集合继承框架图
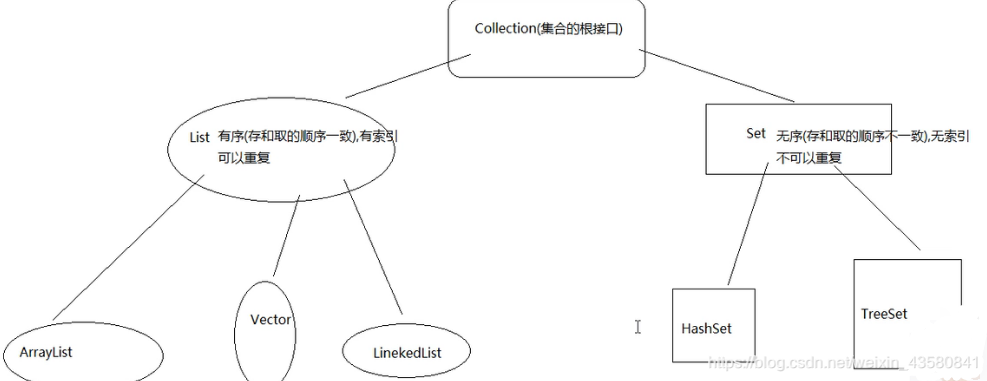
还是这个图,今天学的是set接口,还有他底下的两个类:HashSet、TreeSet。
set:无序,存和取不一致,不允许重复。
Set
List有特有的方法是因为他有索引这个特性,Set就没有特别的方法。
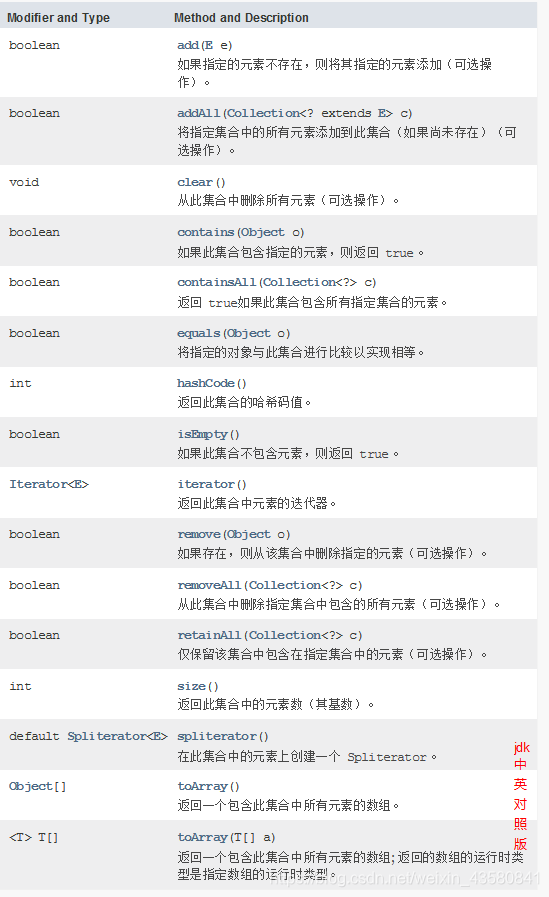
HashSet
可以通过HashSet来保证存入元素的唯一性。
HashSet的add方法会返回boolean值表示有没有添加成功。
Hashset不能添加重复的元素,在自定义类中要重写equals方法判断元素是否相等,否则HashSet会以地址值来判断元素是否相等。
除了equals方法要重写以外,还需要重写hashCode方法。hashCode方法是Object类中定义的用来计算哈希码(根据地址)的函数,在HashSet中添加元素时会调用hashCode计算该元素的哈希码值,决定这个元素放在哪个位置,如果两个元素哈希码值一样,HashSet就会调用equals方法判断这两个元素是否相等,如果相等就不添加,不相等就挂在这个位置上(木桶结构)。
重写hashCode()和equals()方法的标准:
hashCode:属性相同的对象返回值必须相同,属性不同的返回值尽量不同(提高效率,减少不必要的调用equals)
equals:属性相同返回true,属性不同返回false,返回false的时候存储
LinkedHashSet
LinkedHashSet可以保证存取顺序一致。
保证元素唯一用的是HashSet,但是存储结构用的是链表。
HashSet存取速度更快,开发中更常用的是HashSet。
将集合中的重复元素删除:
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("c");
list.add("a");
list.add("b");
LinkedHashSet<String> set = new LinkedHashSet<>();
set.addAll(list);
list.clear();
list.addAll(set);
System.out.println(list);
运行结果:[a, b, c]
TreeSet
TreeSet一样可以保证存入数据的唯一性,还可以对存入元素进行排序。(integer类型从小到大排序,String类型通过字典的顺序来排序)
HashSet和TreeSet对元素的要求是不一样的,HashSet要求自定义类重写HashCode方法和equals方法。TreeSet要求元素要有比较性(继承Comparable接口,重写compareTo方法,这是让对象具有比较性;传入Comparator比较器,这是让集合具有比较性)。
TreeSet存了第一个元素以后,每次存入元素都要与现有的元素比较,比原有元素大就存右边,比原有元素小就存左边,在compareTo方法中返回值为正数就存右边,返回值为负数就存左边,为0就不存。(二叉树结构)
private static class Student implements Comparable{
private int age;
private String name;
public Student(int age, String name){
this.age = age;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this.age== ((Student) o).age&&this.name==((Student)o).name) return true;
else return false;
}
public void setAge(int age) {
this.age = age;
}
public void setName(String name){
this.name = name;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
@Override
public int compareTo(Object o) {
int num = this.age-((Student)o).age;
return num==0 ? this.name.compareTo(((Student) o).name):num;
}
}
如果不是自定义元素,想规定TreeSet的排序方法,就写一个继承Comparator接口的内部类,然后实现compare方法,例子:规定String元素在set中按长度排序
public static void main(String [] args){
TreeSet<String> set = new TreeSet<>(new CompareByLen());
set.add("Student1");
set.add("Student2");
set.add("Student3");
set.add("4");
System.out.println(set);
}
static class CompareByLen implements Comparator<String>{
public int compare(String s1,String s2){
int length = s1.length() - s2.length();
return length == 0 ? s1.compareTo(s2):length;
}
}
运行结果:[4, Student1, Student2, Student3]
小结:TreeSet有两种排序方式
TreeSet构造函数中什么都不传,就默认按自然顺序来排序(如果元素的类没有compareTo方法,就报错ClassCastException),TreeSet类的add()方法中会把存入的对象提升为Comparable类型,调用对象的compareTo方法和集合中的对象比较,根据compareTo方法返回的结果进行存储。
TreeSet的构造函数传入Comparator,就优先按Comparator对象中实现的compare方法来排序,返回负数就往左边,返回正数就往右边,返回0 就不存。