链接地址:使用Wireshark分析-以太网帧与ARP协议-IP协议-ICMP-UDP协议-TCP协议-协议HTTP-DNS协议
实验一 Wireshark的使用
一、实验目的
1、熟悉并掌握Wireshark的基本使用;
2、了解网络协议实体间进行交互以及报文交换的情况。
二、实验环境
与因特网连接的计算机,操作系统为Windows,安装有Wireshark、IE等软件。
三、 实验步骤
-
启动Web浏览器(如IE);
-
启动Wireshark;
-
开始分组捕获:单击工具栏的 按钮,出现如图1所示对话框,[options]按钮可以进行系统参数设置,在绝大部分实验中,使用系统的默认设置即可。当计算机具有多个网卡时,选择其中发送或接收分组的网络接口(本例中,第一块网卡为虚拟网卡,第二块为以太网卡)。单击“Start”开始进行分组捕获;
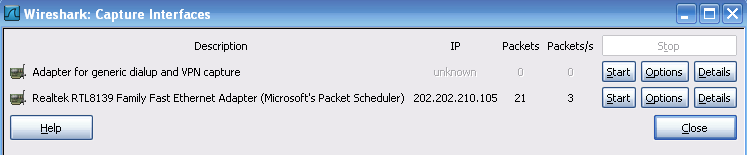
图1 -
在运行分组捕获的同时,在浏览器地址栏中输入某个网页的URL,如:

-
当完整的页面下载完成后,单击捕获对话框中的“stop”按钮,停止分组捕获。此时, Wireshark主窗口显示已捕获的你本次通信的所有协议报文;
-
在协议筛选框中输入“http”,单击“apply”按钮,分组列表窗口将只显示HTTP协议报文。
-
选择分组列表窗口中的第一条http报文,它是你的计算机发向服务器(www.njxzc.edu.cn)的HTTP GET报文。当你选择该报文后,以太网帧、IP数据报、TCP报文段、以及HTTP报文首部信息都将显示在分组首部子窗口中,其结果如图2。
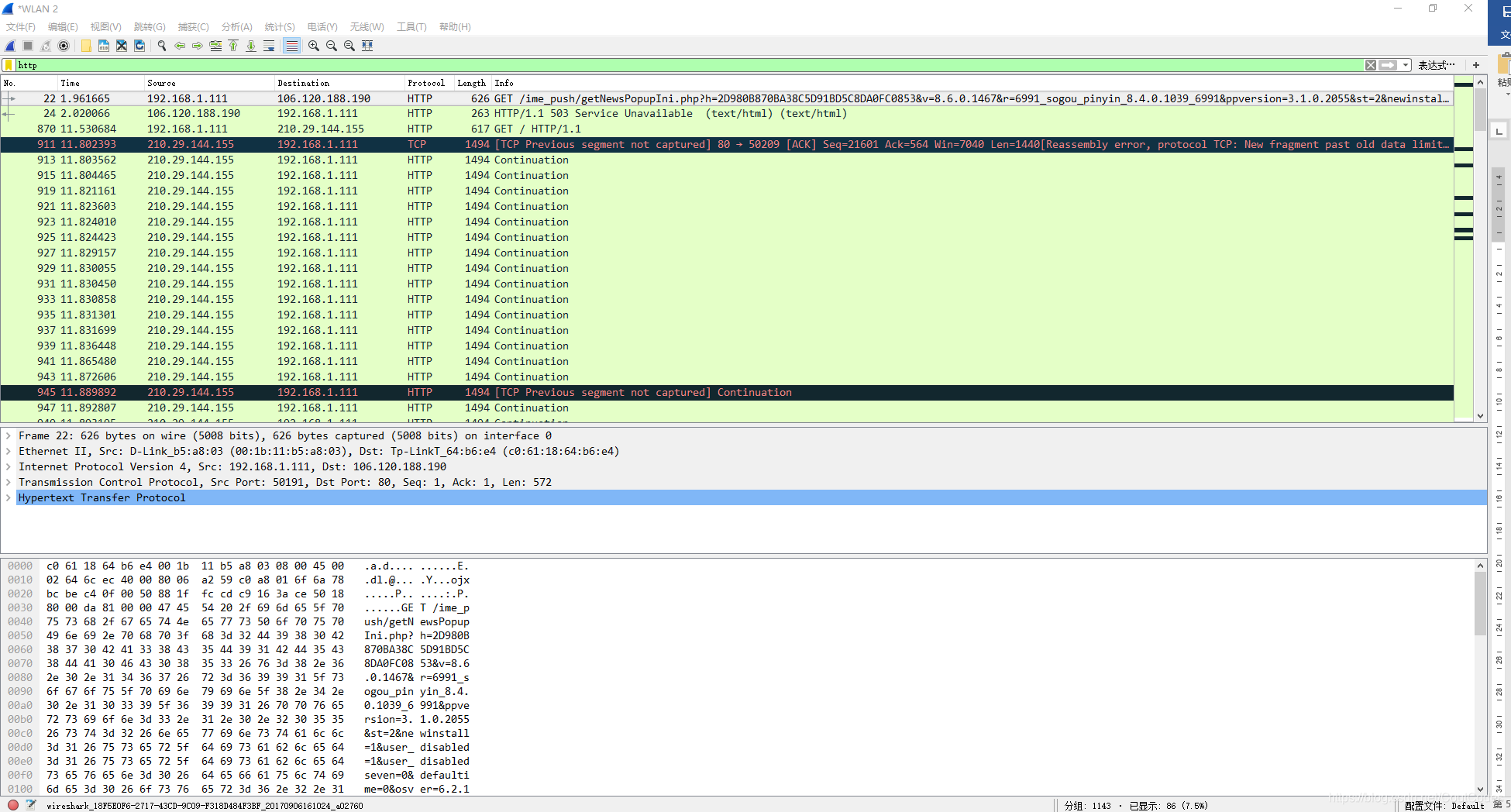
图2
四、 问题与思考
在实验基础上,回答以下问题:
(1) 列出在第5步中分组列表子窗口所显示的所有协议类型;
(2) 从发出HTTP GET报文到接收到对应的HTTP OK响应报文共需要多长时间?(分组列表窗口中Time列的值是从Wireshark开始追踪到分组被捕获的总的时间数,以秒为单位)
(3) 你主机的IP地址是什么?你访问的服务器的IP地址是什么?
实验二 使用Wireshark分析以太网帧与ARP协议
一、实验目的
分析以太网帧,MAC地址和ARP协议
二、实验环境
与因特网连接的计算机网络系统;主机操作系统为windows;使用Wireshark、IE等软件。
三、实验步骤:
1、俘获和分析以太网帧
(1)选择 工具->Internet 选项->删除文件
(2)启动Wireshark 分组嗅探器
(3)在浏览器地址栏中输入如下网址:
http://gaia.cs.umass.edu/wireshark-labs 会出现美国权利法案。
(4)停止分组俘获。在俘获分组列表中(listing of captured packets)中找到HTTP GET 信息和响应信息,如图1所示。
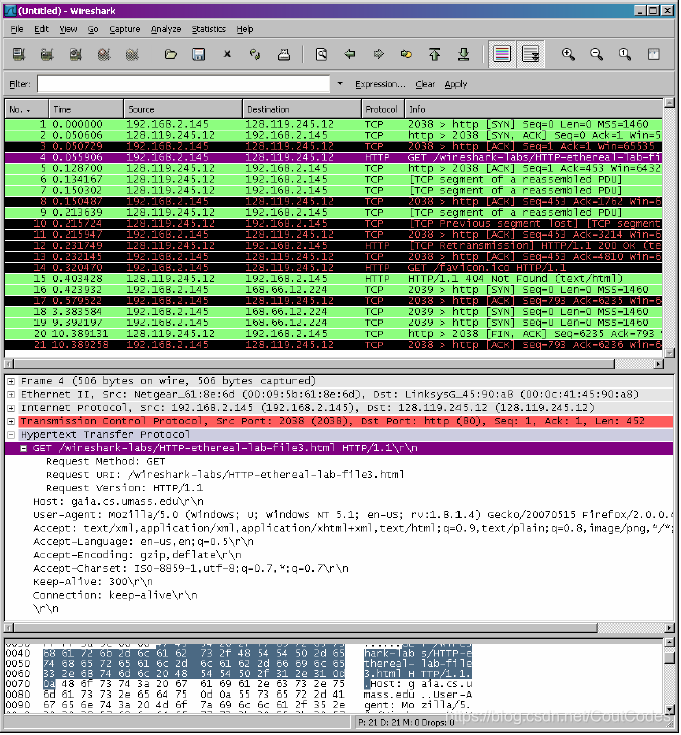
图1 HTTP GET信息和响应信息
(如果你无法俘获此分组,在Wireshark下打开文名为ethernet--ethereal-trace-1的文件进行学习)。
HTTP GET信息被封装在TCP分组中,TCP分组又被封装在IP数据报中,IP数据报又被封装在以太网帧中)。在分组明细窗口中展开Ethernet II信息(packet details window)。
四、问题与思考
1、你所在的主机48-bit Ethernet 地址是多少?
