学了这么多年软件竟然第一次写博客,所以写的不好也请多多包含,文中有不正确的地儿也请大佬指出。好了,闲话少叙,今天来谈谈计算机编码中的各种问题。
标题中看着问题比较多,先上张图,看看文章的讲解思路。
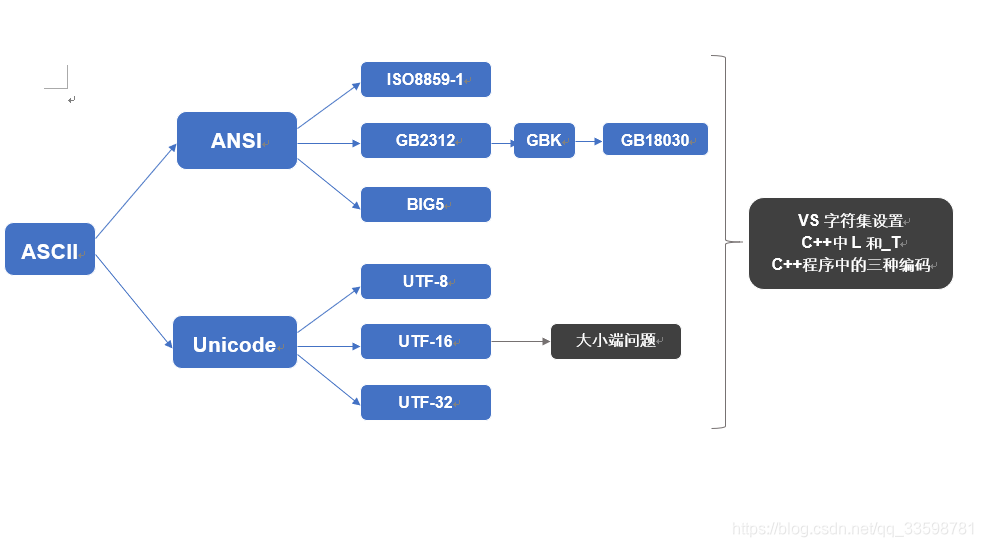
看着图中的各种名称会觉得很熟悉,但是就是弄不清他们的关系 蓝色背景的就是计算机编码的编年史了,灰色部分是这么多编码以及不同的操作系统给我们编程带来了各种比较疑惑的问题。
在讲解编码前我们要弄清楚两个概念就是字符集与字符编码。
字符集顾名思义就是各种字符与符号的集合,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。有人说弄这么多字符集干啥,这就是各个地方的发展水平以及文化不同导致的,就像有中文、英文、日文等,中文还分中文简体和繁体等,ASCII对应的就是英文、GB2312就相当于中文,BIG5呢就是繁体中文。
字符集有了但是计算机不懂啊,计算机只知道0和1,所以字符编码就出现了,字符编码是给计算机看的,就相当于过去的摩斯电吗一样,信号长短的排列组合来代表各种字符。而字符编码呢是0和1排列组合出来的。
下面开始介绍编码的编年史也就是图中的蓝色背景部分。
第一阶段:ASCII编码
毕竟计算机是人家美国人发明的,所以最早也只是他们自己用,只有英文字母、数字、英文标点的编码。ASCII 码使用指定的7 位或8 位也就是一个字节来表示128 或256 种可能的字符。标准ASCII码为7位,其中95个字符可以显示。另外33个不可以显示。扩充为8位叫为EASCII码,加入了更多欧洲字符。
第二阶段:ANSI编码
当计算机到世界各地后,仅仅支持英语就不够了,这样就有了ANSI编码,使计算机支持各地语言。比如在windows中文系统下,ANSI编码代表GB2312编码;在日文操作系统下,ANSI编码代表JS编码,在繁体中文系统下,ANSI编码就代表BIG5编码。但是不同 的ANSI 编码之间互不兼容,也就是说拿在中文系统上的文本放到日文系统上就会出现乱码情况。下面我们来看看windows的本地化情况:
首先我们在中文系统下用记事本写个中国的“中”字,然后以ANSI编码保存。


