该论文来自EMNLP2019、清华&微软研究院、源码&数据集【1】已开源github:Doc2EDAG
paper地址:paper原文
金融领域数据有以下两种特征:
① 事件元素分散(Arguments-scattering):指事件论元可能在不同的句子(Sentence)中。
② 多事件(Muti-event):指一个文档中可能包含多个事件。
由于Sentence-level级别的事件抽取模型不能很好的处理一个句子中有多个事件的情况,本文提出一个文档级别的金融领域事件抽取模型(Doc2EDAG),该模型的核心思想是将文档级别的事件表填充任务(Document-level Event table filling,DEE)转化为基于实体的有向无环图的路径扩展任务(Entity-based directed acyclic graph,EDAG)。该模型将Document-level级别的context进行编码,并设计了一个记忆机制进行图路径扩展。为缓解远程监督标注时的错误,该模型忽略掉触发词标注(trigger-words labeling),忽略触发词标注可以省略掉触发词预定义和启发式生成触发词(对于没有触发词的句子,从预定义的触发词集合中启发式生成一个触发词)。
关键概念:
实体(entity):实体对象的文本跨度
事件角色(entity role):对于事件表的预定义字段
事件参数(event argument):事件参数是扮演特定事件角色的实体
事件记录(event record):一个事件记录对应于事件表的一个条目,并包含几个具有所需角色的参数
DEE Task Without Trigger Words(无触发词的DEE任务):
① Entity extraction: 提取实体作为参数候选
② Event detection: 判断文档是否针对每个事件类型触发(二分类)
③ Event table filing: 将参数填充到触发事件表中
Doc2EDAG task:
Doc2EDAG任务的思想是将事件表填充任务转化为EDAG的路径扩展任务。
该任务有两个核心步骤:
①文档级别的实体编码(document-level entity encoding)
②有向无环图的生成(EDAG generation)
根据预定义的事件角色(Event role)顺序生成EDAG的过程如下图所示:
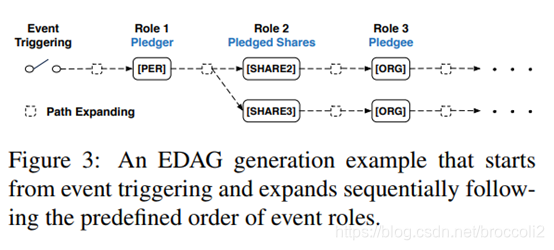
Doc2EDAG的工作流程,下图的流程对应Figure3的图扩展过程。
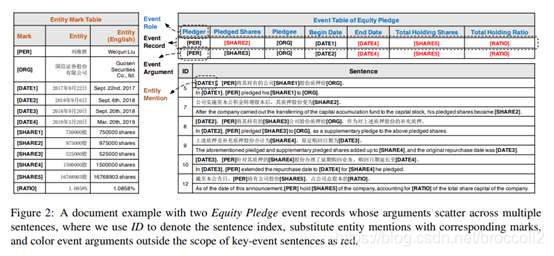
事件表填充(event table finling)案例:
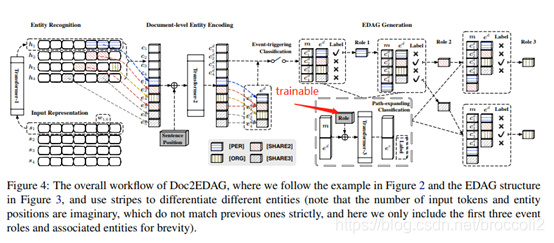
Document-level entity encoding:
在进行文档级别的实体编码之前要先将句子进行embedding并识别句子中的entity。本文将一个文档视为一个sentence使用Transformer-1编码,使用BI-LSTM-CRF进行句子级别的实体识别。
Entity&Sentence Embedding:
将所有的实体和句子进行embedding,并分别使用最大池化操作获得固定维度的向量。
Document-level Encodeing:
为所有已经编码的entity和sentence添加句子位置编码(sentence position embedding)并送入transformer-2获得文档级别的entity mention和sentence embedding。在该步骤使用max-pooling合并名称相同的实体。
EDAG Generation:
(1) 首先使用线性分类器对每个event type进行事件触发分类(event-triggering classification,二分类任务)。
(2) 为每个已分类的event type按照预定义的event role顺序创建EDAG,图节点对应entity或NA(NA表示当前sentence没有与当前event role匹配的实体)。创建完成的EDAG每条完整路径对应event table中的一条事件记录。
(3) 为了记录当前实体是否已经被添加到EDAG中,本文为每个句子创建一个记忆向量m,当句子中的entity或NA被添加到EDAG中时就更新对应位置的m向量值。
Path Expanding:
该任务被视为一个二分类任务,即判断某个实体是否对应当前顺序下的event role,如果是就将该实体添加到EDAG中,如果没有任何实体能与当前event role匹配则将NA添加到EDAG中。
该步骤将对应位置的记忆向量m与entity进行拼接,并添加一个额外的可训练的实体角色指示向量(event-role indicator embedding)送入transformer-3进行encoding,然后从transformer-3的output得到一个enriched entity embedding,最后将此enriched entity embedding送入分类器进行分类。
实验:
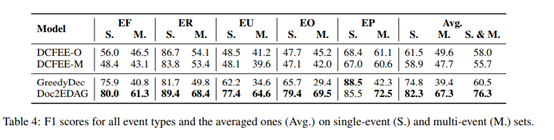
本文构建了一个金融领域文档级别的事件抽取数据集(原数据来自),实验预定义了五类event type:股权冻结Equity Freeze (EF), 股权回购Equity Repurchase (ER), 股权减持Equity Underweight (EU), 股权增持Equity Overweight (EO) and 股权解押Equity Pledge (EP)。
为了降低error-propagation,模型训练过程中采用**计划采样【2】**方式(scheduled sampling)进行迭代训练,计划 采样是指训练网络时不完全采用真实序列作为下一步的输出,而是以一个概率p选择真实标记,以1-p概率选择模型输出,p是变化的,开始训练时p较大,模型训练越充分p越小[3]。
实验结果:
S:single-event
M:multi-event
关注我的微信公众号,一起变得更强:

参考:
[1] https://github.com/dolphin-zs/Doc2EDAG
[2] Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. 2015. Scheduled sampling for sequence prediction with recurrent neural networks. In NIPS.