前两天,博主在摸鱼时偶然接触到了百度AI,一时间来了兴趣。在实战测试了其中的“通用文字识别”后,发现效果还是蛮不错的。所以通过本次文章记录一下,以作备忘。
前期准备
百度AI前期准备工作
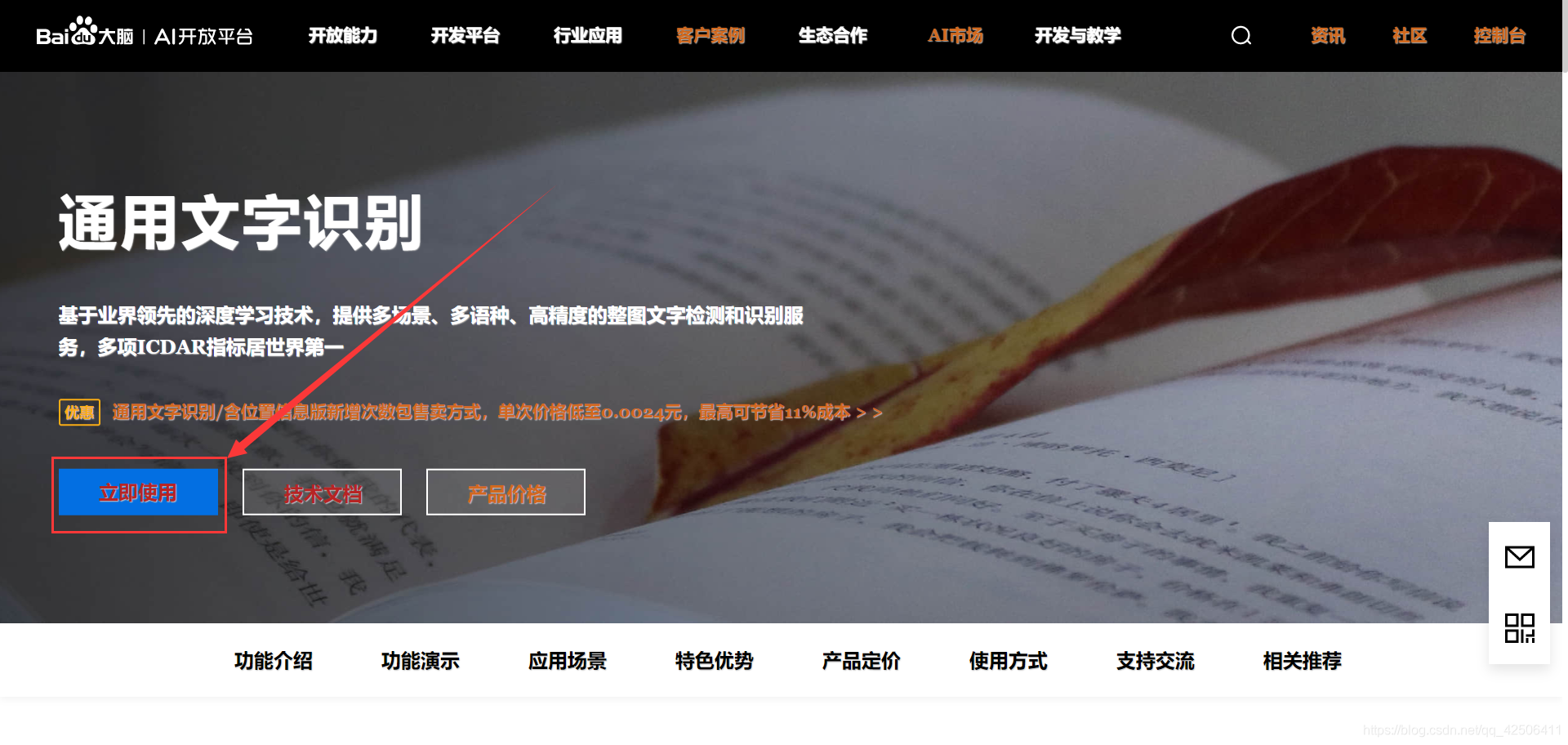
首先打开百度AI的官方网站(https://ai.baidu.com/),找到文字识别中的通用文字识别,点击立即使用。

扫码登录百度智能云,点击“文字识别”的“概览”里面的“创建应用”。其中,应用名字和应用描述随意写、其他默认即可。
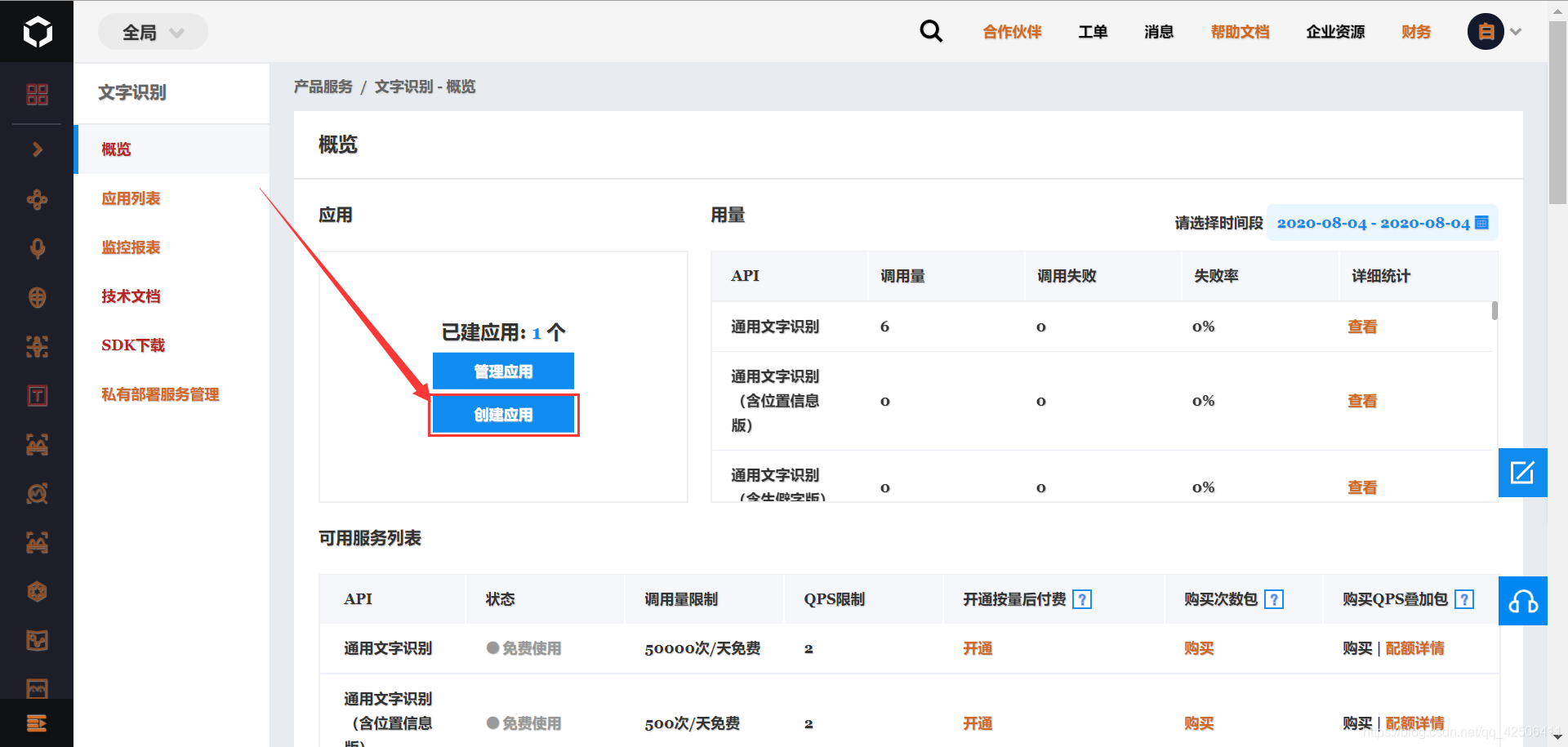
创建成功后,可以发现出现了“AppID”、“API Key”、“Secret Key”。这三项内容待会在Python编程时需要用到,必须提前申请好。

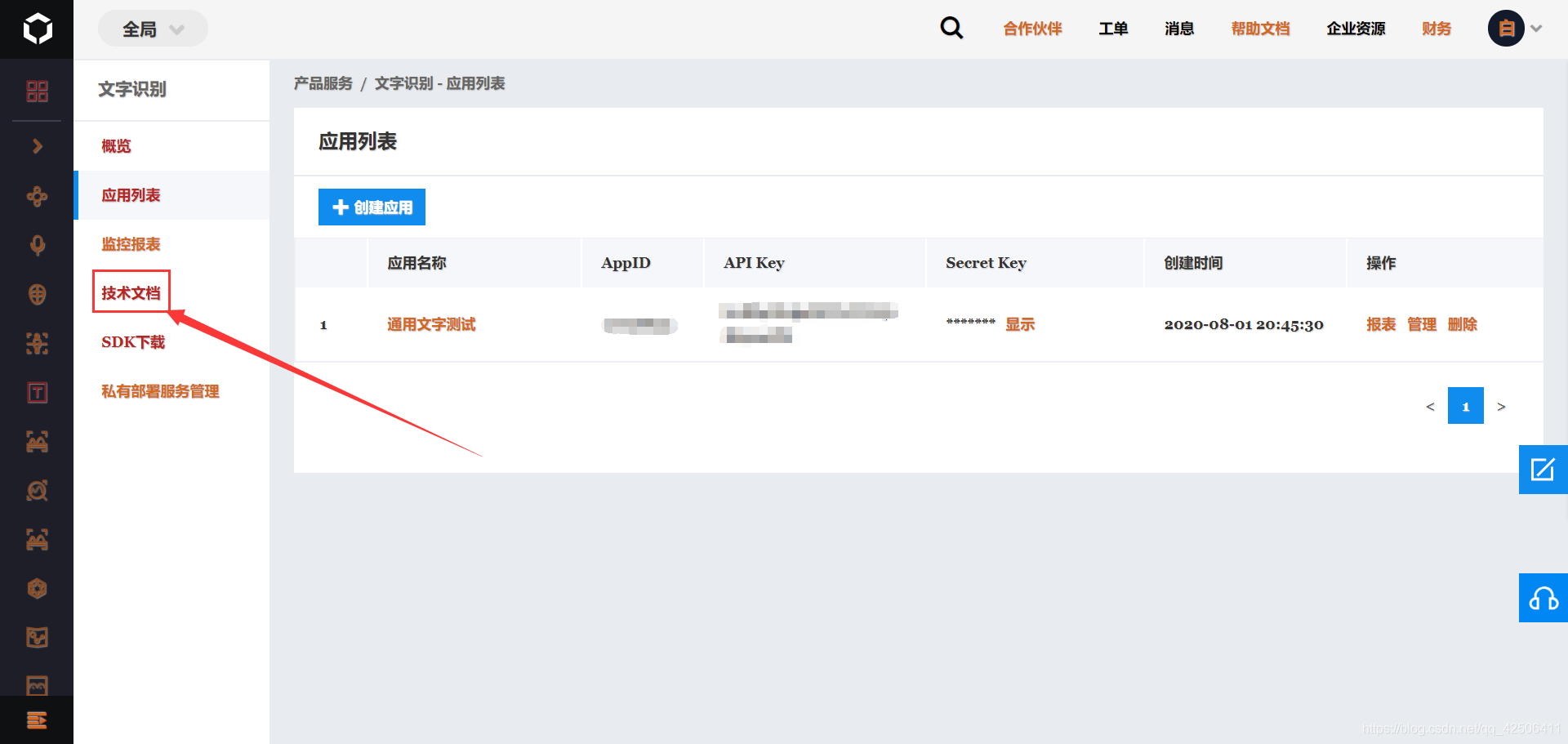
有了“AppID”、“API Key”、“Secret Key”后,我们点击左侧的“技术文档”,选择“SDK文档”中的“Python语言”下的“快速入门”,查看文档说明,发现我们需要安装Python的第三方库:baidu-aip库。
点击“接口说明”,可以查看Python代码模板。因为本次实战只是简单实现截图文本识别功能,因此我们只需要复制好下列代码即可:
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
""" 调用通用文字识别, 图片参数为本地图片 """
client.basicGeneral(image);
Python第三方库前期安装工作
除了Python内置的time框架以外,其他Python的第三方库我们都需要进行手动安装。这里推荐使用pip进行安装:
pip install keyboard
pip install pillow
