美图欣赏:

康完,漂酿的小姐姐,是否感觉写代码更有动力呢? 嘿嘿,欢迎小伙伴们在评论区留言呦~
目录
一.基本配置和启动集群
1.1 基本配置
Standalone模式为代表
1.解压缩 flink-1.7.2-bin-hadoop27-scala_2.11.tgz
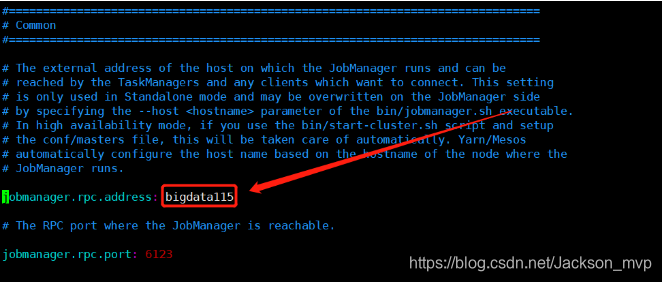
2.进入 conf 目录中修改flink/conf/flink-conf.yaml 文件:
红框里面改成自己的主机名或者IP
3.修改 /conf/master 文件:

4.修改 /conf/slave文件:
以上Standalone模式配置完成
5.flink-conf.yaml配置详解
①基础配置:
#根据节点所在的主机名自动配置主机名
#JobManager运行
jobmanager.rpc。地址:bigdata115
#可以访问JobManager的RPC端口
jobmanager.rpc.port:6123
#JobManager JVM的堆大小
jobmanager.heap.size:1024m
#TaskManager JVM的堆大小
taskmanager.heap.size:1024m
#每个TaskManager提供的任务插槽数。每个插槽运行一个并行管道。
taskmanager.numberOfTaskSlots:1
