1、这个报错是什么意思?
官方文档对于TypeError的解释是:
Raised when an operation or function is applied to an object of inappropriate type. The associated value is a string giving details about the type mismatch.
This exception may be raised by user code to indicate that an attempted operation on an object is not supported, and is not meant to be. If an object is meant to support a given operation but has not yet provided an implementation, NotImplementedError is the proper exception to raise.
Passing arguments of the wrong type (e.g. passing a list when an int is expected) should result in a TypeError, but passing arguments with the wrong value (e.g. a number outside expected boundaries) should result in a ValueError.
我知道很多人不看英文
当一个类型不匹配的对象传入某一操作或者函数中时,就会导致TypeError异常(哈哈哈,说得对,又有点像废话 ̄□ ̄||)。错误提示后面会显示跟错误匹配的对象的类型细节信息(比如: ‘int’ object is not iterable,就是细节信息)。
这个报错产生的原因可能是程序试图对一个不支持的对象进行操作,虽然可能写代码的人愿意并非如此。当向操作中传入一个并未声明的对象时,NotImplimentedError这个错误类型才是合适的报错。
传入类型错误的参数,比如当需要传入整型时,却传入列表,那么就会导致TypeError报错。但是,当需要传入int,不过传入的数据超过设定的范围,那么就会导致ValueError报错。(这段就说得比较具体了。)
2、书中pandas实现多个excel表格列表数据加总和求平均值的代码报错
直接贴代码吧,这是照着书中代码打的:
ps.如果需要练习用的excel表格,可以私我。
import pandas as pd
import glob
import os
input_path = 'Your file directory' # 输入自己的文件夹路径
output_file = 'pandas_ouput.xls'
all_workbooks = glob.glob(os.path.join(input_path, '*.xls*'))
data_frames = []
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook, sheet_name=None, index_col=None)
workbook_total_sales = []
workbook_num_of_sales = []
worksheet_data_frames = []
worksheets_data_frame = None
workbook_data_frame = None
for worksheet_name, data in all_worksheets.items():
total_sales = pd.DataFrame([float(str(value).strip('$').replace(',', ''))
for value in data.loc[:,'Sale Amount']]).sum()
num_of_sales = len(data.loc[:, 'Sale Amount'])
average_sales = pd.DataFrame(total_sales / num_of_sales)
workbook_total_sales.append(total_sales)
workbook_num_of_sales.append(num_of_sales)
data = {
'workbook':os.path.basename(workbook),
'worksheet':worksheet_name,
'worksheet_total':total_sales,
'worksheet_average':average_sales}
worksheet_data_frames.append(pd.DataFrame(data))
