1. kafkaSource
见官方文档
2. kafkaSource的偏移量的存储位置
默认存在kafka的特殊topic中,但也可以设置参数让其不存在kafka的特殊topic中

扫描二维码关注公众号,回复:
11319572 查看本文章

3 将kafka中的数据写入redis中去
redisSink不支持exactly Once,只支持AtLeast Once
KafkaSourceToRedisDemo


1 package cn._51doit.flink.day04; 2 3 import org.apache.flink.api.common.functions.FlatMapFunction; 4 import org.apache.flink.api.common.restartstrategy.RestartStrategies; 5 import org.apache.flink.api.common.serialization.SimpleStringSchema; 6 import org.apache.flink.api.java.tuple.Tuple; 7 import org.apache.flink.api.java.tuple.Tuple2; 8 import org.apache.flink.runtime.state.filesystem.FsStateBackend; 9 import org.apache.flink.streaming.api.CheckpointingMode; 10 import org.apache.flink.streaming.api.datastream.DataStreamSource; 11 import org.apache.flink.streaming.api.datastream.KeyedStream; 12 import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; 13 import org.apache.flink.streaming.api.environment.CheckpointConfig; 14 import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; 15 import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; 16 import org.apache.flink.streaming.connectors.redis.RedisSink; 17 import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; 18 import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; 19 import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; 20 import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; 21 import org.apache.flink.util.Collector; 22 23 import java.util.Properties; 24 25 //运行该程序要传入5个参数:ckdir gid topic redishost redisport 26 public class KafkaSourceToRedisDemo { 27 28 public static void main(String[] args) throws Exception{ 29 30 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); 31 32 //如果开启Checkpoint,偏移量会存储到哪呢? 33 env.enableCheckpointing(30000); 34 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE); 35 //就是将job cancel后,依然保存对应的checkpoint数据 36 env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); 37 env.setStateBackend(new FsStateBackend(args[0])); 38 env.setRestartStrategy(RestartStrategies.fixedDelayRestart(10, 30000)); 39 40 Properties properties = new Properties(); 41 properties.setProperty("bootstrap.servers", "node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092"); 42 properties.setProperty("group.id", args[1]); 43 properties.setProperty("auto.offset.reset", "earliest"); 44 //properties.setProperty("enable.auto.commit", "false"); 45 //如果没有开启checkpoint功能,为了不重复读取数据,FlinkKafkaConsumer会将偏移量保存到了Kafka特殊的topic中(__consumer_offsets) 46 //这种方式没法实现Exactly-Once 47 FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<String>(args[2], new SimpleStringSchema(), properties); 48 49 //在Checkpoint的时候将Kafka的偏移量保存到Kafka特殊的Topic中,默认是true 50 flinkKafkaConsumer.setCommitOffsetsOnCheckpoints(false); 51 52 DataStreamSource<String> lines = env.addSource(flinkKafkaConsumer); 53 54 SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { 55 @Override 56 public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { 57 String[] words = line.split(" "); 58 for (String word : words) { 59 out.collect(Tuple2.of(word, 1)); 60 } 61 } 62 }); 63 64 KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0); 65 66 SingleOutputStreamOperator<Tuple2<String, Integer>> summed = keyed.sum(1); 67 //Transformation 结束 68 //调用RedisSink将计算好的结果保存到Redis中 69 70 //创建Jedis连接的配置信息 71 FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder() 72 .setHost(args[3]) 73 .setPassword(args[4]) 74 .build(); 75 76 summed.addSink(new RedisSink<>(conf, new RedisWordCountMapper())); 77 78 env.execute("KafkaSourceDemo"); 79 80 } 81 82 83 public static class RedisWordCountMapper implements RedisMapper<Tuple2<String, Integer>> { 84 85 @Override 86 public RedisCommandDescription getCommandDescription() { 87 //指定写入Redis中的方法和最外面的大key的名称 88 return new RedisCommandDescription(RedisCommand.HSET, "wc"); 89 } 90 91 @Override 92 public String getKeyFromData(Tuple2<String, Integer> data) { 93 return data.f0; //将数据中的哪个字段作为key写入 94 } 95 96 @Override 97 public String getValueFromData(Tuple2<String, Integer> data) { 98 return data.f1.toString(); //将数据中的哪个字段作为value写入 99 } 100 } 101 }