pip install baidu-aip
其中,如果使用高版本的Python可能安装好keyboard库在使用时会报错,由于是版本不支持的问题因此无法解决。这里推荐使用Python3.6版本,不过博主使用的Python3.7.2版本也是没什么问题的,而在另一台Deepin 20系统使用的Python3.7.6版本就报错无法使用了;PIL库对应的高版本Python框架是pillow库,因此直接安装pillow库即可。
import keyboard # python用的是3.6版本,3.6版本以上可能会出问题(框架不支持)
from PIL import ImageGrab # PIL较多用于2.7版本的Python中,到python3版本已经用Pillow代替PIL了(pip install pillow)
from aip import AipOcr # 百度AI人工智能
实战分析
思路分析
截图工具:
1.QQ/Tim内置屏幕截图(CTRL+ALT+A -> 回车键Enter)。
2.Snipaste(F1 -> CTRL+C)。
本次实战使用QQ/Tim内置屏幕截图工具,有兴趣的朋友可自行下载安装Snipaste进行尝试。
实现步骤:
1.监控键盘按键(不按下设置的相关按键则一直处于监控状态,不执行下面代码)进行截图。
keyboard.wait(hotkey='ctrl+alt+a')
keyboard.wait(hotkey='enter')
time.sleep(0.1) # 睡眠0.1秒,加载缓存,否则有延迟
2.图片保存到当前目录下。
image = ImageGrab.grabclipboard() # 能够从剪切板当中获取图片,并且生成出来
image.save('screenhot.jpg')
3.以二进制形式读取图片,识别图片上面的文字内容,将内容输出到控制台。
