表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
在读取时,引擎只需要输出所请求的列,但在某些情况下,引擎可以在响应请求时部分处理数据。对于大多数正式的任务,应该使用MergeTree族中的引擎。
1 日志系列
具有最小功能的轻量级引擎。当您需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的。
1.1 StripeLog
在你需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。
-- 建表
CREATE TABLE stripe_log_table(
timestamp DateTime,
message_type String,
message String)ENGINE = StripeLog ;
-- 插入数据
INSERT INTO stripe_log_table VALUES (now(),'Title','多易教育') ;
INSERT INTO stripe_log_table VALUES (now(),'Subject','大数据'),(now(),'WARNING','学大数据到多易教育') ; 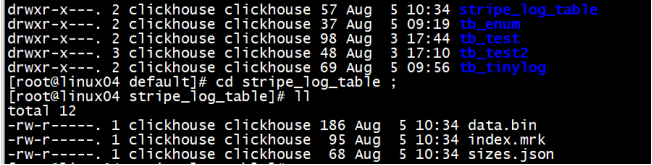
StripeLog 引擎将所有列存储在一个文件中。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。
ClickHouse 为每张表写入以下文件:
data.bin — 数据文件。
index.mrk — 带标记的文件。标记包含了已插入的每个数据块中每列的偏移量。
StripeLog 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
读数据
带标记的文件使得 ClickHouse 可以并行的读取数据。这意味着 SELECT 请求返回行的顺序是不可预测的。使用 ORDER BY 子句对行进行排序。
我们使用两次 INSERT 请求从而在 data.bin 文件中创建两个数据块。
ClickHouse 在查询数据时使用多线程。每个线程读取单独的数据块并在完成后独立的返回结果行。这样的结果是,大多数情况下,输出中块的顺序和输入时相应块的顺序是不同的。例如:
select * from stripe_log_table ;
1.2 TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。
该引擎没有并发控制,不允许并发操作
- 只支持并发读
- 如果同时从表中读取和写入数据,则读取操作将抛出异常;
- 如果同时写入多个查询中的表,则数据将被破坏。
-- 建表
create table tb_tinylog(id Int8 , name String , age Int8) engine=TinyLog ;
-- 插入数据
insert into tb_tinylog values(1,'马云',56),(2,'马化腾',55),(3,'马克思',123) ;
-- 查询数据
SELECT * FROM tb_tinylog
┌─id─┬─name───┬─age─┐
│ 1 │ 马云 │ 56 │
│ 2 │ 马化腾 │ 55 │
│ 3 │ 马克思 │ 123 │
└────┴────────┴─────┘查看磁盘中存储的数据
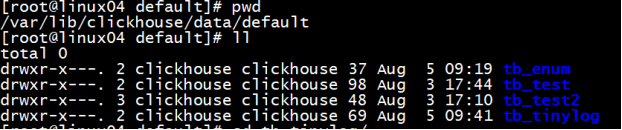
数据存储在机器的磁盘上,每列一个文件,插入数据向列文件的后面追加

