先说下整体思路:
- 找到豆瓣电影Top250的网址 https://movie.douban.com/top250
- 确定要爬取的这个html页面是动态页面还是静态页面, 静态页面是可以直接爬取的,动态页面需要从js或者XHR里面去找动态的json数据。 本次爬取的250名单 本质上还是静态的,因为内容都在页面里,我们不需要去js或者xhr里面找数据。
- 确认一下 要爬的网页是否有反爬。我们要和反爬 有一个小小的斗争!
- 先爬取第一页的电影名单
- 利用循环,爬取全部10页里的名单
静态爬取比较简单,主要是思路要对。而且这次爬取是用get请求,就更简单了。
按照上面的思路走,开始代码吧:
第一步: 我们先爬取单个页面来试试水
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/top250' #url是爬数据的根本,所有流程都是围绕url展开的
# 为了反爬,我们把headers加上
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
# 'Accept-Encoding': 'gzip, deflate, br', # 这一句代码对编码器有限制,所以注释掉就行了
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'douban-fav-remind=1; bid=QhopwFw0HcQ; __utmz=30149280.1586506561.6.5.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ses.100001.4cf6=*; __utma=30149280.1613818664.1547469206.1586506561.1594137884.7; __utmb=30149280.0.10.1594137884; __utmc=30149280; __utma=223695111.510808800.1561795806.1561795806.1594137884.2; __utmb=223695111.0.10.1594137884; __utmc=223695111; __utmz=223695111.1594137884.2.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); ap_v=0,6.0; _pk_id.100001.4cf6=b46c129b3f0ba258.1561795806.2.1594137900.1561795859.',
'Host': 'movie.douban.com',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
res = requests.get(url, headers=headers) # 发送get请求
html = res.text # 把请求结果res转换成字符串类型
soup = BeautifulSoup(html, 'html.parser') # 用html.parser编译html字符串,得到的是列表
# print(html)
# print(soup)
# F12大法,在页面里找一下电影名字所处的位置, 然后右击 → 选COPY → 选copy selector
# 这里要求要懂一点前端知识啦,ol > li:nth-child(1) > div ... ,意思是选取ol里的第一个li里面的内容
# 但是我们实际上是要的每个li里面的内容,所以要改一下,改成:ol > li > div > ...
spans = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)')
# print(spans)
# 然后我们对得到的span进行遍历操作,再给电影名前面加上序号
i = 1
for span in spans:
# print(span)
print(str(i)+':', span.text)
i += 1
这样,就得到了第一页的输出结果:
1: 肖申克的救赎
2: 霸王别姬
3: 阿甘正传
4: 这个杀手不太冷
5: 美丽人生
6: 泰坦尼克号
7: 千与千寻
8: 辛德勒的名单
9: 盗梦空间
10: 忠犬八公的故事
11: 海上钢琴师
12: 楚门的世界
13: 三傻大闹宝莱坞
14: 机器人总动员
15: 放牛班的春天
16: 星际穿越
17: 大话西游之大圣娶亲
18: 熔炉
19: 疯狂动物城
20: 无间道
21: 龙猫
22: 教父
23: 当幸福来敲门
24: 怦然心动
25: 触不可及
到这里,是不是感觉很爽啊。 下面,我们做个更爽的,就是把这10页内容都搞下来。
直接上代码,在注释里详细说明:
import requests
from bs4 import BeautifulSoup
host = 'movie.douban.com' # 把这一块单拎出来,写起来更简便
j = 0
while j <= 9 : # 对整个代码块进行循环, 相当于从第一页到第十页全部爬一遍
# 这里的url拆解分析,是重点!!! 如果url分析不出来,就没有后续的代码了
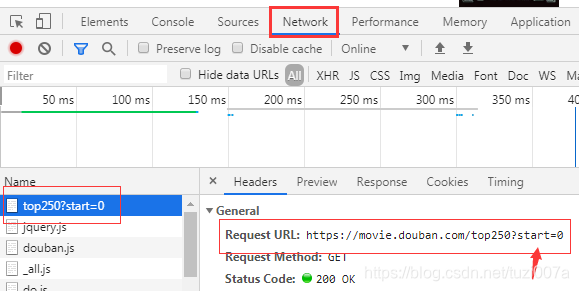
# F12大法,打开network,看下面的url分析图。 在这个页面不要动,
# 鼠标去点下一页,看看url有什么变化?
# 有没有发现,第一页的start值是0, 第二页的start值是25, 第三页的start值是50...以此类推
# 于是,就可以得到我们的动态url了! 如下:
url = 'https://' + host +'/top250?start=' + str(j * 25)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
# 'Accept-Encoding': 'gzip, deflate, br',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'douban-fav-remind=1; bid=QhopwFw0HcQ; __utmz=30149280.1586506561.6.5.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ses.100001.4cf6=*; __utma=30149280.1613818664.1547469206.1586506561.1594137884.7; __utmb=30149280.0.10.1594137884; __utmc=30149280; __utma=223695111.510808800.1561795806.1561795806.1594137884.2; __utmb=223695111.0.10.1594137884; __utmc=223695111; __utmz=223695111.1594137884.2.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); ap_v=0,6.0; _pk_id.100001.4cf6=b46c129b3f0ba258.1561795806.2.1594137900.1561795859.',
'Host': host,
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
res = requests.get(url, headers=headers)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
# print(html)
# print(soup)
# 因为a标签里面有不止1个span,电影名字是在第一个span里,所以 我们要获取到第一个span。
spans = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)')
# print(spans)
# 再值得说的一点 就是这里i的值的变化了
# 注意i 和j 的关系, 即每一页开头的电影名的序号 和页数的关系
i = j*25 + 1
for span in spans:
# print(span)
print(str(i)+':', span.text)
i += 1
# print(headers['Host'])
# print(host)
j += 1
url分析图:
好了,大致就是这样了。
这个代码还有地方可以改进,比如得到的结果写进Excel表格里。
大家可以自己试一下啊~~