APP_ID = '百度AI对应的appid值'
API_KEY = '百度AI对应的appkey值'
SECRET_KEY = '百度AI对应的secretkey值'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('screenhot.jpg')
""" 调用通用文字识别, 图片参数为本地图片 """
client.basicGeneral(image);
result = text['words_result']
for i in result:
print(i['words'])
4.封装成函数形式,增添文本写入功能,将获取的文本内容直接写入到txt文本,并在控制台中输出出来。
def textRecognition(self, writetype): # 文本识别函数
img = self.getImage()
text = self.client.basicGeneral(img) # 返回文字内容
result = text['words_result']
with open('content.txt', writetype + '+', encoding='utf8') as fp:
for i in result:
fp.write(i['words'] + '\n')
print(i['words'])
5.代码优化:通过if判断语句将代码整体优化,以防止因报错而导致的程序结束。
整体代码
import keyboard # python用的是3.6版本,3.6版本以上可能会出问题(框架不支持)
from PIL import ImageGrab # PIL较多用于2.7版本的Python中,到python3版本已经用Pillow代替PIL了(pip install pillow)
from aip import AipOcr # 百度AI人工智能
import time
import sys
class TextRecognition():
def __init__(self):
APP_ID = '百度AI对应的appid值'
API_KEY = '百度AI对应的appkey值'
SECRET_KEY = '百度AI对应的secretkey值'
self.client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
def toScreenhot(self): # 截图函数
keyboard.wait(hotkey='ctrl+alt+a')
keyboard.wait(hotkey='enter')
time.sleep(0.1) # 睡眠0.1秒,加载缓存,否则有延迟只能加载上一张图片
image = ImageGrab.grabclipboard() # 能够从剪切板当中获取图片,并且生成出来
image.save('screenhot.jpg')
def getImage(self): # 二进制文件读取函数
with open('screenhot.jpg', 'rb') as fp:
return fp.read()
def textRecognition(self, writetype): # 文本识别函数
img = self.getImage()
text = self.client.basicGeneral(img) # 返回文字内容
result = text['words_result']
with open('content.txt', writetype + '+', encoding='utf8') as fp:
for i in result:
fp.write(i['words'] + '\n')
print(i['words'])
if __name__ == '__main__':