2、Ethernet 帧中目的地址是多少?这个目的地址是gaia.cs.umass.edu的Ethernet 地址吗?
实验三 使用Wireshark分析IP协议
一、实验目的
1、分析IP协议
2、分析IP数据报分片
二、实验环境
与因特网连接的计算机,操作系统为Windows,安装有Wireshark、IE等软件。
三、实验步骤
IP协议是因特网上的中枢。它定义了独立的网络之间以什么样的方式协同工作从而形成一个全球户联网。因特网内的每台主机都有IP地址。数据被称作数据报的分组形式从一台主机发送到另一台。每个数据报标有源IP地址和目的IP地址,然后被发送到网络中。如果源主机和目的主机不在同一个网络中,那么一个被称为路由器的中间机器将接收被传送的数据报,并且将其发送到距离目的端最近的下一个路由器。这个过程就是分组交换。
IP允许数据报从源端途经不同的网络到达目的端。每个网络有它自己的规则和协定。IP能够使数据报适应于其途径的每个网络。例如,每个网络规定的最大传输单元各有不同。IP允许将数据报分片并在目的端重组来满足不同网络的规定。
在4_1_JoiningTheInternet下打开已俘获的分组,分组名为:dhcp_isolated.cap。感兴趣的同学可以在有动态分配IP的实验环境下俘获此分组,此分组具体俘获步骤如下:
1、使用DHCP获取IP地址
(1)打开命令窗口,启动Wireshark。
(2)输入“ipconfig /release”。这条命令会释放主机目前的IP地址,此时,主机IP地址会变为0.0.0.0
(3)然后输入“ipconfig /renew”命令。这条命令让主机获得一个网络配置,包括新的IP地址。
(4)等待,直到“ipconfig /renew”终止。然后再次输入“ipconfig /renew” 命令。
(5)当第二个命令“ipconfig /renew” 终止时,输入命令“ipconfig /release” 释放原来的已经分配的IP地址
(6)停止分组俘获。如图1所示: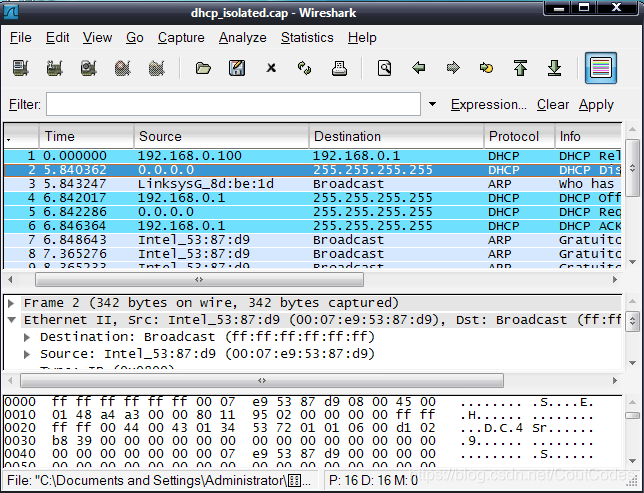
图1 Wireshark俘获的分组
下面,我们对此分组进行分析:
IPconfig 命令被用于显示机器的IP地址及修改IP地址的配置。当输入命ipconfig /release命令时,用来释放机器的当前IP地址。释放之后,该机没有有效的IP地址并在分组2中使用地址0.0.0.0作为源地址。
分组2是一个DHCP Discover(发现)报文,如图2所示。当一台没有IP地址的计算机申请IP地址时将发送该报文。DHCP Discovery报文被发送给特殊的广播地址:255.255.255.255,该地址将到达某个限定广播范围内所有在线的主机。理论上,255.255.255.255能够广播到整个因特网上,但实际上并不能实现,因为路由器为了阻止大量的请求淹没因特网,不会将这样的广播发送到本地网之外。
在DHCP Discover报文中,客户端包括自身的信息。特别是,它提供了自己的主机名(MATTHEWS)和其以太网接口的物理地址(00:07:e9:53:87:d9)。这些信息都被DHCP用来标识一个已知的客户端。DHCP服务器可以使用这些信息实现一系列的策略,比如,分配与上次相同的IP地址,分配一个上次不同的IP地址,或要求客户端注册其物理层地址来获取IP地址。
在DHCP Discover报文中,客户端还详细列出了它希望从DHCP服务器接收到的信息。在Parameter Request List中包含了除客户端希望得到的本地网络的IP地址之外的其他数据项。这些数据项中许多都是一台即将连入因特网的计算机所需要的数据。例如,客户端必须知道的本地路由器的标识。任何目的地址不在本地网的数据报都将发送到这台路由器上。也就是说,这是发向外网的数据报在通向目的端的路径上遇到的第一台中间路由器。
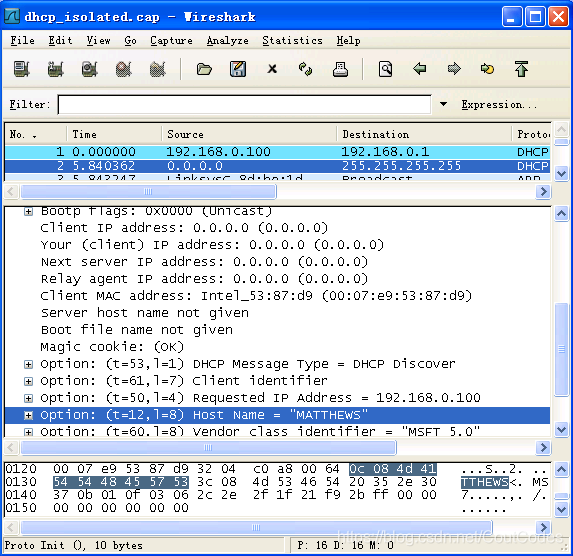
图2 DHCP Discovery
客户端必须知道自己的子网掩码。子网掩码是一个32位的数,用来与IP地址进行“按
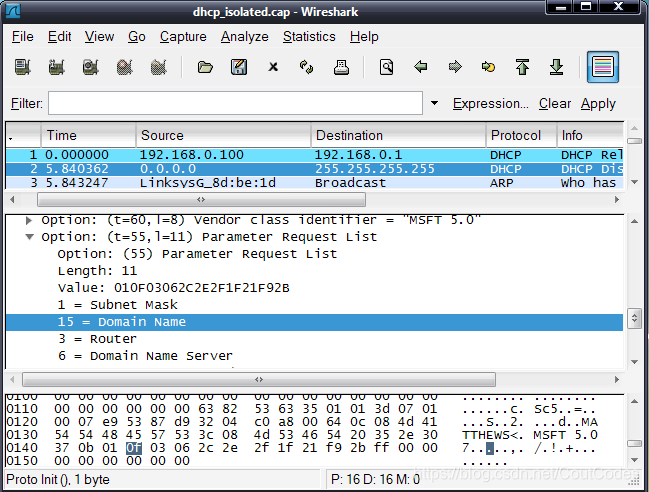
图2 Parameter Request List
位逻辑与运算”从而得出网络地址。所有可以直接通信而不需要路由器参与的机器都有相同的网络地址。因此,子网掩码用来决定数据报是发送到本地路由器还是直接发送到本地目的主机。
客户端还必须知道它们的域名和它们在本地域名服务器上的标识。域名是一个可读的网络名。
IP地址为192.168.0.1的DHCP服务器回复了一个DHCP OFFER报文。该报文也广播到255.255.255.255,因为尽管客户端还不知道自己的IP地址,但它将接收到发送到广播地址的报文。这个报文中包含了客户端请求的信息,包括IP地址、本地路由器、子网掩码、域名和本地域名服务器。
在分组5中,客户端通过发送DHCP Request(请求)报文表明自己接收到的IP地址。最后,在分组6中DHCP服务器确认请求的地址并结束对话。此后,在分组7中客户端开始使用它的新的IP地址作为源地址。