#用于未指定程序的并行性和其他并行性。
parallelism.default:1
②高可用性配置:
# 可以选择 'NONE' 或者 'zookeeper'.
# high-availability: zookeeper
# 文件系统路径,让 Flink 在高可用性设置中持久保存元数据
# high-availability.storageDir: hdfs:///flink/ha/
# zookeeper 集群中仲裁者的机器 ip 和 port 端口号
# high-availability.zookeeper.quorum: localhost:2181
# 默认是 open,如果 zookeeper security 启用了该值会更改成 creator
# high-availability.zookeeper.client.acl: open
③容错和检查点 配置
# 用于存储和检查点状态
# state.backend: filesystem
# 存储检查点的数据文件和元数据的默认目录
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# savepoints 的默认目标目录(可选)
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
# 用于启用/禁用增量 checkpoints 的标志
# state.backend.incremental: false
④web 前端配置
# 基于 Web 的运行时监视器侦听的地址.
#jobmanager.web.address: 0.0.0.0
# Web 的运行时监视器端口
rest.port: 8081
# 是否从基于 Web 的 jobmanager 启用作业提交
# jobmanager.web.submit.enable: false
⑤Flink 集群安全配置
# 指示是否从 Kerberos ticket 缓存中读取
# security.kerberos.login.use-ticket-cache: true
# 包含用户凭据的 Kerberos 密钥表文件的绝对路径
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# 与 keytab 关联的 Kerberos 主体名称
# security.kerberos.login.principal: flink-user
# 以逗号分隔的登录上下文列表,用于提供 Kerberos 凭据(例如,`Client,KafkaClient`使用凭证进行 ZooKeeper 身份验证和 Kafka 身份验证)
# security.kerberos.login.contexts: Client,KafkaClient
1.2 启动集群