worksheets_data_frame = pd.concat(worksheet_data_frames, axis=0, ignore_index=True)
workbooks_total = pd.DataFrame(workbook_total_sales).sum()
workbooks_num_of_sales = pd.DataFrame(workbook_num_of_sales).sum()
workbooks_averages = pd.DataFrame(workbooks_total / workbooks_num_of_sales)
workbook_data = {
'workbook':os.path.basename(workbook),
'workbook_total':workbooks_total,
'workbook_average':workbooks_averages}
workbook_data = pd.DataFrame(workbook_data,
columns=['workbook', 'workbook_total', 'workbook_average'])
workbook_data_frame = pd.merge(worksheets_data_frame, workbook_data, on='workbook', how='left')
data_frames.append(workbook_data_frame)
all_data = pd.concat(data_frames, axis=0, ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data.to_excel(writer, sheet_name='sums_and_averages', index=None)
writer.save()
报错:
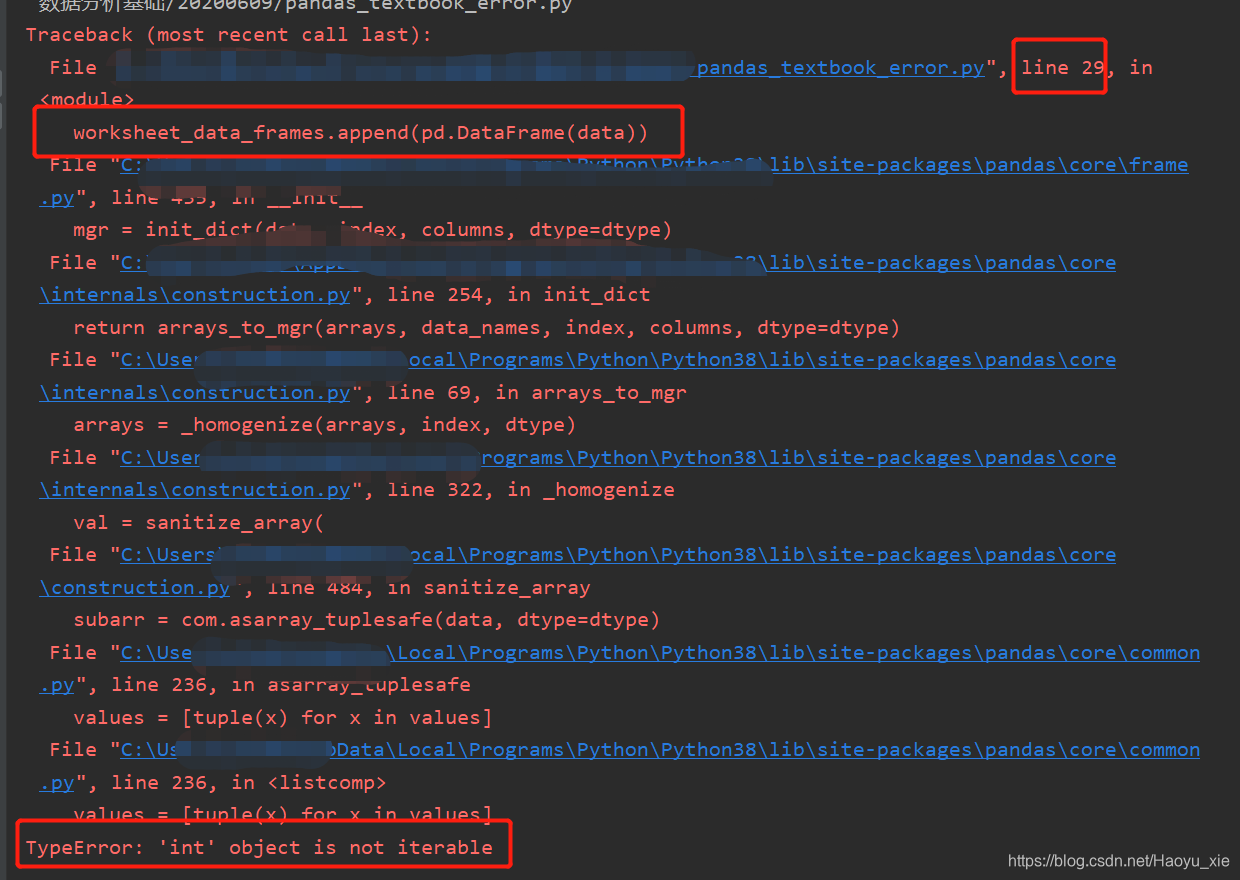
1)报错分析:
a. 既然是这段代码出错,说明data的数据类型不对
detail的意思是:整型对象无法迭代。
worksheet_data_frames.append(pd.DataFrame(data))
b. 继续往上看:
data = {
'workbook':os.path.basename(workbook),
'worksheet':worksheet_name,
'worksheet_total':total_sales,
'worksheet_average':average_sales}
由此可见,data变量是字典类型。字典类型是可迭代。
所以问题应该是处在data中的某个变量上。
而,由于worksheet_name是在for语句中定义的,因而它是一个字符串,报错显示是int错误传入。所以先排除worksheet_name变量的错误。
那么,问题就锁定在total_sales和average_sales上。下面print()一下,看看这俩货是什么玩意儿。
c.两个问题变量是这样计算和定义的:
total_sales = pd.DataFrame([float(str(value).strip('$').replace(',', ''))
for value in data.loc[:,'Sale Amount']]).sum()
num_of_sales = len(data.loc[:, 'Sale Amount'])
average_sales = pd.DataFrame(total_sales / num_of_sales)
print(total_sales, '\n', type(total_sales))
print(num_of_sales,'\n', type(num_of_sales))
print(average_sales, '\n', type(average_sales))
注意:total_sales变量中,用一个列表生成式来将原本是货币类型的excel表格数据转化可以计算的浮点型数据(实际上这是没有必要的,print就知道了。)
运行结果
0 8992.0
dtype: float64
<class ‘pandas.core.series.Series’>
6
<class ‘int’>
0
0 1498.666667
<class ‘pandas.core.frame.DataFrame’>
运行结果分析
- total_sales是一个pandas的数据类型,相当于一个列,是可以进行迭代的。因而错不在total_sales
- num_of_sales统计计算行数,为计算average_sales做铺垫
- 而average_sales就有意思了,它的数据类型是一个DataFrame,是一个数据结构对象,是不可以进行迭代的。
由此得出思路
去掉变量average_sales的变量计算中,去掉pd.DataFrame(),不用将average_sales声明为一个数据表格变量。