在分组3和分组7到12的地址ARP协议引起了我们的注意。在分组3中,DHCP服务器询问是否有其它主机使用IP地址192.168.0.100(该请求被发送到广播地址)。这就允许DHCP服务器在分配IP之前再次确认没有其它主机使用该IP地址。在获取其IP地址之后,客户端会发送3个报文询问其他主机是否有与自己相同的IP地址。前4个ARP请求都没有回应。在分组10—13中,DHCP服务器再次询问哪个主机拥有IP地址192.168.0.100,客户端两次回答它占有该IP同时提供了自己的以太网地址。
通过DHCP分配的IP地址有特定的租用时间。为了保持对某个IP的租用,客户端必须更新租用期。当输入第二个命令ipconfig /renew后,在分组14和15中就会看到更新租用期的过程。DHCP Request请求更新租用期。DHCP ACK包括租用期的长度。如果在租用期到期之前没有DHCP Request发送,DHCP服务器有权将该IP地址重新分配给其他主机。
最后,在分组16时输入命令ipconfig /release后的结果。在DHCP服务器接收到这个报文后,客户停止对该IP的使用。如有需要DHCP服务器有权重新对IP地址进行分配。
2、分析IPv4中的分片
在第二个实验中,我们将考察IP数据报首部。俘获此分组的步骤如下:
(1) 启动Wireshark,开始分组俘获(“Capture”-----“interface…”----“start”)。
(2) 启动pingplotter(pingplotter 的下载地址为www.pingplotter.com),在“Address to trace:”下面的输入框里输入目的地址,选择菜单栏“Edit”---“Options”---“Packet”,在“Packet size(in bytes defaults=56):”
右边输入IP数据报大小:5000,按下“OK”。最后按下按钮“Trace”,你将会看到pingplotter窗口显示如下内容,如图3所示:
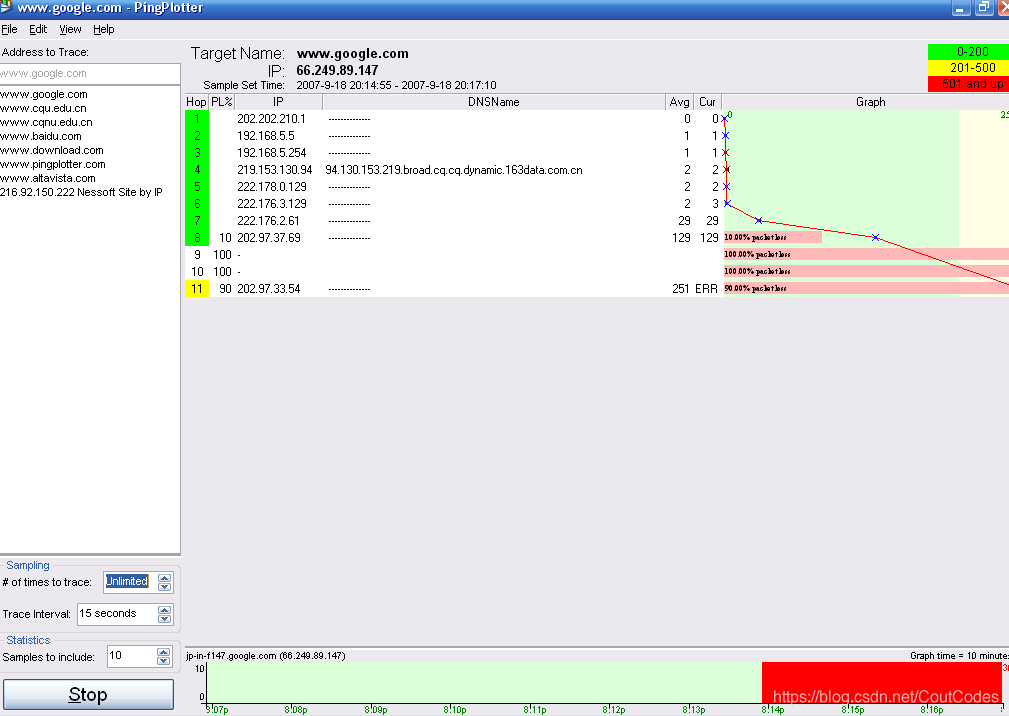
图3 ping plotter
(3) 停止Wireshark。设置过滤方式为:IP,在Wireshark窗口中将会看到如下情形,如图4所示。
在分组俘获中,你应该可以看到一系列你自己电脑发送的“ICMP Echo Request”和由中间路由器返回到你电脑的“ICMP TTL-exceeded messages。
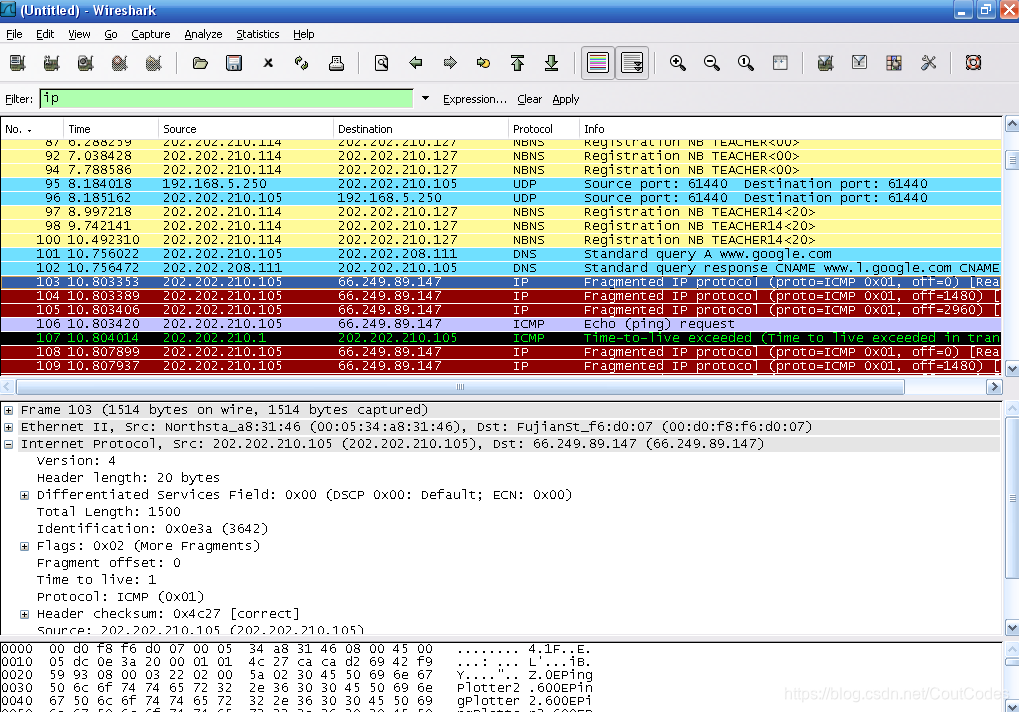
图4 用Wireshark 所俘获的分组
(4) 如果你无法得到上图的分组信息,也可使用已经下载的IP分片分组文件:fragment_5000_isolated.cap。然后在Wireshark中,选择菜单栏“File”---“Open”导入上述文件进行学习。
下面,我们来分析fragment_5000_isolated.cap中的具体分组:
IP层位于传输层和链路层之间。在fragment_5000_isolated.cap中传输层协议是UDP,链路层协议是以太网。发送两个UDP数据报,每个包含5000个字节的数据部分和8字节的UDP首部。在分组1到4和分组5到8分别代表了先后发送的两个UDP数据报。
当IP层接收到5008字节的UDP数据报时,它的工作是将其作为IP数据报在以太网传输。以太网要求一次传输的长度不大于1514个字节,其中有14字节是以太网帧首部。
IP被迫将UDP数据报作为多个分片发送。每个分片必须包含以太网帧首部、IP数据报首部。每个分片还会包含UDP数据报的有效负载(首部和数据)的一部分。
IP将原始数据报的前1480个字节(含1472个字节的数据和含8个字节的UDP首部)放在第一个分片中。后面两个分片每个均含1480个字节的数据,最后一个分片中包含的数据为568个字节)。
为了让接收段重组原始数据,IP使用首部的特殊字段对分片进行了编号。标识字段用于将所有的分片连接在一起。分组1到4含有相同的标识号0xfd2b,分组5到8的标识号是0xfd2c.片漂移量指明了分组中数据的第一个字节在UDP数据报中的偏移量。例如分组1和分组5的偏移量都是0,因为它们都是第一个分片。
最后在标识字段中有一位用来指明这个分片后是否还有分片。分组1到分组3和分组5到分组7均对该位置进行了置位。分组4和分组8由于是最后一个分片而没有对该位置位。
四、问题与思考
打开文件dhcp_isolated.cap、fragment_5000_isolated.cap,回答以下问题:
1、DHCP服务器广播的本地路由器或默认网关的IP地址是多少?
2、在dhcp_isolated.cap中,由DHCP服务器分配的域名是多少?
3、在fragment_5000_isolated.cap中,我们看到通过UDP数据报发送的5000字节被分成了多少分片?在网络中,一次能传输且不需要分片的最大数据单元有多大?
