16岁:
db.student.update({"name":"小明"},{$set:{"age":16}});- 查找数学成绩是70,把年龄更改为33岁:
db.student.update({"score.shuxue":70},{$set:{"age":33}});- 更改所有匹配项【默认情况下,update()方法是更新单个文档。 要更新多个文档,请使用开启update()方法中的multi选项】
db.student.update({"sex":"男"},{$set:{"age":33}},{multi: true});- 完整替换,不出现$set关键字了:
db.student.update({"name":"小明"},{"name":"大明","age":16});4、删除数据:remove()
语法:
db.<集合>.remove(<查询条件>)
注:remove() 命令需要配合查询条件使用,只要匹配到的文档就会被删除!!
- 删除实例:
// 指定删除 名字等于 小明的记录
db.student.remove({"name":"小明"})
// 删除 数学成绩 小于 60 以下的记录
db.student.remove({"score.shuxue": {$lt: 60 })
// 删除 student集合中所有的记录!!!
db.student.remove({})
// 语法错误
db.student.remove()- 默认情况下,remove()方法将删除所有符合删除条件的文档。 使用开启justOne选项将删除操作限制为仅匹配文档之一。
db.student.remove({"name":"小明"}, {justOne: true});5、删除集合:drop()
语法:
db.<集合>.drop()
注:删除后集合中的所以文档、以及相关的索引等都会被删除!!
// 删除学生集合(删除学生表)
db.student.drop()在Node.js中使用MongoDB数据库
Node.js 和 MongoDB 可以说是黄金搭配,再加上它们各自都比较成熟的第三方框架,如:Express,Koa, Egg 以及 Mongoose 等等,有了它们,就可以在各种复杂项目场景中使用啦!