再插入一条数据后, 存储列数据的文件的大小增加了

age.bin 和 id.bin,name.bin 是压缩过的对应的列的数据,sizes.json 中记录了每个 *.bin 文件的大小:
cat sizes.json
{"yandex":{"age%2Ebin":{"size":"56"},"id%2Ebin":{"size":"56"},"name%2Ebin":{"size":"87"}}
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。此引擎适用于相对较小的表(建议最多1,000,000行)。如果有许多小表,则使用此表引擎是适合的,因为它比需要打开的文件更少。当拥有大量小表时,可能会导致性能低下。 不支持索引。
1.3 Log
日志与 TinyLog 的不同之处在于,«标记» 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log 引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。Log 引擎适用于临时数据,write-once 表以及测试或演示目的。
-- 建表
create table tb_log(id Int8 , name String , age Int8) engine=Log ;
--插入数据
insert into tb_log values(1,'马云',56),(2,'马化腾',55),(3,'马克思',123) ;
insert into tb_log values(4,'Hangge',26),(5,'Taoge',35),(6,'Xingge',45) ;
1.4 总结
共同属性
数据存储在磁盘上。
写入时将数据追加在文件末尾。
不支持突变操作。
不支持索引。
这意味着 `SELECT` 在范围查询时效率不高。
非原子地写入数据。
如果某些事情破坏了写操作,例如服务器的异常关闭,你将会得到一张包含了损坏数据的表。
差异
Log 和 StripeLog 引擎支持:
并发访问数据的锁。
`INSERT` 请求执行过程中表会被锁定,并且其他的读写数据的请求都会等待直到锁定被解除。如果没有写数据的请求,任意数量的读请求都可以并发执行。
并行读取数据。
在读取数据时,ClickHouse 使用多线程。 每个线程处理不同的数据块。
Log 引擎为表中的每一列使用不同的文件。StripeLog 将所有的数据存储在一个文件中。因此 StripeLog 引擎在操作系统中使用更少的描述符,但是 Log 引擎提供更高的读性能。
TinyLog 引擎是该系列中最简单的引擎并且提供了最少的功能和最低的性能。TingLog 引擎不支持并行读取和并发数据访问,并将每一列存储在不同的文件中。它比其余两种支持并行读取的引擎的读取速度更慢,并且使用了和 Log 引擎同样多的描述符。你可以在简单的低负载的情景下使用它。
2 MergeTree系列
MergeTree系列的表引擎是ClickHouse数据存储功能的核心。它们提供了用于弹性和高性能数据检索的大多数功能:列式存储,自定义分区,稀疏的主索引,辅助数据跳过索引等。
基本MergeTree表引擎可以被认为是单节点ClickHouse实例的默认表引擎,因为它在各种用例中通用且实用。
对于生产用途,ReplicatedMergeTree是必经之路,因为它为常规MergeTree引擎的所有功能增加了高可用性。一个额外的好处是在数据提取时自动进行重复数据删除,因此如果在插入过程中出现网络问题,该软件可以安全地重试。
MergeTree系列的所有其他引擎为某些特定用例添加了额外的功能。通常,它是作为后台的其他数据操作实现的。
MergeTree引擎的主要缺点是它们很重。因此,典型的模式是没有太多。如果您需要许多小表(例如用于临时数据)
2.1 MergeTree
2.1.1 基本语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2)
ENGINE = MergeTree()ORDER BY expr[PARTITION BY expr][PRIMARY KEY expr][SAMPLE BY expr][TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...][SETTINGS name=value, ...]2.1.2 参数解读
ENGINE—引擎的名称和参数。ENGINE = MergeTree()。该MergeTree引擎没有参数。
ORDER BY —排序键
列名称或任意表达式的元组。范例:ORDER BY (CounterID, EventDate)。
如果PRIMARY KEY子句未明确定义主键,则ClickHouse会将排序键用作主键。
ORDER BY tuple()如果不需要排序,请使用语法。
PARTITION BY— 分区键。可选的。
要按月进行分区,请使用toYYYYMM(date_column)表达式,其中的date_column是日期类型为Date的列。此处的分区名称具有"YYYYMM"格式。
PRIMARY KEY—主键(与排序键)不同。可选的。
默认情况下,主键与排序键(由ORDER BY子句指定)相同。因此,在大多数情况下,无需指定单独的PRIMARY KEY子句。
SAMPLE BY—用于采样的表达式。可选的。
如果使用采样表达式,则主键必须包含它。范例:SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。
TTL—规则列表,用于指定行的存储持续时间并定义磁盘和卷之间零件自动移动的逻辑。可选的。
结果必须有一个Date或一DateTime列。例:
TTL date + INTERVAL 1 DAY
规则的类型DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'指定了在满足表达式(达到当前时间)时要对零件执行的操作:删除过期的行,将零件(如果对零件中的所有行都满足表达式)移动到指定的磁盘(TO DISK 'xxx')或到音量(TO VOLUME 'xxx')。规则的默认类型为删除(DELETE)。可以指定多个规则的列表,但最多只能有一个DELETE规则。
SETTINGS—控制MergeTree(可选)行为的其他参数:
- index_granularity—索引标记之间的最大数据行数。默认值:8192。请参见数据存储。
- index_granularity_bytes—数据粒度的最大大小(以字节为单位)。默认值:10Mb。要仅按行数限制颗粒大小,请设置为0(不建议)。请参阅数据存储。
- enable_mixed_granularity_parts—启用或禁用过渡以通过index_granularity_bytes设置控制颗粒尺寸。在版本19.11之前,只有index_granularity用于限制颗粒大小的设置。index_granularity_bytes从具有大行(数十和数百MB)的表中选择数据时,此设置可提高ClickHouse性能。如果您的表具有大行,则可以为表启用此设置以提高SELECT查询效率。
- use_minimalistic_part_header_in_zookeeper— ZooKeeper中数据部件头的存储方法。如果为use_minimalistic_part_header_in_zookeeper=1,则ZooKeeper存储的数据较少。有关更多信息,请参阅“服务器配置参数”中的设置说明。
- min_merge_bytes_to_use_direct_io—使用对存储磁盘的直接I / O访问所需的最小合并操作数据量。合并数据部分时,ClickHouse会计算要合并的所有数据的总存储量。如果卷超过min_merge_bytes_to_use_direct_io字节,ClickHouse将使用直接I / O接口(O_DIRECT选项)读取数据并将数据写入存储磁盘。如果为min_merge_bytes_to_use_direct_io = 0,则直接I / O被禁用。默认值:10 * 1024 * 1024 * 1024字节。
- merge_with_ttl_timeout—重复与TTL合并之前的最小延迟(以秒为单位)。默认值:86400(1天)。
- write_final_mark—启用或禁用在数据部分的末尾(最后一个字节之后)写入最终索引标记。默认值:1.不要关闭它。
- merge_max_bloCK_size—合并操作的块中的最大行数。默认值:8192
- storage_policy—存储策略。请参阅使用多个块设备进行数据存储。
- min_bytes_for_wide_part,min_rows_for_wide_part—可以以Wide格式存储的数据部分中的最小字节/行数。您可以设置这些设置之一,全部或全部。请参阅数据存储。
2.1.3 建表示例
建表
create table tb_merge_tree(
id Int8 ,
name String ,
ctime Date
)
engine=MergeTree()
order by id
partition by name ;
插入数据
insert into tb_merge_tree values
(1,'hng','2020-08-07'),(4,'hng','2020-08-07'),(3,'ada','2020-08-07'),(2,'ada','2020-08-07') ; 指定的分区字段是name
指定的排序字段是id