实验四 利用Wireshark分析ICMP
一、实验目的
分析ICMP
二、实验环境
与因特网连接的计算机,操作系统为Windows,安装有Wireshark、IE等软件。
三、实验步骤
Ping和traceroute命令都依赖于ICMP。ICMP可以看作是IP协议的伴随协议。ICMP报文被封装在IP 数据报发送。
一些ICMP报文会请求信息。例如:在ping中,一个ICMP回应请求报文被发送给远程主机。如果对方主机存在,期望它们返回一个ICMP回应应答报文。
一些ICMP报文在网络层发生错误时发送。例如,有一种ICMP报文类型表示目的不可达。造成不可达的原因很多,ICMP报文试图确定这一问题。例如,可能是主机关及或整个网络连接断开。
有时候,主机本身可能没有问题,但不能发送数据报。例如IP首部有个协议字段,它指明了什么协议应该处理IP数据报中的数据部分。IANA公布了代表协议的数字的列表。例如,如果该字段是6,代表TCP报文段,IP层就会把数据传给TCP层进行处理;如果该字段是1,则代表ICMP报文,IP层会将该数据传给ICMP处理。如果操作系统不支持到达数据报中协议字段的协议号,它将返回一个指明“协议不可达”的ICMP报文。IANA同样公布了ICMP报文类型的清单。
Traceroute是基于ICMP的灵活用法和IP首部的生存时间字段的。发送数据报时生存时间字段被初始化为能够穿越网络的最大跳数。每经过一个中间节点,该数字减1。当该字段为0时,保存该数据报的机器将不再转发它。相反,它将向源IP地址发送一个ICMP生存时间超时报文。
生存时间字段用于避免数据报载网络上无休止地传输下去。数据报的发送路径是由中间路由器决定的。通过与其他路由器交换信息,路由器决定数据报的下一条路经。最好的“下一跳”经常由于网络环境的变化而动态改变。这可能导致路由器形成选路循环也会导致正确路径冲突。在路由循环中这种情况很可能发生。例如,路由器A认为数据报应该发送到路由器B,而路由器B又认为该数据报应该发送会路由器A,这是数据报便处于选路循环中。
生存时间字段长为8位,所以因特网路径的最大长度为28 -1即255跳。大多数源主机将该值初始化为更小的值(如128或64)。将生存时间字段设置过小可能会使数据报不能到达远程目的主机,而设置过大又可能导致处于无限循环的选路中。
Traceroute利用生存时间字段来映射因特网路径上的中间节点。为了让中间节点发送ICMP生存时间超时报文,从而暴露节点本身信息,可故意将生存时间字段设置为一个很小的书。具体来说,首先发送一个生存时间字段为1的数据报,收到ICMP超时报文,然后通过发送生存时间字段设置为2的数据报来重复上述过程,直到发送ICMP生存时间超时报文的机器是目的主机自身为止。
因为在分组交换网络中每个数据报时独立的,所以由traceroute发送的每个数据报的传送路径实际上互不相同。认识到这一点很重要。每个数据报沿着一条路经对中间节点进行取样,因此traceroute可能暗示一条主机间并不存在的连接。因特网路径经常变动。在不同的日子或一天的不同时间对同一个目的主机执行几次traceroute命令来探寻这种变动都会得到不同的结果。
为了体现Internet路由的有限可见性,许多网络都维护了一个traceroute服务器traceroute。Traceroute服务器将显示出从本地网到一个特定目的地执行traceroute的结果。分布于全球的traceroute服务器的相关信息可在http://www.traceroute.org上获得。
1、ping 和 ICMP
利用Ping程序产生ICMP分组。Ping向因特网中的某个特定主机发送特殊的探测报文并等待表明主机在线的回复。具体做法:
(1)打开Windows命令提示符窗口(Windows Command Prompt)。
(2)启动Wireshark 分组嗅探器,在过滤显示窗口(filter display window)中输入icmp,开始Wireshark 分组俘获。
(3)输入“ping –n 10 hostname” 。其中“-n 10”指明应返回10条ping信息。
(4)当ping程序终止时,停止Wireshark 分组俘获。
实验结束后会出现如图所示的命令窗口:
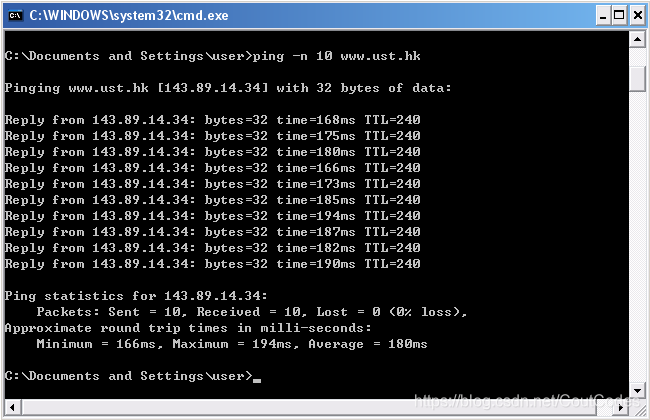
图1 命令窗口
停止分组俘获后,会出现如图2所示的界面:
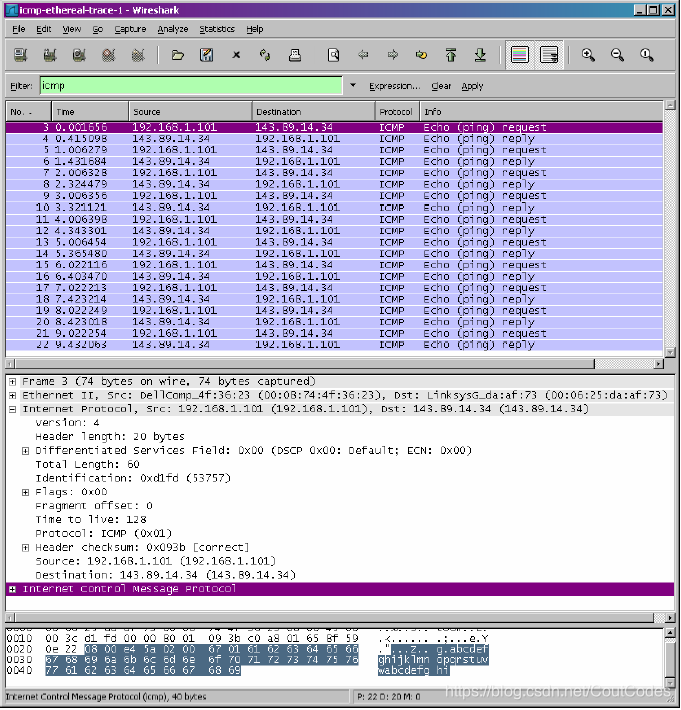
图2 停止分组俘获后Wireshark的界面
图3是在分组内容窗口中显示了ICMP协议的详细信息。观察这个ICMP分组,可以看出,此ICMP分组的Type 8 and Code 0 即所谓的ICMP “echo request” 分组。
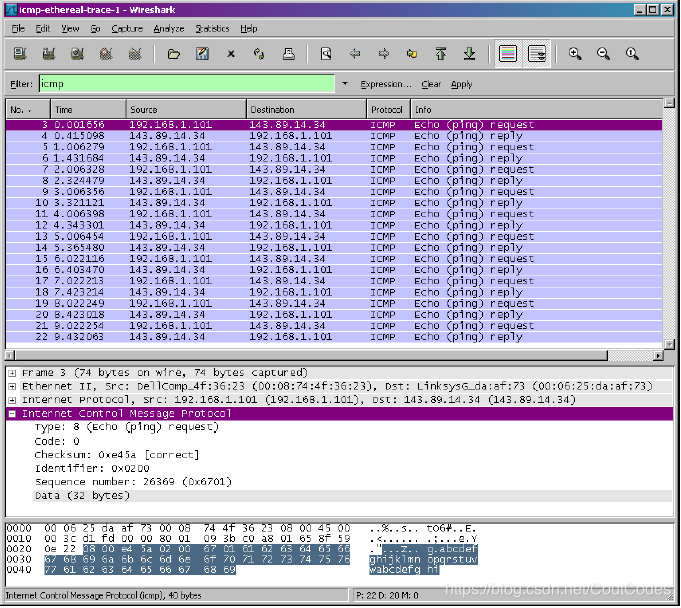
图3 ICMP协议详细信息
根据操作回答“四、问题与思考”中的1-3题。
2. ICMP和Traceroute
在Wireshark 下,用Traceroute程序俘获ICMP分组。Traceroute能够映射出通往特定的因特网主机途径的所有中间主机。
源端发送一串ICMP分组到目的端。发送的第一个分组时,TTL=1;发送第二个分组时,TTL=2,依次类推。路由器把经过它的每一个分组TTL字段值减1。当一个分组到达了路由器时的TTL字段为1时,路由器会发送一个ICMP错误分组(ICMP error packet)给源端。
(1) 启动Window 命令提示符窗口
(2) 启动Wireshark分组嗅探器,开始分组俘获。
(3)Tracert命令在c:\windows\system32下,所以在MS-DOS 命令提示行或者输入“tracert hostname” or “c:\windows\system32\tracert hostname” (注意在Windows 下, 命令是 “tracert” 而不是“traceroute”。)如图4所示:
(4)当Traceroute 程序终止时,停止分组俘获。
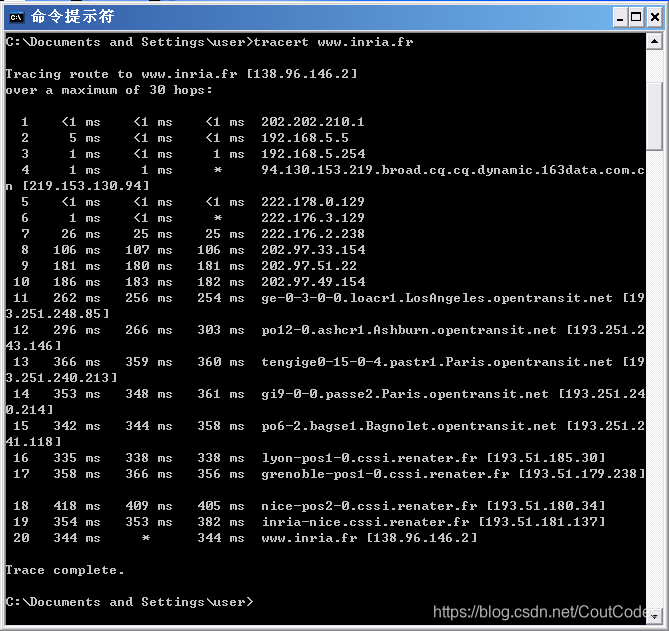
图4 命令提示窗口显示Traceroute程序结果
图5显示的是一个路由器返回的ICMP错误分组(ICMP error packet)。注意到ICMP错误分组中包括的信息比Ping ICMP中错误分组包含的信息多。
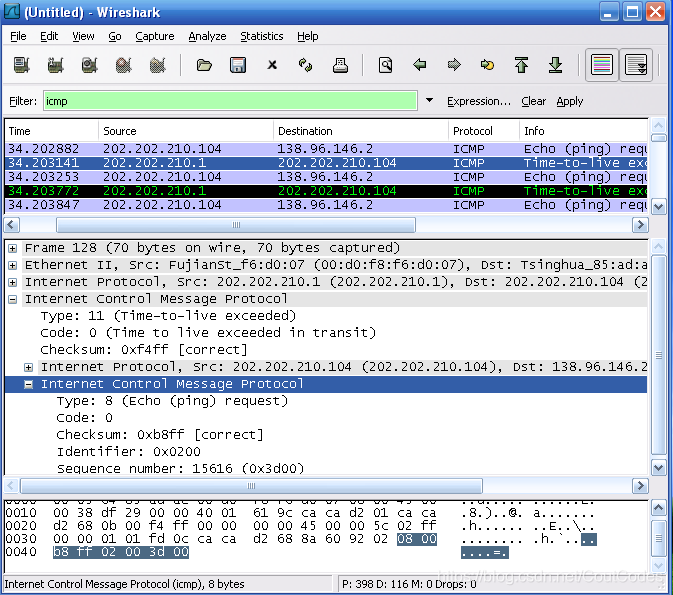
图5 一个扩展ICMP错误分组信息的Wireshark 窗口
根据操作回答“四、问题与思考”中的4-5题。
四、问题与思考
在实验的基础上,回答以下问题:
(1)你所在主机的IP地址是多少?目的主机的IP地址是多少?