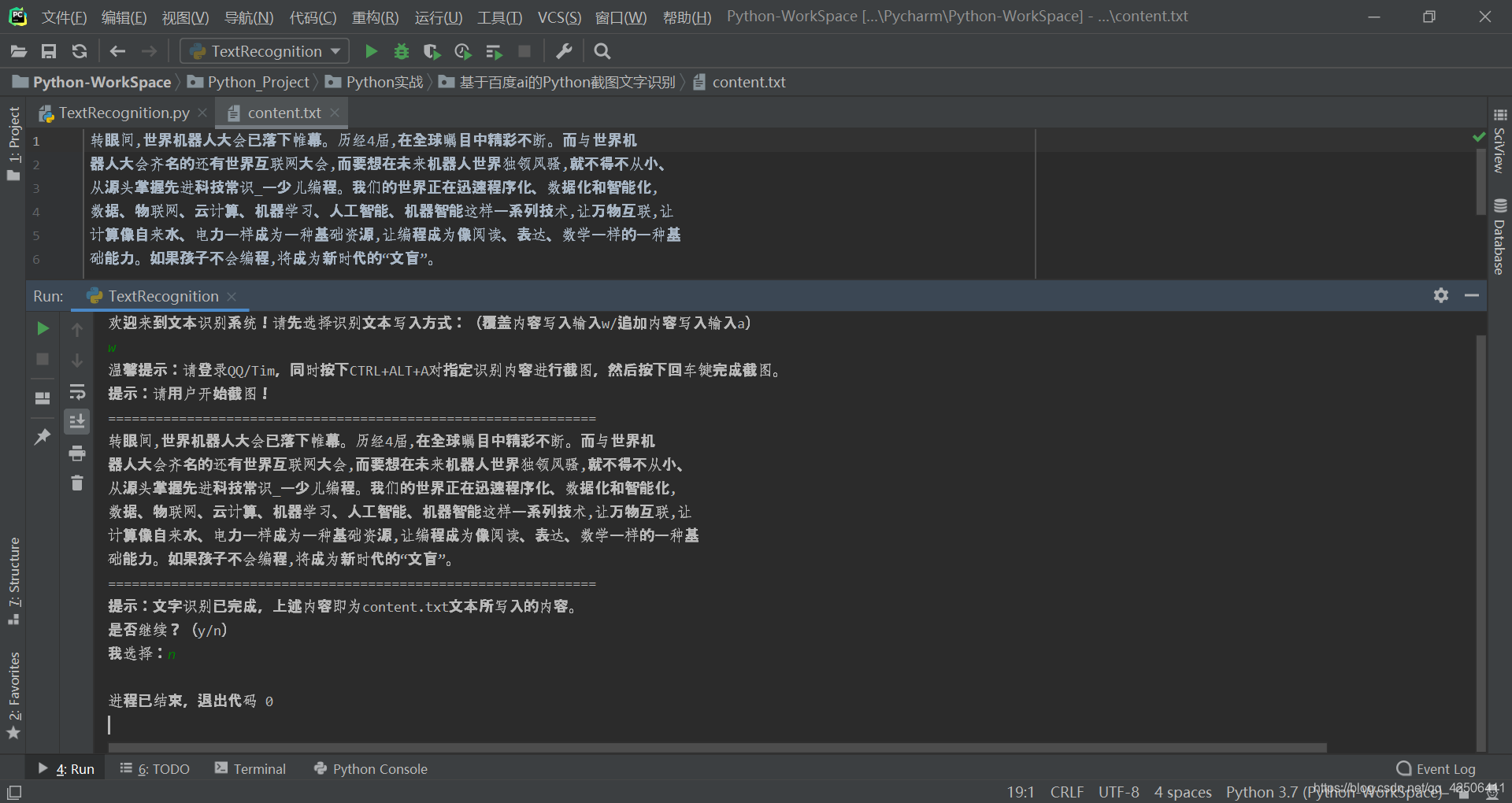
writetype = input("欢迎来到文本识别系统!请先选择识别文本写入方式:(覆盖内容写入输入w/追加内容写入输入a)\n")
if writetype == 'w' or writetype == 'a':
print("温馨提示:请登录QQ/Tim,同时按下CTRL+ALT+A对指定识别内容进行截图,然后按下回车键完成截图。")
while 1:
print("提示:请用户开始截图!")
TextRecognition().toScreenhot()
print("==============================================================")
TextRecognition().textRecognition(writetype)
print("==============================================================")
print("提示:文字识别已完成,上述内容即为content.txt文本所写入的内容。\n是否继续?(y/n)")
judge = input("我选择:")
if judge == 'y':
continue
elif judge == 'n':
break
else:
while 1:
print("警告:请输入正确的选项(y/n)!")
judge1 = input("我选择:")
if judge1 == 'y':
break
elif judge1 == 'n':
sys.exit(0)
else:
continue
else:
print("警告:请输入正确的识别文本写入方式:(覆盖内容写入输入w/追加内容写入输入a)!")
sys.exit(0)
运行测试