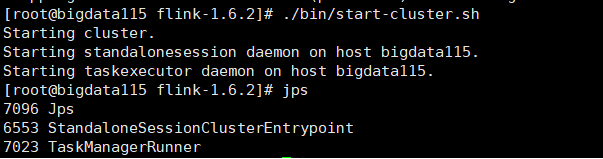
1.启动Flink
[root@bigdata115 flink-1.7.2]# ./bin/start-cluster.sh
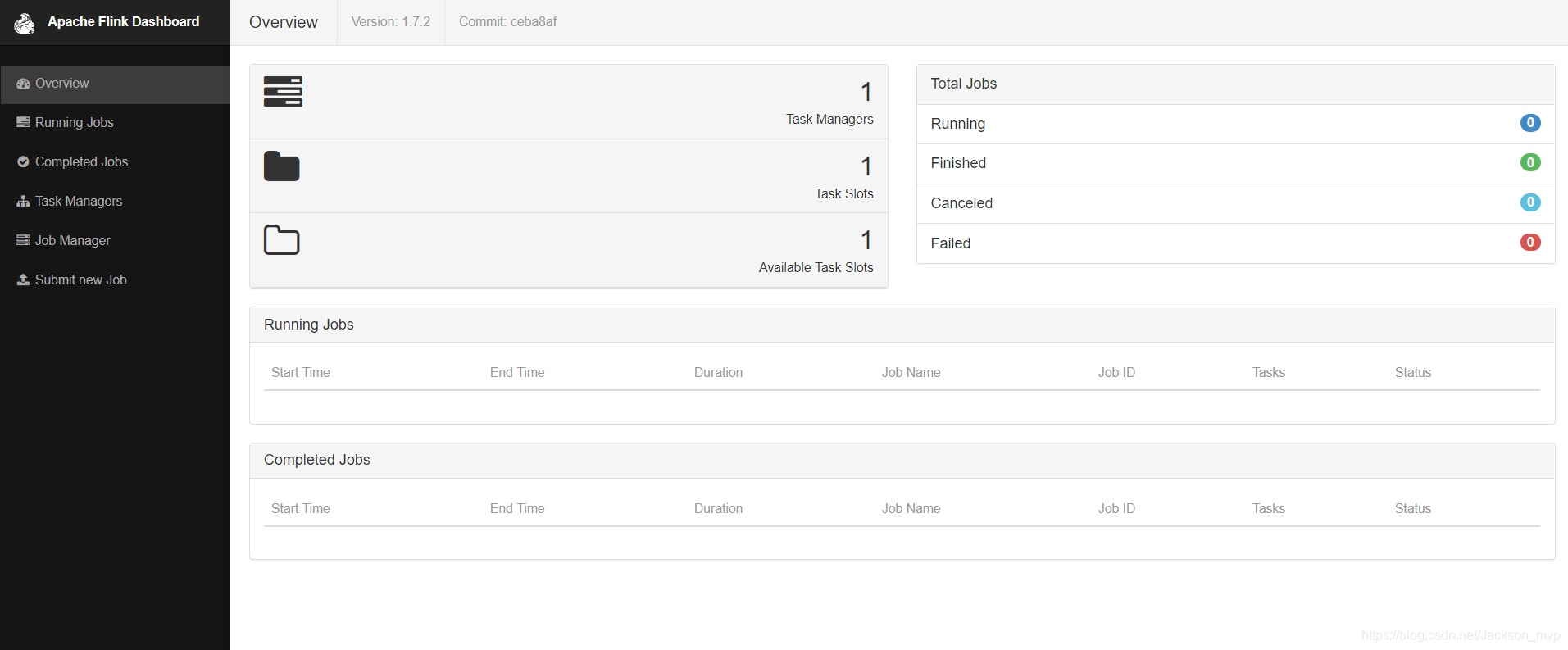
2.成功查看Web 界面:flink后面端口号8081
http://192.168.1.xxx:8081
二.提交任务和测试
2.1 提交任务
①用socketTextStream方法,测试wordcount
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
/**
1. Project: FlinkMVP
2. Package: com.jackson.wc
3. Version: 1.0
4. create : 2020-5-25
*/
object DataStreamWordCount {
def main(args: Array[String]): Unit = {
val params = ParameterTool.fromArgs(args)
val host: String = params.get("host")
val port: Int = params.getInt("port")