(2)查看ping请求分组,ICMP的type 和code是多少?
(3)查看相应得ICMP响应信息,ICMP的type 和code又是多少?
(4)查看ICMP echo 分组 ,是否这个分组和前面使用 ping命令的ICMP echo 一样?
(5)ICMP错误分组比ICMP echo 分组多包含的信息有哪些?
(6)连接层的IP地址是多少?
(7)ICMP的type 和code是多少?
实验五 使用Wireshark分析UDP协议
一、实验目的
比较TCP和UDP协议的不同
二、实验环境
与因特网连接的计算机,操作系统为Windows,安装有Wireshark、IE等软件。
三、实验步骤
1、打开两次TCP流的有关跟踪记录,保存在tcp_2transmit.cap中,并打开两次UDP流中的有关跟踪文件udp_2transmit.cap 。如图所示:
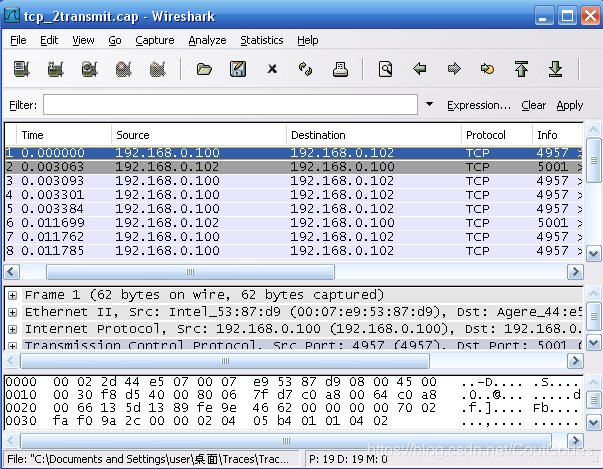
图1 TCP 流跟踪记录
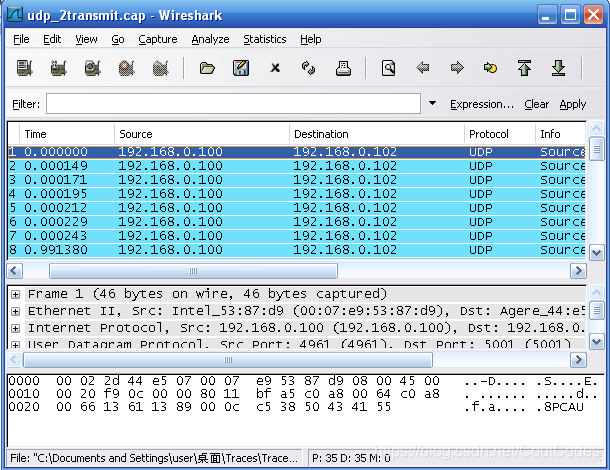
图2 UDP流跟踪记录
2、分析此数据包:
(1)TCP传输的正常数据:
tcp_2transmit.cap文件的分组1到13中显示了TCP连接。这个流中的大部分信息与前面的实验相同。我们在分组1到分组3中看到了打开连接的三次握手。分组10到分组13显示的则是连接的终止。我们看到分组10既是一个带有FIN标志的请求终止连接的分组,又是一个最后1080个字节的(序号是3921—5000)的重传。
TCP将应用程序写入合并到一个字节流中。它并不会尝试维持原有应用程序写人的边界值。我们注意到TCP并不会在单个分组中传送1000字节的应用程序写入。前1000个字节会在分组4种被发送,而分组5则包含了1460个字节的数据-----一些来自第二个缓冲区,而另一些来自第三个缓冲区。分组7中含有1460个字节而分组8中则包含剩余的1080个字节。(5000-1000-1460-1460=1080)
我们注意到实际报告上的2.48秒是从初始化连接的分组1开始到关闭连接的分组10结束。分组11—13未必要计入接收端应用程序的时间内,因为一旦接收到第一个FIN,TCP层便马上发送一个关闭连接的信号。分组11—13只可能由每台计算机操作系统得TCP层后台传输。
如果我们注意到第一个包含数据的分组4和最后一个分组8之间的时间,我们就大约计算出和由UDP接收端所报告的0.01秒相同的时间。这样的话,增加TCP传输时间的主要原因就是分组10中的重传。公平的说,UDP是幸运的,因为它所有的分组都在第一时间被接受了。
在这个跟踪文件中,另一个值得注意的是没有包含数据的分组的数量。所有来自接收端的分组和几个来自发送端的分组只包含了TCP报文段的首部。总的来说(包括重传)一共发送了6822个字节来支持5000个字节的数据传输。这个开销正好36﹪。
(2)UDP正常数据传输
现在我们来观察UDP流,在udp _transmit.cap文件的分组1到分组11中显示。虽然像TCP流那样传输了相同的数据,但是在这个跟踪文件中还是很多的不同。
和TCP不同,UDP是一个无连接的传输协议。TCP用SYN分组和SYN ACK分组来显示地打开一个连接,而UDP却直接开始发送包含数据的分组。同样,TCP用FIN分组和FIN ACK分组来显示地关闭一个连接,而UDP却只简单地停止包含数据的分组的传输。
为了解决这个问题,在文件udp_2transmit.cap俘获的分组中,采取的办法是ttcp发送端发送一个只包含4个字节的特殊UDP 数据报来模拟连接建立和连接终止。在发送任何数据之前,发送端总是发送一个只包含4个字节的特殊数据报(分组1),而在发送完所有的数据之后,发送端又发送额外的5个分组(分组7-11)。
接收端也使用第一个特殊的数据报来启动数据传输的计时器。如果这个特殊的数据报丢失了,它可能用真实数据的第一个分组计时器。不过,如果接收端没有看到这个特殊的数据报,它就不能精确地确定数据传输的开始和传输的所有时间。与TCP不同,UDP 在传输的数据中,不会加上序号,因此对于接收端来说不可能确定丢失和重排序重传的情况。
类似的,接收端根据最后的特殊数据报来停止数据传输计时器。当接收端接收到这5个包中的任一个便停止计时,但是发送5个分组是因为在传输的过程中可能丢失其中的一些。如果5个分组全部丢失了,那么接收端便会无限制的等待更多数据的到来达。
实际数据的传输是在分组2-6里。每一个分组都包含1000个字节。1000个字节的应用程学写入直接转换成UDP数据报。另一方面,TCP并不打算保存应用程序写入边界而只是将它们并入一个字节流中。
与TCP不同,UDP没有提供接收端到发送端的反馈。在TCP的例子里,接收端返回只包含有TCP报文段首部而没有数据的报文段。首部本身则携带着关于哪些数据已经被成功接收以及接收端能够接收多少数据的信息。我们已经知道UDP不提供可靠的数据传输,因此并不要求什么数据已经被成功接收的信息。它也不提供任何信息高速发送端降低速率,因为接收端或者网络本身已经淹没。
虽然UDP本身并不提供接收端到发送端的反馈,但是我们确实看到几个从接收端到发送端的ICMP分组(分组12—14)。ICMP是网络层协议(IP)的一个伴随协议,并且有提供一定控制和错误报告的功能。在这种情况下,ICMP分组暗示一些UDP数据报没有被传送到,因为端口不可达。这就意味着当数据报到达那个端口的时候,没有接收端在那个端口监听。我们注意到ICMP分组携带着一些未传递UDP数据报的信息。
当ttcp接收端看到一个只具有4个字节数据的特殊数据报时,它便会知道数据传输是完整的,并且会因此关闭正在监听的端口。事实上ttcp发送端发送5个这样的分组,并且后面的分组到达的时候发现接收端已经没有在监听了。当发送端发送所有的数据而没有相应的接收标志的时候,将会看到相似的行为。
TCP和UDP的另外一个不同之处在于TCP连接时点对点的,换句话说,TCP的使用是在一个连接端和一个发送端之间的。而对于UDP来说,一个发送端可能发向多个接收端(例如广播和组播通信)或者多个发送端能够发送给一个接收端。如果多个发送端都发给这个接收端的话,这个接收端会为每个发送端报告统计信息。
TCP和UDP的最后一个不同之处是它们首部的大小。UDP首部总是8个字节,而TCP首部大小是变化的,但是它绝对不会少于20个字节。这也就是说传输5000个字节的实际数据TCP的开销是36﹪。
四、问题与思考
在实验的基础上,回答以下问题:
1、在udp_2transmit.cap中观察DUP首部。长度字段是包括首部和数据还是只包括数据?