修改代码为:
average_sales = total_sales / num_of_sales
print(type(average_sales))
运行结果
不报错了,显示:
<class ‘pandas.core.series.Series’>,这是一个可迭代类型,于是就可以构建data数据结构了。
2)修改之后的代码:
直接提贴上来吧:
import pandas as pd
import glob
import os
input_path = 'Your file directory'
output_file = 'pandas_ouput.xls'
all_workbooks = glob.glob(os.path.join(input_path, '*.xls*'))
data_frames = []
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook, sheet_name=None, index_col=None)
workbook_total_sales = []
workbook_num_of_sales = []
worksheet_data_frames = []
worksheets_data_frame = None
workbook_data_frame = None
for worksheet_name, data in all_worksheets.items():
total_sales = pd.DataFrame([float(str(value).strip('$').replace(',', ''))
for value in data.loc[:,'Sale Amount']]).sum()
num_of_sales = len(data.loc[:, 'Sale Amount'])
average_sales = total_sales / num_of_sales
print(type(average_sales))
workbook_total_sales.append(total_sales)
workbook_num_of_sales.append(num_of_sales)
data = {
'workbook':os.path.basename(workbook),
'worksheet':worksheet_name,
'worksheet_total':total_sales,
'worksheet_average':average_sales}
worksheet_data_frames.append(pd.DataFrame(data))
worksheets_data_frame = pd.concat(worksheet_data_frames, axis=0, ignore_index=True)
workbooks_total = pd.DataFrame(workbook_total_sales).sum()
workbooks_num_of_sales = pd.DataFrame(workbook_num_of_sales).sum()
workbooks_averages = workbooks_total / workbooks_num_of_sales
workbook_data = {
'workbook':os.path.basename(workbook),
'workbook_total':workbooks_total,
'workbook_average':workbooks_averages}
workbook_data = pd.DataFrame(workbook_data,
columns=['workbook', 'workbook_total', 'workbook_average'])
workbook_data_frame = pd.merge(worksheets_data_frame, workbook_data, on='workbook', how='left')
data_frames.append(workbook_data_frame)
all_data = pd.concat(data_frames, axis=0, ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data.to_excel(writer, sheet_name='sums_and_averages', index=None)
writer.save()
总结一下:
- 用好Python官方Docs,英语好的优势体现在这儿了。英语不好的,适当学一学也是可以看懂的,加油!
- 对于错误,也是先插Docs,看看这个错误是什么意思,可能是因为什么导致的,然后再去分析代码,找错误的原因。
- print()大法真的好用,检查报错的一把好手。