最后我们来看下它的十六进制编码:D6D0就是“中”的GB2312编码,这是中文最早的一版编码,有六千多个汉字并且采用EUC储存方法兼容ASCII码,毕竟我国汉语博大精深,只有6六千个字怎么够?于是有了GBK编码,同时也兼容GB2312和ASCII码,也用每个字占据2bytes的方式又编码了许多汉字。经过GBK编码后,可以表示的汉字达到了两万多个,并且还包含了繁体字。再后来GBK的两万多字也已经无法满足我们的需求了,这时就有了GB18030变长编码,甚至包含了少数民族文字,同时也兼容单字节的ASCII、双字节的GBK。这大概就是中文编码的发展史。

第三个阶段:UNICODE编码
因为传统的字符编码方案的局限性以及各种乱码问题,就诞生了Unicode编码,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode的最初目标。是用1个16位的编码来为超过65000字符提供映射。但这还不够。它不能覆盖全部历史上的文字。也不能解决传输的问题。尤其在那些基于网络的应用中。因此。Unicode采用三套编码方式。它们分别是UTF-8,UTF-16和UTF-32。正如名字所示。UTF-8是变长编码,字符是以8位序列来编码的,用一个或几个字节来表示一个字符,这种方式的最大好处是兼容了ASCII编码,并且可变编码提高了存储效率,节省空间。.UTF-16和UTF-32分别是Unicode的16位和32位编码方式。但是通常说的Unicode就是UTF-16。
在Linux系统中,常用的编码方式是UTF-8编码,“中”的UTF-8十六进制编码为E4 B8 AD,在windows系统中常用的编码方式为ANSI编码刚才已经介绍过了,我们来看看windows下的Unicode编码。首先我们打开记事本并以Unicode编码方式保存。

然后我们会看到它的十六进制编码为FF FE 2D 4E,还记得我刚才说Unicode常指UTF-16把,而UTF-16下的“中”编码为2D 4E。说到这就要说字节序的问题了也就是大小端问题。