2、我们观察到使用ICMP报文来报告UDP数据报不可达。为什么TCP不用这个来指示丢失的报文段呢?
3、我们计算TCP成功传输5000个字节的实际数据的开销是36﹪。在这个开销中都包括什么?如果没有重传,这个开销是多少?
实验六 使用Wireshark分析TCP协议
一、实验目的
分析TCP协议
二、实验环境
与因特网连接的计算机,操作系统为Windows,安装有Wireshark、IE等软件。
三、实验步骤
1、TCP介绍
(1)连接建立:
TCP连接通过称为三次握手的三条报文来建立的。在Wireshark中选择open->file,选择文件tcp_pcattcp_n1.cap,其中分组3到5显示的就是三次握手。
第一条报文没有数据的TCP报文段,并将首部SYN位设置为1。因此,第一条报文常被称为SYN分组。这个报文段里的序号可以设置成任何值,表示后续报文设定的起始编号。连接不能自动从1开始计数,选择一个随机数开始计数可避免将以前连接的分组错误地解释为当前连接的分组。观察分组3,Wireshark显示的序号是0。选择分组首部的序号字段,原始框中显示“94 f2 2e be”。Wireshark显示的是逻辑序号,真正的初始序号不是0。如图1所示:
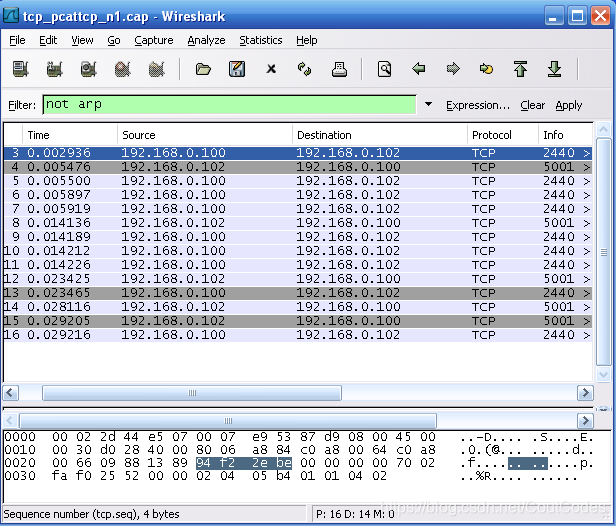
图1:逻辑序号与实际初始序号
SYN分组通常是从客户端发送到服务器。这个报文段请求建立连接。一旦成功建立了连接,服务器进程必须已经在监听SYN分组所指示的IP地址和端口号。如果没有建立连接,SYN分组将不会应答。如果第一个分组丢失,客户端通常会发送若干SYN分组,否则客户端将会停止并报告一个错误给应用程序。
如果服务器进程正在监听并接收到来的连接请求,它将以一个报文段进行相应,这个报文段的SYN位和ACK位都置为1。通常称这个报文段为SYNACK分组。SYNACK分组在确认收到SYN分组的同时发出一个初始的数据流序号给客户端。
分组4的确认号字段在Wireshark的协议框中显示1,并且在原始框中的值是“94 f2 2e bf”(比“94 f2 2e be”多1)。这解释了TCP的确认模式。TCP接收端确认第X个字节已经收到,并通过设置确认号为X+1来表明期望收到下一个字节号。分组4的序号字段在Wireshark的协议显示为0,但在原始框中的实际值却是“84 ca be b3”。这表明TCP连接的双方会选择数据流中字节的起始编号。所有初始序号逻辑上都视同为序号0。
最后,客户端发送带有标志ACK的TCP报文段,而不是带SYN的报文段来完成三次握手的过程。这个报文段将确认服务器发送的SYNACK分组,并检查TCP连接的两端是否正确打开合运行。
(2)关闭连接
当两端交换带有FIN标志的TCP报文段并且每一端都确认另一端发送的FIN包时,TCP连接将会关闭。FIN位字面上的意思是连接一方再也没有更多新的数据发送。然而,那些重传的数据会被传送,直到接收端确认所有的信息。在tcp_pcattcp_n1.cap中,通过分组13至16我们可以看到TCP连接被关闭。
2、TCP重传
当一个TCP发送端传输一个报文段的同时也设置了一个重传计时器。当确认到达时,这个计时器就自动取消。如果在数据的确认信息到达之前这个计时器超时,那么数据就会重传。
重传计时器能够自动灵活设置。最初TCP是基于初始的SYN和SYN ACK之间的时间来设置重传计时器的。它基于这个值多次设置重传计时器来避免不必要的重传。在整个TCP连接中,TCP都会注意每个报文段的发送和接到相应的确认所经历的时间。TCP在重传数据之前不会总是等待一个重传计算器超时。TCP也会把一系列重复确认的分组当作是数据丢失的征兆。
在Wireshark中选择file-〉open,打开文件pcattcp_retrans_t.cap和pcattcp_retrans_r.cap,对所俘获的分组进行分析如下:
(1) SACK选项协商
在上面的每次跟踪中,我们能观察建立连接的三次握手。在SYN分组中,发送端在TCP的首部选项中通过包括SACK permitted选项来希望使用TCP SACK。在SYN ACK包中接收端表示愿意使用SACK。这样双方都同意接收选择性确认信息。SACK选项如图2所示:
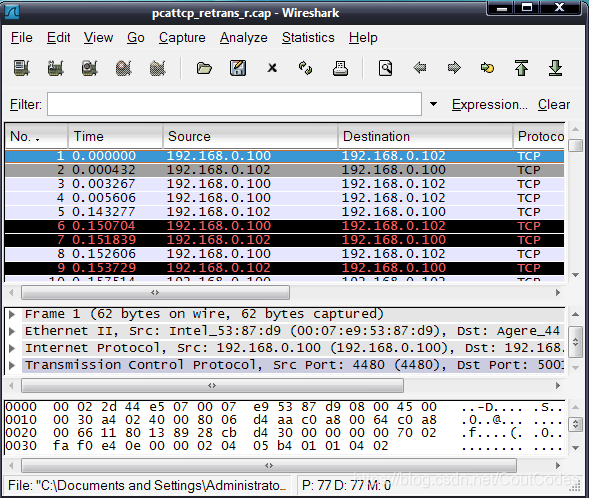
图2 SACK选项
在TCP SACK选项中,如果连接的一端接收了失序数据,它将使用选项区字段来发送关于失序数据起始和结束的信息。这样允许发送端仅仅重传丢失的数据。TCP接收端不能传递它们接收到的失序数据给处于等待状态的应用程序,因为它总是传递有序数据。因此,接收到的失序数据要么被丢掉,要么被存储起来。
接收端的存储空间是有限的,TCP发送端必须保存一份已发送的数据的副本,以防止数据需要重发。发送端必须保存数据直到它们收到数据的确认信息为止。
接收端通常会分配一个固定大小的缓冲区来存储这些失序数据和需要等待一个应用程序读取的数据。如果缓冲区空间不能容纳下更多数据,那么接收端只有将数据丢弃,即使它是成功到达的。接收端的通知窗口字段用来通知发送端还有多少空间可以用于输入数据。如果数据发送的速度快于应用程序处理数据的速度,接收端就会发送一些信息来告知发送端其接收窗口正在减小。在这个跟踪文件中,接收端通知窗口的大小是变化的,从16520个字节到17520个字节。
TCP发送端在发送之前有一个容纳数据的有限空间。然而,和接收端不同的是,发送端是限制自己的发送速率。如果缓冲区的空间满了,尝试写入更多数据的应用程序将被阻塞直到有更多的空间可以利用为止。
(2)分组的丢失与重传
用显示过滤器tcp.analysis.retransmission搜索重传。在pcattcp_retrans_t.cap中应用该过滤器,在这个跟踪文件中,我们看见分组12是这9次重传的第一次。如图所示3:
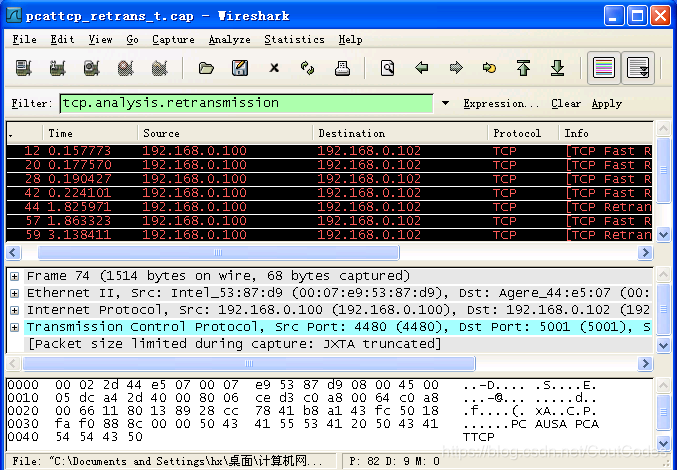
图3 pcattcp_retrans_t.cap中9次重传
通过观察分组12的细节,我们发现序号是1001,我们发现分组5也有同样的序号。有趣的是,分组5是对1001到2460号字节的传输,而分组12却是对1001到2000号字节的重传。分组20是对2001到2460号字节的重传。
分组4是对1到1000号字节的传输,分组5是对1001到2460号字节的传输,分组7是对2461到3920号字节的传输。
我们已检查了发送端上获取的所有跟踪记录。我们从接收端的角度来看同一个连接,我们会发现有些不同。在pcattcp_retrans_r.cap中,我们发现1到1000号字节是在分组4里被传送的,而2461到3920号字节是在分组6(而不是分组7)中被传送的。在这个跟踪文件中,分组5是1到1000号字节的确认。我们没有看到1001到2460号字节的传输。但是他们确实被传输送了,只是在发送端和接收端的某个环节丢失了。
现在我们来看接收端是如何处理这些丢失字节的。在分组4达到以后,接收端会以确认号1001(分组5)作为响应。在分组6的2461到3920号字节达到之后,接收端仍然以确认号1001(分组7)作为响应。即使它接到的是附加数据,确认号仍然是它期望收到的下一个有序字节的序号。同样在含有3921到5381号字节的分组8到达之后,接收端仍然以1001响应。
最后,1001到2000号字节被重传。在这两次跟踪中,我们都在分组12里看到这种情况。于是接收端增加它的确认号到2001。
最终2001到2460号字节被重传。在这次重传之后,接收端可以立即从确认字节2001跳到确认字节11221。
四、问题与思考
在实验的基础上,回答以下问题:
1、 客户服务器之间用于初始化TCP连接的TCP SYN报文段的序号(sequence number)是多少?在该报文段中,是用什么来标识该报文段是SYN报文段的?
2、 服务器向客户端发送的SYNACK报文段序号是多少?该报文段中,ACKnowledgement字段的值是多少?
3、 找出pcattcp_retrans_t.cap中所有在到达接收端之前丢失的分组。对于每个丢失的报文段,找出重传分组(提示:找出第一个丢失的字节和重传它们的分组).