// 创建一个流处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// env.setParallelism(1)
// env.disableOperatorChaining()
// 接收socket数据流
val textDataStream = env.socketTextStream(host, port)
// 逐一读取数据,分词之后进行wordcount
val wordCountDataStream = textDataStream.flatMap(_.split(" "))
// .filter(_.length>1).disableChaining()
.filter(_.length>1).startNewChain()
.map( (_, 1) )
.keyBy(0)
.sum(1)
// 打印输出
wordCountDataStream.print().setParallelism(1)
// 执行任务
env.execute("stream word count job")
}
}
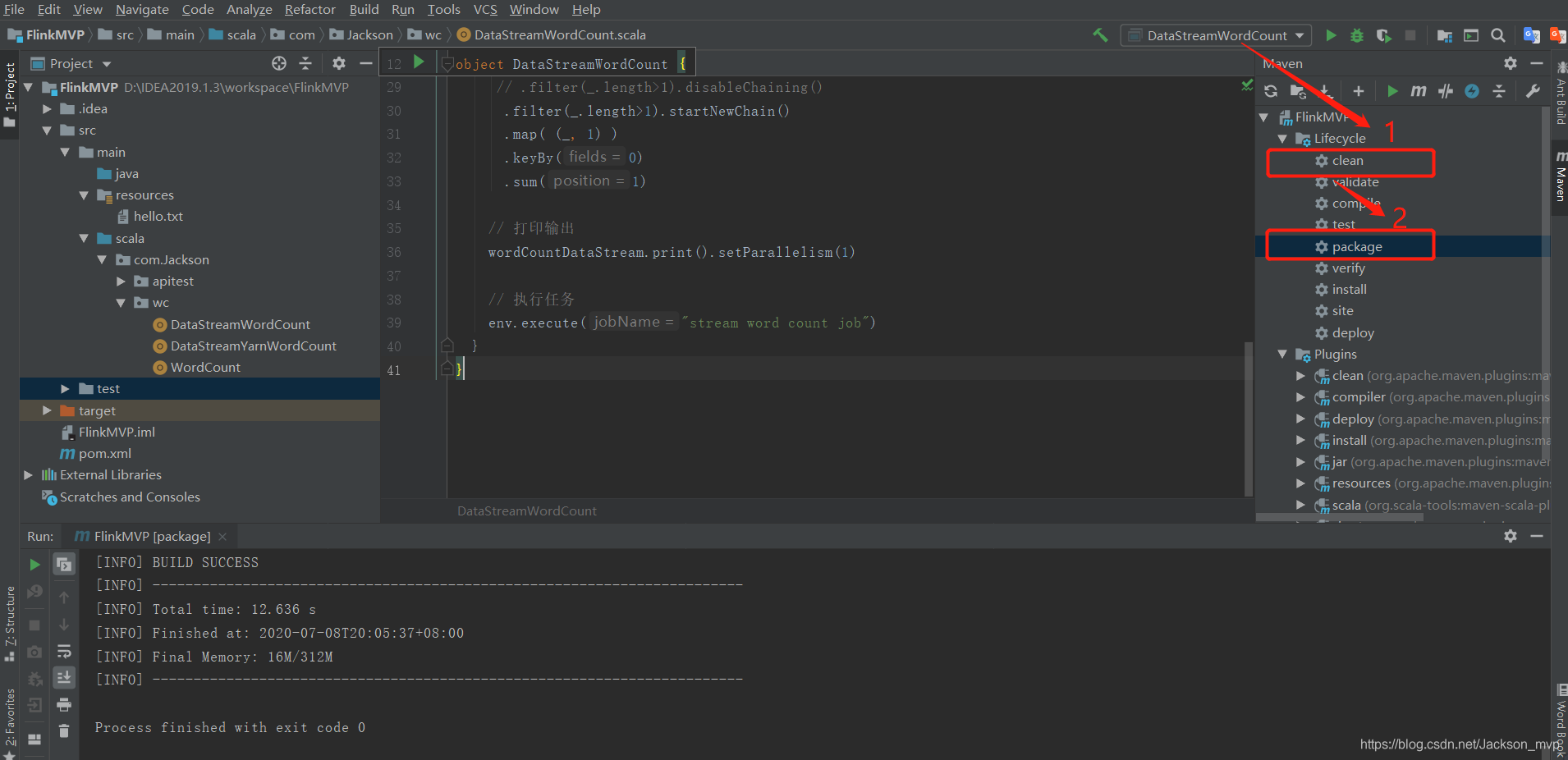
②打包测试代码
- 先clean
- 在package
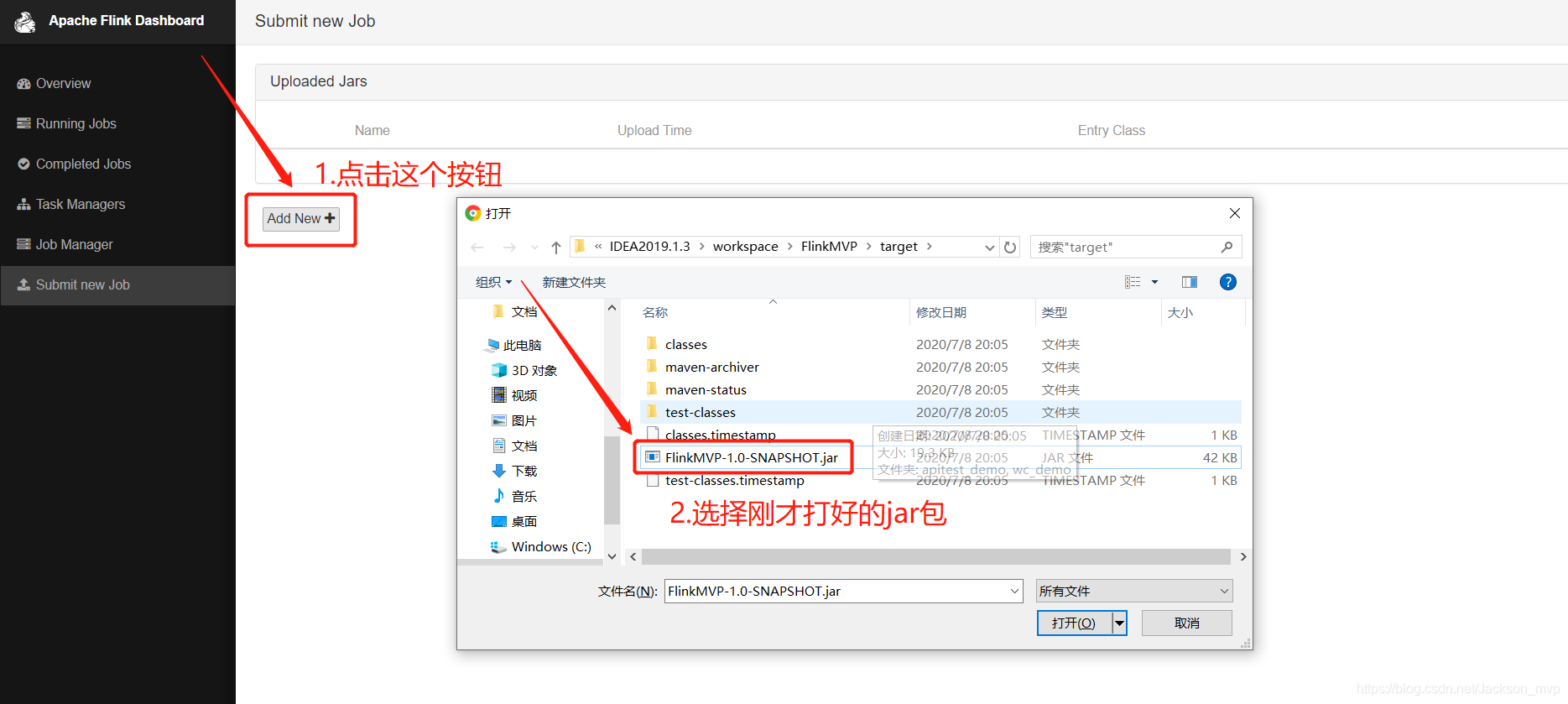
2.2 Web UI jar包测试
①提交jar包
