代码实现:基于tensorflow 2.2实现,代码见github。
参考文献:
1. A Fast and Accurate Dependency Parser using Neural Networks
2. 依存句法分析—A Fast and Accurate Dependency Parser using Neural Networks
Transition-based Dependency Parsing
从初始状态开始,每步贪婪预测下一步的动作(多分类取分数/概率最高的类别),如转移、生成左弧或右弧,直到所有单词的预测完毕(stack仅含根节点,buffer为空)。
基于贪婪的预测结构化数据,会导致错误传播,一步错导致步步错,但是贪婪预测的方式仍能够获得较好的效果。
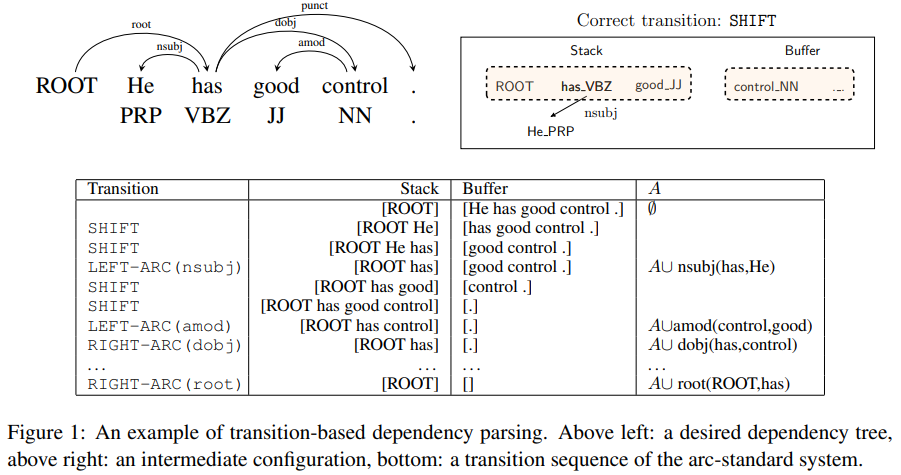
贪婪解析器最基本的要求是,能够在给定信息下正确预测下一步动作,一般可用于正确做出预测的先验信息包含:
- 单词及其词性;
- 单词头结点及其词性;
- 单词所处栈区、缓冲区的位置,或者是否已经从栈区弹出;
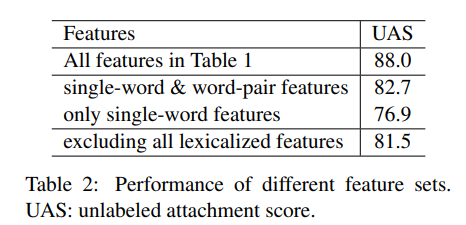
传统方法使用特征模板的缺点:
- 稀疏性:特征可能具有高维稀疏性,从上表2中可知,单词特征、单词对、单词位置、栈区相邻单词的词性、左右孩子依存关系等,对模型效果提升具有影响;
- 不完全性:利用预先设定的“专家模板”,不可避免地会无法覆盖所有的情况;
- 计算开销昂贵:需对不同特征的连接、聚合,如对不同位置的单词、词性及依存句法的连接和组合,而且还需在数以百万计的特征集中查找这些特征,这些特征的连接、聚合、查找可能在训练期间占用90+%以上;
因此,本文提出一种使用密集特征作为神经网络输入的方法,构建贪婪依存句法解析器。
Neural Network Based Parser

模型输入
拼接三种embedding:18个单词特征、18个词性特征和12依存关系特征,共计48个特征。
单词特征
i. 栈区和缓冲区前3个单词,共计6个特征
s1, s2, s3, b1, b2, b3
ii. 栈区前两个单词的左、右孩子中距离最近的两个孩子,共计8个特征
lc1(s1), rc1(s1), lc2(s1), rc2(s1), lc1(s2), rc1(s2), lc2(s2), rc2(s2)
iii. 栈区前两个单词距离最近左孩子的最近左孩子,最近右孩子的最近右孩子,共计4个特征
lc1(lc1(s1)), rc1(rc1(s1)), lc1(lc1(s2)), rc1(rc1(s2))
词性特征
单词特征各单词对应的词性,共计18个特征。
依存句法特征(已经预测的依存句法)
除单词特征中第一种特征之外的单词对应的依存句法,共计12个特征。
隐藏激活函数
使用 cube激活函数,代替relu、tanh等激活函数
式中, 是单词embedding输出向量,如embedding_size=50,则 的维度是50*18=900。
激活函数的等价形式(拼接三种输入embedding):
使用cube函数可以 建模三种不能特征的不同组合:

本文中三种特征 来自于三种embedding3的不同维度,这种激活函数可能捕获三种特征的不同组合形式。
输出层
softmax输出多类别概率。
模型训练
-
使用预训练词向量初始化word embedding;
-
损失函数:
-
优化器:Adagrad,初始学习率0.01;