再次插入数据
insert into tb_merge_tree values(5,'ada','2020-08-07'),(6,'hng','2020-08-07') ;

每批次的插入数据作为一个基础单元进行分区,区内数据按照指定的字段进行排序
进入到某个分区目录下
[root@linux04 8cc7880f023bd2c11f539b5088249423_1_1_0]# ll
total 48
-rw-r-----. 1 ClickHouse ClickHouse 361 Aug 5 14:43 cheCKsums.txt
-rw-r-----. 1 ClickHouse ClickHouse 74 Aug 5 14:43 columns.txt 所有的列
-rw-r-----. 1 ClickHouse ClickHouse 1 Aug 5 14:43 count.txt 记录数据的条数
-rw-r-----. 1 ClickHouse ClickHouse 30 Aug 5 14:43 ctime.bin
-rw-r-----. 1 ClickHouse ClickHouse 48 Aug 5 14:43 ctime.mrk2
-rw-r-----. 1 ClickHouse ClickHouse 28 Aug 5 14:43 id.bin
-rw-r-----. 1 ClickHouse ClickHouse 48 Aug 5 14:43 id.mrk2
-rw-r-----. 1 ClickHouse ClickHouse 8 Aug 5 14:43 minmax_name.idx
-rw-r-----. 1 ClickHouse ClickHouse 34 Aug 5 14:43 name.bin
-rw-r-----. 1 ClickHouse ClickHouse 48 Aug 5 14:43 name.mrk2
-rw-r-----. 1 ClickHouse ClickHouse 4 Aug 5 14:43 partition.dat
-rw-r-----. 1 ClickHouse ClickHouse 2 Aug 5 14:43 primary.idx
- *.bin是按列保存数据的文件
- *.mrk保存块偏移量
- primary.idx保存主键索引
合并多次插入数据的分区
optimize table tb_merge_tree ;
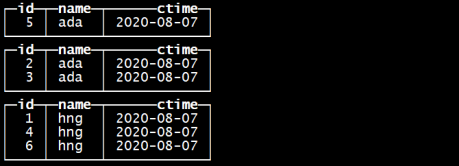
再合并一次 optimize table tb_merge_tree ;
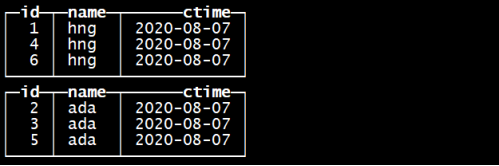
合并完以后数据在磁盘上的存储是

过段时间以后CK内部自动的会删除合并前的多余的文件夹
![]()
在磁盘上的数据组织结构是

2.2
2,3
2,4
2.5