注意,在任务取消后,checkpoint中的数据会被删除掉,为了不让checkpoint中的数据被删除,可以设置如下参数
//就是将job cancel后,依然保存对应的checkpoint数据 env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
验证发现,解释redis使用的是At Least Once ,基于redis的幂等性(覆盖),其也能达到exactly once的目的
因此At Least Once结合redis的幂等性。可以实现exactly once的功能
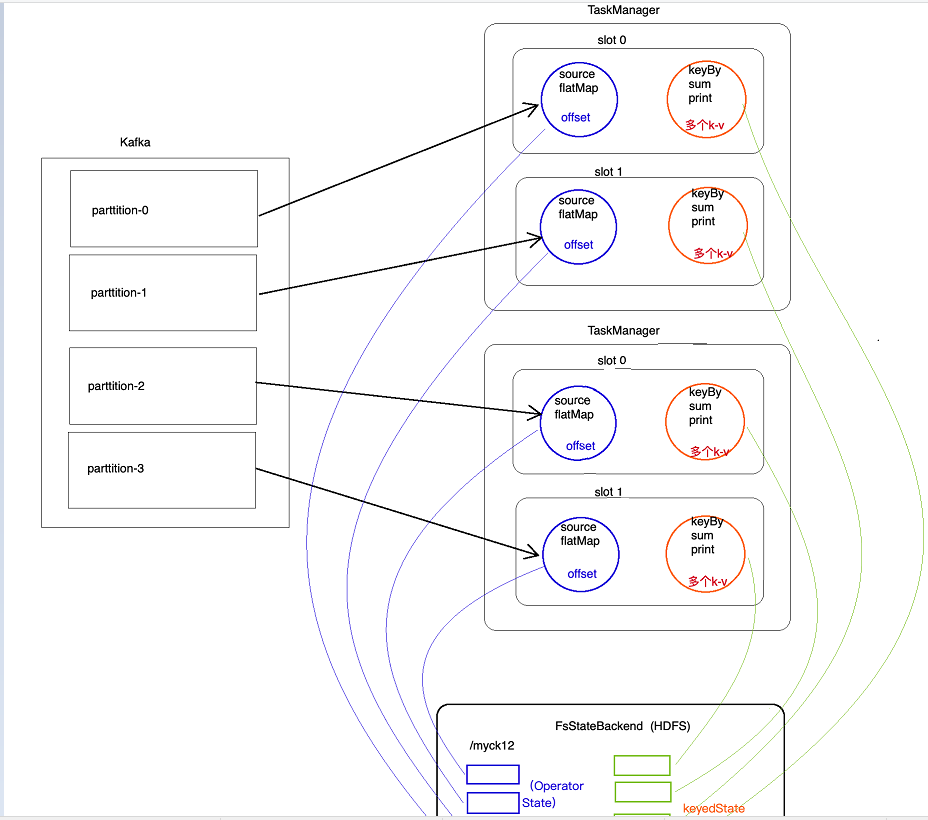
问题:在checkpoint时,Flink怎么保证operator state和keyed state是一致的?
Flink为了在checkpoint时,实现数据一致性时,其会将source阻断(barrier机制),相当于将source节流(barrier),并且下游所有算子计算完才进行checkpoint,这样就能保证数据一致
4 将kafka中的数据写入mysql中去
KafkaSourceToMySQLDemo
package cn._51doit.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.restartstrategy.RestartStrategies; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; import org.apache.flink.util.Collector; import java.util.Properties; //运行该程序要传入5个参数:ckdir gid topic redishost redisport public class KafkaSourceToMySQLDemo { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //如果开启Checkpoint,偏移量会存储到哪呢? env.enableCheckpointing(30000); env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE); //就是将job cancel后,依然保存对应的checkpoint数据 env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); env.setStateBackend(new FsStateBackend(args[0])); env.setRestartStrategy(RestartStrategies.fixedDelayRestart(10, 30000)); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092"); properties.setProperty("group.id", args[1]); properties.setProperty("auto.offset.reset", "earliest"); //properties.setProperty("enable.auto.commit", "false"); //如果没有开启checkpoint功能,为了不重复读取数据,FlinkKafkaConsumer会将偏移量保存到了Kafka特殊的topic中(__consumer_offsets) //这种方式没法实现Exactly-Once FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<String>(args[2], new SimpleStringSchema(), properties); //在Checkpoint的时候将Kafka的偏移量保存到Kafka特殊的Topic中,默认是true flinkKafkaConsumer.setCommitOffsetsOnCheckpoints(false); DataStreamSource<String> lines = env.addSource(flinkKafkaConsumer); SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split(" "); for (String word : words) { out.collect(Tuple2.of(word, 1)); } } }); KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0); SingleOutputStreamOperator<Tuple2<String, Integer>> summed = keyed.sum(1); //Transformation 结束 //调用MySQLSink将计算好的结果保存到MySQL中 summed.addSink(new MySqlSink()); env.execute("KafkaSourceToMySQLDemo"); } }
MySqlSink
package cn._51doit.flink.day04; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; public class MySqlSink extends RichSinkFunction<Tuple2<String, Integer>> { private Connection connection = null; @Override public void open(Configuration parameters) throws Exception { //可以创建数据库连接 connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456"); } @Override public void invoke(Tuple2<String, Integer> value, Context context) throws Exception { PreparedStatement preparedStatement = connection.prepareStatement("INSERT INTO t_wordcount VALUES (?, ?) ON DUPLICATE KEY UPDATE counts = ?"); preparedStatement.setString(1, value.f0); preparedStatement.setLong(2, value.f1); preparedStatement.setLong(3, value.f1); preparedStatement.executeUpdate(); preparedStatement.close(); } @Override public void close() throws Exception { connection.close(); } }