4、 当接收端发送一个TCP报文段来确认收到的数据时,这个报文段也可能丢失。在pcattcp_retrans_t.cap和pcattcp_retrans_r.cap中存在这样的丢失吗?你是怎么得到这样的答案的?
实验七 利用Wireshark分析协议HTTP
一、实验目的
分析HTTP协议
二、实验环境
与因特网连接的计算机,操作系统为Windows,安装有Wireshark、IE等软件。
三、实验步骤
1、利用Wireshark俘获HTTP分组
(1)在进行跟踪之前,我们首先清空Web 浏览器的高速缓存来确保Web网页是从网络中获取的,而不是从高速缓冲中取得的。之后,还要在客户端清空DNS高速缓存,来确保Web服务器域名到IP地址的映射是从网络中请求。在WindowsXP机器上,可在命令提示行输入ipconfig/flushdns完成操作。
(2)启动Wireshrk 分组俘获器。
(3)在Web 浏览器中输入:http://www.google.com
(4)停止分组俘获。
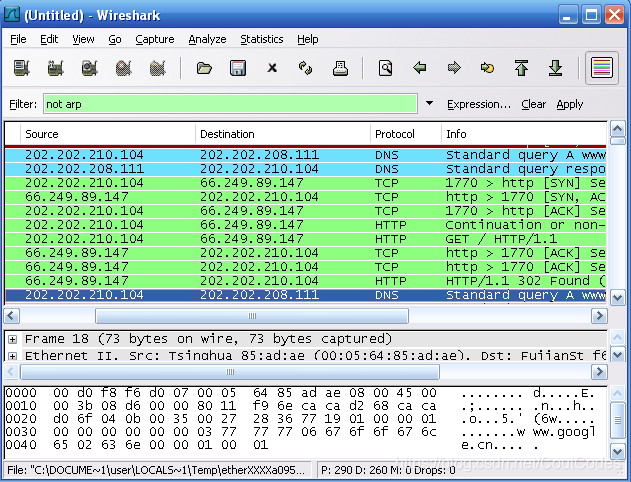
图1 利用Wireshark俘获的HTTP分组
在URL http://www.google.com中,www.google.com 是一个具体的web 服务器的域名。最前面有两个DNS分组。第一个分组是将域名www.google.com转换成为对应的IP 地址的请求,第二个分组包含了转换的结果。这个转换是必要的,因为网络层协议——IP协议,是通过点分十进制来表示因特网主机的,而不是通过www.google.com这样的域名。当输入URL http://www.google.com时,将要求Web服务器从主机www.google.com上请求数据,但首先Web浏览器必须确定这个主机的IP地址。
随着转换的完成,Web浏览器与Web服务器建立一个TCP连接。最后,Web 浏览器使用已建立好的TCP连接来发送请求“GET/HTTP/1.1”。这个分组描述了要求的行为(“GET”)及文件(只写“/”是因为我们没有指定额外的文件名),还有所用到的协议的版本(“HTTP/1.1”)。
2、HTTP GET/response交互
(1)在协议框中,选择“GET/HTTP/1.1” 所在的分组会看到这个基本请求行后跟随着一系列额外的请求首部。在首部后的“\r\n”表示一个回车和换行,以此将该首部与下一个首部隔开。
“Host”首部在HTTP1.1版本中是必须的,它描述了URL中机器的域名,本例中是www.google.com。这就允许了一个Web服务器在同一时间支持许多不同的域名。有了这个数不,Web服务器就可以区别客户试图连接哪一个Web服务器,并对每个客户响应不同的内容,这就是HTTP1.0到1.1版本的主要变化。
User-Agent首部描述了提出请求的Web浏览器及客户机器。
接下来是一系列的Accpet首部,包括Accept(接受)、Accept-Language(接受语言)、Accept-Encoding(接受编码)、Accept-Charset(接受字符集)。它们告诉Web服务器客户Web浏览器准备处理的数据类型。Web服务器可以将数据转变为不同的语言和格式。这些首部表明了客户的能力和偏好。
Keep-Alive及Connection首部描述了有关TCP连接的信息,通过此连接发送HTTP请求和响应。它表明在发送请求之后连接是否保持活动状态及保持多久。大多数HTTP1.1连接是持久的(persistent),意思是在每次请求后不关闭TCP连接,而是保持该连接以接受从同一台服务器发来的多个请求。
(2)我们已经察看了由Web浏览器发送的请求,现在我们来观察Web服务器的回答。响应首先发送“HTTP/1.1 200 ok”,指明它开始使用HTTP1.1版本来发送网页。同样,在响应分组中,它后面也跟随着一些首部。最后,被请求的实际数据被发送。
第一个Cache-control首部,用于描述是否将数据的副本存储或高速缓存起来,以便将来引用。一般个人的Web浏览器会高速缓存一些本机最近访问过的网页,随后对同一页面再次进行访问时,如果该网页仍存储于高速缓存中,则不再向服务器请求数据。类似地,在同一个网络中的计算机可以共享一些存在高速缓存中的页面,防止多个用户通过到其他网路的低速网路连接从网上获取相同的数据。这样的高速缓存被称为代理高速缓存(proxy cache)。在我们所俘获的分组中我们看到“Cache-control”首部值是“private”的。这表明服务器已经对这个用户产生了一个个性化的响应,而且可以被存储在本地的高速缓存中,但不是共享的高速缓存代理。
在HTTP请求中,Web服务器列出内容类型及可接受的内容编码。此例中Web服务器选择发送内容的类型是text/html且内容编码是gzip。这表明数据部分是压缩了的HTML。
服务器描述了一些关于自身的信息。此例中,Web服务器软件是Google自己的Web服务器软件。响应分组还用Content-Length首部描述了数据的长度。最后,服务器还在Date首部中列出了数据发送的日期和时间。
根据俘获窗口内容,回答“四、实验报告内容”中的1-6题。
3、HTTP条件GET/response交互
(1)启动浏览器,清空浏览器的缓存。
(2)启动Wireshark分组俘获器,开始Wireshark分组俘获。
(3)在浏览器地址栏中如下网址:
http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file2.html
你的浏览器中将显示一个具有五行的非常简单的HTML文件。
(4)在你的浏览器中重新输入相同的URL或单击浏览器中的“刷新”按钮。
(5)停止Wireshark分组俘获,在显示过滤筛选说明处输入“http”,分组列表子窗口中将只显示所俘获到的HTTP报文。
根据操作回答“四、实验报告内容”中的7-10题。
4、获取长文件
(1)启动浏览器,将浏览器的缓存清空。
(2)启动Wireshark 分组俘获器,开始Wireshark分组俘获。
(3)在浏览器地址栏中输入如下网址:
http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file3.html
浏览器将显示一个相当大的美国权力法案
(4)停止Wireshark分组俘获,在显示过滤筛选说明处输入“http”,分组列表子窗口中将只显示所俘获到的HTTP报文。
根据操作回答“四、实验报告内容”中的11-14题。
5、嵌有对象的HTML文档
(1)启动浏览器,将浏览器的缓存清空。
(2)启动Wireshark分组俘获器。开始Wireshark分组俘获。
(3)在浏览器地址栏中输入如下网址:
http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file4.html
浏览器将显示一个具有两个图片的短HTTP文件。
(4)停止Wireshark分组俘获,在显示过滤筛选说明处输入“http”,分组列表子窗口中将只显示所俘获到的HTTP报文。
根据操作回答“四、实验报告内容”中的15-16题。
6、HTTP认证
(1)启动浏览器,将浏览器的缓存清空。
(2)启动Wireshark分组俘获器。开始Wireshark分组俘获。
(3)在浏览器地址栏中输入如下网址:
http://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wireshark-file5.html
浏览器将显示一个HTTP文件,输入所需要的用户名和密码(用户名:wireshark-students,密码:network)。
(4)停止Wireshark分组俘获,在显示过滤筛选说明处输入“http”,分组列表子窗口中将只显示所俘获到的HTTP报文。
根据操作回答“四、问题与思考”中的17-18题。
四、问题与思考
在实验的基础上,回答以下问题:
(1)你的浏览器运行的是HTTP1.0,还是HTTP1.1?你所访问的服务器所运行的HTTP版本号是多少?