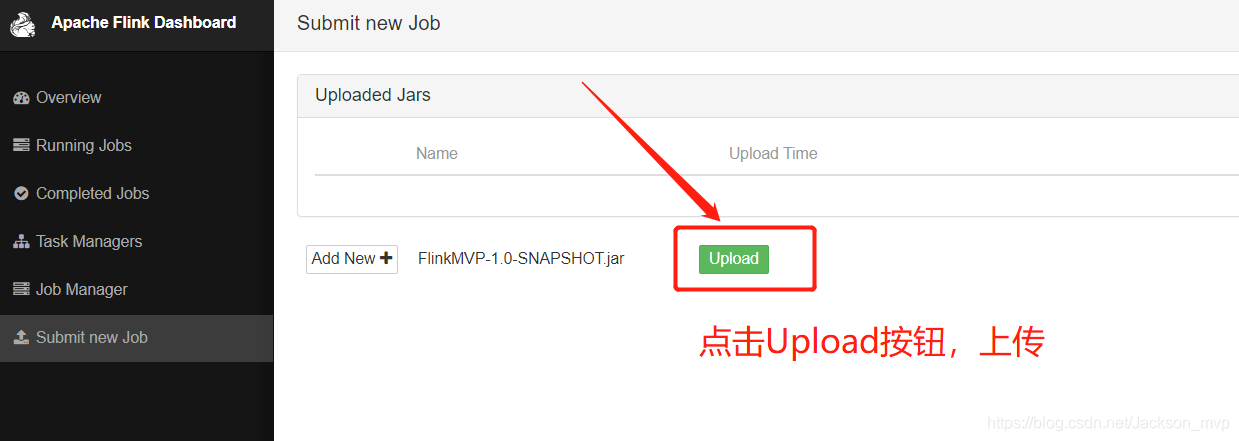
②.点击Upload,上传
③在Web UI 提交,最后点击Submit
注:先在Liunx端,启动nc -lk 端口
Show Plan,也可以直接展现执行计划图。
表明在没提交之前,就已经有执行计划图。

④查看结果
查看日志:
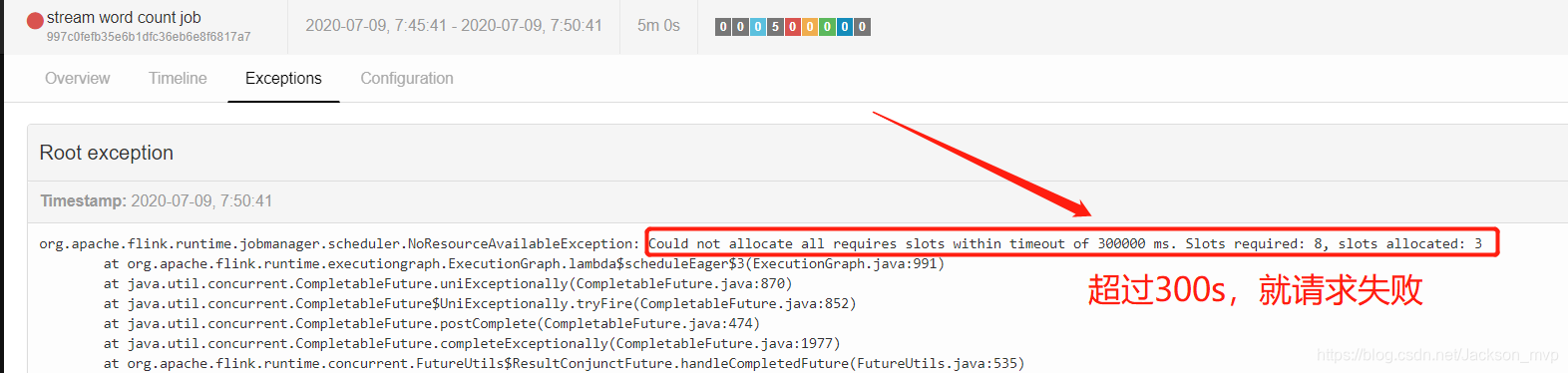
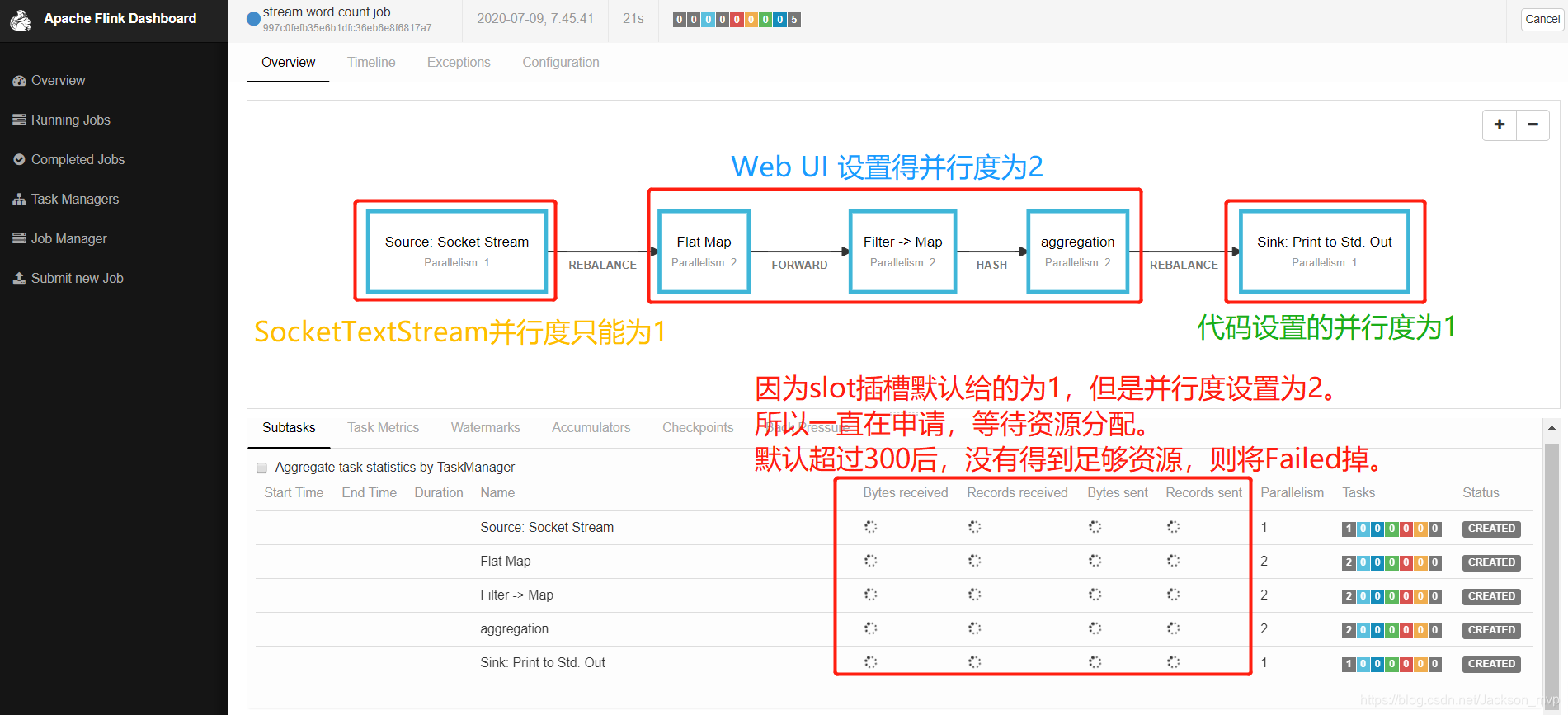
⑤并行度设置为1,重新提交。
在Linux下,发送俩条消息:hello Jackson
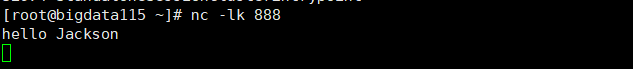
可以看到是Running状态,说明提交成功,已经接收到消息。
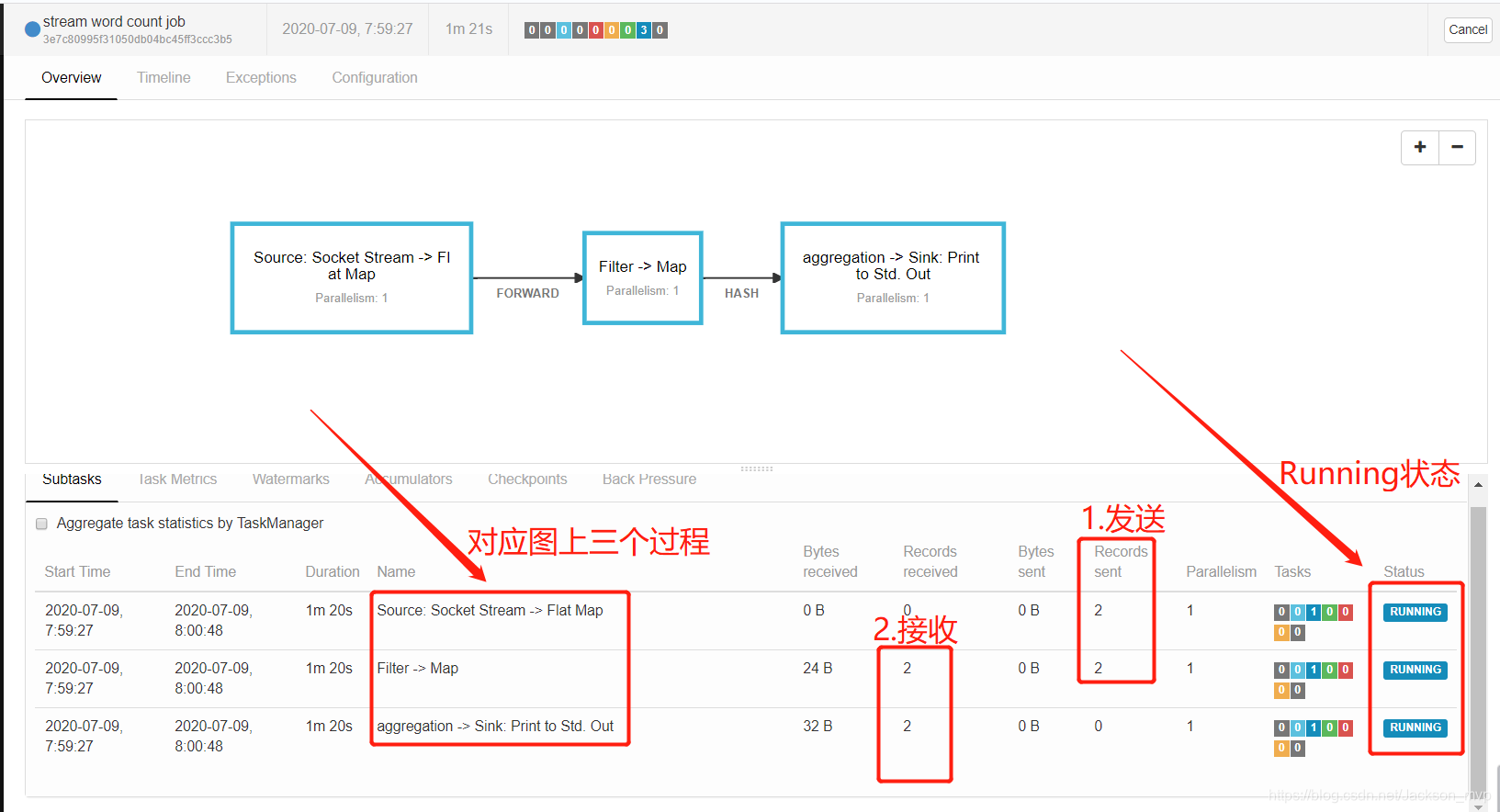
Transform过程收到的字节数<Sink过程中收到的字节数
⑥查看日志结果,在TaskManger端

注:默认心跳时间为10s一次
代码运行优先级顺序:代码>Web UI端设置/Liunx下命令参数>底层配置文件
三.命令行操作及其它部署方式
3.1 命令行操作
1.一先要启动端口 nc -lk 端口号
注:要不然会报连接异常
2.提交命令
./bin/flink run -c com.Jackson.wc.DataStreamWordCount
-p 2 /root/data/flinkjar/FlinkMVP-1.0-SNAPSHOT.jar
--host bigdata115 --port 888
注:-p指的是并行度,并行度影响任务速度
3.结果
悬停状态,但在WebUI中可以看到日志结果
4.提交命令后,可以ctrl+c ,任务仍在运行。
5.用list查看,运行任务
[root@bigdata115 flink-1.7.2]# ./bin/flink list
Waiting for response...
------------------ Running/Restarting Jobs -------------------
03.06.2020 16:11:42 : c5a8c5da349caceb4e6a143d5a4c7055 : stream word count job (RUNNING)
No scheduled jobs.
6.cancel ID号,就可以取消运行任务
[root@bigdata115 flink-1.7.2]# ./bin/flink cancel c5a8c5da349caceb4e6a143d5a4c7055
c5a8c5da349caceb4e6a143d5a4c7055
Cancelling job c5a8c5da349caceb4e6a143d5a4c7055.