字节序有两种,分别是“大端”(Big Endian, BE)和“小端”(Little Endian, LE)。
根据字节序的不同,UTF-16可被实现为UTF-16LE或UTF-16BE,UTF-32可被实现为UTF-32LE或UTF-32BE。例如:
| Unicode编码 |
UTF-16LE |
UTF-16BE |
UTF32-LE |
UTF32-BE |
| 0x006C49 |
49 6C |
6C 49 |
49 6C 00 00 |
00 00 6C 49 |
| 0x020C30 |
43 D8 30 DC |
D8 43 DC 30 |
30 0C 02 00 |
00 02 0C 30 |
Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符“零宽无中断空格”。这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。
下表是各种UTF编码的BOM:
| UTF编码 |
Byte Order Mark (BOM) |
| UTF-8 without BOM | 无 |
| UTF-8 with BOM |
EF BB BF |
| UTF-16LE |
FF FE |
| UTF-16BE |
FE FF |
| UTF-32LE |
FF FE 00 00 |
| UTF-32BE |
00 00 FE FF |
BOM就相当于一个头一样来区别大端还是小端,所以说带BOM别人就知道你的字节序。至于Unicode在各个系统上的大小端问题,我认为首先这个问题就不够准确,导致各个文章也是说的不太准确,像什么Linux中Unicode以大端方式存储这种言论。
为什么这个问题不准确,首先Unicode其实是个统称,首先Unicode中的UTF-8编码方式不存在大小端存储的问题,具体可以去查阅它的编码方式就明白了,这里不做赘述。至于大小端问题是跟操作系统中内存采用的字节序有关系,又因为通常说的Unicode指的是UTF-16编码方式,两个字节存储的顺序问题就造成了大小端问题。所以通常指的Unicode存储字节序问题是和你的操作系统有关系的,我们可以查看自己的机器是大端还是小端存储,上代码:
#include <cstdio>
#include <cstdlib>
union CodeTest {
int a;
char ch[4];
} ct;
int main()
{
ct.a = 0x1234;
printf("%x", ct.ch[0]);
system("pause"); //Linux系统将这句话注释,虽然不影响结果
return 0;
}以上代码是利用联合体的存储顺序来判断的,如果打印 34 就为小端存储,如果打印 12 就为大端存储。如果使用的是带有Intel处理器的pc机,存储方式基本为小端存储,这也就是为什么图四中的是UTF-16LE编码。如果使用的是大型机、工作站或是基于Motorola处理器的Mac机,则为大端存储。切记大小端存储方式与操作系统无关,与CPU有关。
但是在网络传输中,TCP/IP协议规定采用大端字节序,也就是先接收到的字节为数据的高位。在不同的操作系统平台中,内存采用的字节序可能不同,所以在不同平台之间进行网络传输时,需要进行特殊的转换。
补充UCS-2和UCS-4
Unicode是为整合全世界的所有语言文字而诞生的。任何文字在Unicode中都对应一个值,这个值称为代码点(code point)。代码点的值通常写成 U+ABCD 的格式。而文字和代码点之间的对应关系就是UCS-2(Universal Character Set coded in 2 octets)。顾名思义,UCS-2是用两个字节来表示代码点,其取值范围为 U+0000~U+FFFF。
为了能表示更多的文字,人们又提出了UCS-4,即用四个字节表示代码点。它的范围为 U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2是一样的。
要注意,UCS-2和UCS-4只规定了代码点和文字之间的对应关系,并没有规定代码点在计算机中如何存储。规定存储方式的称为UTF(Unicode Transformation Format),为前面提到的UTF-8、UTF-16、UTF-32等。
在我们实际编程中涉及的编码问题很多很多,首先先来说下编c++程序的三种编码:
C++源文件的编码
windows系统:不管是visual studio 还是dev-c++都是采用的ANSI编码也就是中文系统的GB2312。
Linux系统: 采用的是UTF-8编码
C++程序的内码
windows系统:采用的也是ANSI编码也就是中文系统的GB2312。上图为证,char数组中我写了个“中”字

Linux系统: 采用的是UTF-8编码。

当使用L 关键字时,两个系统都是采用的UTF-16也就是常说的Unicode编码,为小端存储。(亲测两个编码都为2D4E)
程序运行环境编码
windows系统:采用的ANSI编码也就是中文系统的GB2312。
Linux系统: 采用的是UTF-8编码。
当使用L 关键字时,两个系统都是采用的UTF-16也就是常说的Unicode编码,为小端存储。
vs字符集设置与_T()、Text()
先说_T()、Text(),我们直接看他们俩的源码,在tchar.h中
/* Generic text macros to be used with string literals and character constants.
Will also allow symbolic constants that resolve to same. */
#define _T(x) __T(x)
#define _TEXT(x) __T(x)其实_T和Text()的功能是一样的,是一个预定义的宏。我们在看__T(x)的定义


所以说我们设置使用Unicode字符集时,会将_T转换成L,否则使用多字节字符集的时候也不做。

然而这些有什么用呢,其实我认为是为windowsAPI的一些函数准备的,比如wsprintf这种函数,它的定义为
#ifdef UNICODE
#define wsprintf wsprintfW
#else
#define wsprintf wsprintfA我们能看出wsprintf有两个版本,一个wsprintfW是针对Unicode版的,一个是wsprintfA针对多字节字符的,它们通过不同宏进行隔开,预设不同的宏会使用不同的版本。我们通过设置使用Unicode字符集就预设了_UNICODE、UNICODE宏,所以编译时就会使用wsprintfW,这时我们传入多字节常量字符串就会有问题,而应该传入宽符的字符串,用字符串前面加L。所以为了在改配置不修改代码的情况下我们就可以使用_T()。工程上一般推荐使用Unicode的方式,因为它可以适应各个国家语言,前面已经讲过为什么。