Cancelled job c5a8c5da349caceb4e6a143d5a4c7055.
7.list再次查看,无运行任务
[root@bigdata115 flink-1.7.2]# ./bin/flink list
Waiting for response...
No running jobs.
No scheduled jobs.
8.可以加个–all参数,查看所有的任务(包括failed,running,cancel)
[root@bigdata115 flink-1.7.2]# ./bin/flink list --all
Waiting for response...
No running jobs.
No scheduled jobs.
---------------------- Terminated Jobs -----------------------
03.06.2020 14:59:15 : 282e60de37d8b9c6a008ef5e0df97b10 : stream word count job (FINISHED)
03.06.2020 15:31:07 : 0d4a351a00bd388baf52eb2c26e6e4cf : stream word count job (FAILED)
03.06.2020 15:31:40 : 25b1ee3a846498889ea83f2ec91717ac : stream word count job (CANCELED)
03.06.2020 15:33:20 : eab5cb4ebe9ea3765313271d88ecb623 : stream word count job (FINISHED)
03.06.2020 16:01:03 : cb05aefe0172a1300e502c7850fee4f9 : stream word count job (FAILED)
03.06.2020 16:01:24 : 3966cd24efc7f2cd14a3694d79b30638 : stream word count job (FINISHED)
03.06.2020 16:06:17 : 45b24c400bf91e5f46eefafe1096d527 : stream word count job (FAILED)
3.2 Yarn 模式
以 Yarn 模式部署 Flink 任务时,要求 Flink 是有 Hadoop 支持的版本(flink-1.7.2-bin-hadoop27-scala_2.11.tgz), Hadoop环境需要保证版本在 2.2 以上,并且集群中安装有 HDFS 服务。
- 启动 hadoop 集群(略)
注: 一定要修改etc/hadoop/yarn-site.xml,添加下面内容,不然报错。
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 启动 yarn-session
./bin/yarn-session.sh -n 1 -s 1 -jm 1024 -tm 1024 -nm test -d
其中:
-n(–container): TaskManager 的数量。
-s(–slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个
taskmanager 的 slot 的个数为 1,有时可以多一些 taskmanager,做冗余。
-jm: JobManager 的内存(单位 MB)。
-tm:每个 taskmanager 的内存(单位 MB)。
-nm: yarn 的 appName(现在 yarn 的 ui 上的名字)。
-d:后台执行。
- 执行任务
./bin/flink run -m yarn-cluster -c com.Jackson.wc.DataStreamYarnWordCount
/root/flinkjar/FlinkMVP-1.0-SNAPSHOT.jar
--input /root/flinkjar/firstdata.txt
--output /root/flinkjar/out1.csv
- 去 yarn 控制台查看任务状态
报错:
yarn提交 org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
3.3 Kubernetes 模式
容器化部署时目前业界很流行的一项技术,基于 Docker 镜像运行能够让用户更加 方 便地 对应 用进 行管 理 和运 维。 容器 管理 工 具中 最为 流行 的就 是 Kubernetes( k8s),而 Flink 也在最近的版本中支持了 k8s 部署模式。
1) 搭建 Kubernetes 集群(略)
2) 配置各组件的 yaml 文件
在 k8s 上构建 Flink Session Cluster,需要将 Flink 集群的组件对应的 docker 镜像分别在 k8s 上启动,包括 JobManager、 TaskManager、 JobManagerService 三个镜像服务。 每个镜像服务都可以从中央镜像仓库中获取。
3)启动 Flink Session Cluster
// 启动 jobmanager-service 服务
kubectl create -f jobmanager-service.yaml
// 启动 jobmanager-deployment 服务
kubectl create -f jobmanager-deployment.yaml
// 启动 taskmanager-deployment 服务
kubectl create -f taskmanager-deployment.yaml
4) 访问 Flink UI 页面集群启动后,就可以通过 JobManagerServicers 中配置的 WebUI 端口,用浏览器输入以下 url 来访问 Flink UI 页面了:
http://{JobManagerHost:Port}/api/v1/namespaces/default/services/flink-jobmanager:ui/proxy
那么谢谢大家,本次的分享就到这里了。
感谢小伙伴们,同时欢迎大家与我交流,VX:LQ1518123002。