(2)你的浏览器向服务器指出它能接收何种语言版本的对象?
(3)你的计算机的IP地址是多少?服务器gaia.cs.umass.edu的IP地址是多少?
(4)从服务器向你的浏览器返回的状态代码是多少?
(5)你从服务器上所获取的HTML文件的最后修改时间是多少?
(6)返回到你的浏览器的内容以供多少字节?
(7)分析你的浏览器向服务器发出的第一个HTTP GET请求的内容,在该请求报文中,是否有一行是:IF-MODIFIED-SINCE?
(8)分析服务器响应报文的内容,服务器是否明确返回了文件的内容?如何获知?
(9)分析你的浏览器向服务器发出的第二个“HTTP GET”请求,在该请求报文中是否有一行是:IF-MODIFIED-SINCE?如果有,在该首部行后面跟着的信息是什么?
(10)服务器对第二个HTTP GET请求的响应中的HTTP状态代码是多少?服务器是否明确返回了文件的内容?请解释。
(11)你的浏览器一共发出了多少个HTTP GET请求?
(12)承载这一个HTTP响应报文一共需要多少个data-containing TCP报文段?
(13)与这个HTTP GET请求相对应的响应报文的状态代码和状态短语是什么?
(14)在被传送的数据中一共有多少个HTTP状态行与TCP-induced”continuation”有关?
(15)你的浏览器一共发出了多少个HTTP GET请求?这些请求被发送到的目的地的IP地址是多少?
(16)浏览器在下载这两个图片时,是串行下载还是并行下载?请解释。
(17)对于浏览器发出的最初的HTTP GET请求,服务器的响应是什么(状态代码和状态短语)?
(18)当浏览器发出第二个HTTP GET请求时,在HTTP GET报文中包含了哪些新的字段?
实验八 利用Wireshark分析DNS协议
一、实验目的
分析DNS协议
二、实验环境
与因特网连接的计算机,操作系统为Windows,安装有Wireshark、IE等软件。
三、实验步骤
nslookup工具允许运行该工具的主机向指定的DNS服务器查询某个DNS记录。如果没有指明DNS服务器,nslookup将把查询请求发向默认的DNS服务器。其命令的一般格式是:
nslookup –option1 –option2 host-to-find dns-server
1、打开命令提示符(Command Prompt),输入nslookup命令。
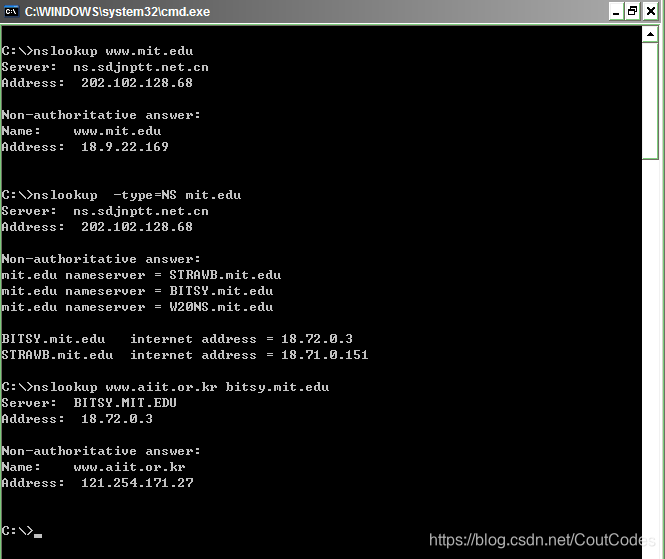
图中显示三条命令,第一条命令:nslookup www.mit.edu “提出一个问题”
即:“将主机www.mit.edu 的IP地址告诉我”。屏幕上出现了两条信息:(1)“回答这一问题”DNS服务器的名字和IP地址;(2)www.mit.edu 主机名字和IP地址。
第二条命令:nslookup –type=NS mit.edu
在这个例子中,我们提供了选项“-type=NS”,域为mit.edu。执行这条命令后,屏幕上显示了DNS服务器的名字和地址。接着下面是三个MIT DNS服务器,
每一个服务器是MIT校园里权威的DNS服务器。
第三条命令:nslookup www.aiit.or.kr bitsy.mit.edu
在这个例子中,我们请求返回bitsy.mit.edu DNS server 而不是默认的DNS服务器(uzzdns.edu.cn)。此例中,DNS 服务器bitsy.mit.edu提供主机www.aiit.or.kr 的
IP地址。
2、ipconfig
ipconfig用来显示TCP/IP 信息, 你的主机地址、DNS服务器地址,适配器等信息。如果你想看到所有关于你所在主机的信息,可在命令行键入:
ipconfig /all
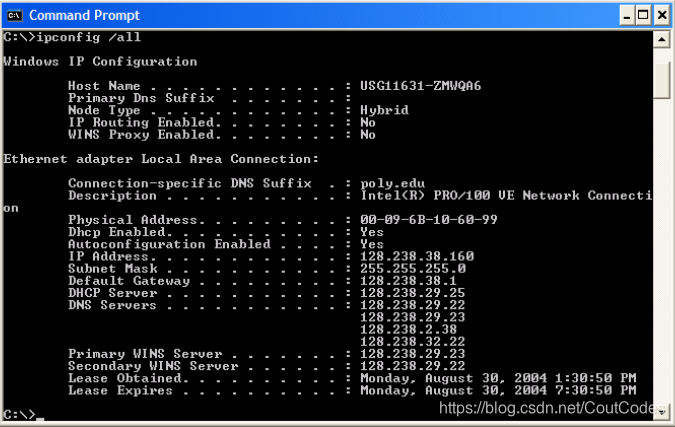
ipconfig在管理主机所储存的DNS信息非常有用。
如果查看DNS缓存中的记录用命令:ipconfig /displaydns
要清空DNS缓存,用命令:ipconfig /flushdns
3、利用Wireshark捕获DNS信息
(1)利用ipconfig命令清空你的主机上的DNS缓存。
(2)启动浏览器,将浏览器的缓存清空。
(3)启动Wireshark分组俘获器,在显示过滤筛说明处输入
“ip.addryour_IP_address”(如:ip.addr202.202.210.104),过滤器(filter)将会删除所有目的地址和源地址都与指定IP地址不同的分组。
(4)开始Wireshark俘获。
(5)在浏览器的地址栏中输入:http://www.ietf.org
(6)停止分组俘获。
(7)重复上面的实验,只是将命令替换为:nslookup –type=NS mit.edu
(8)重复上面的实验,只是将命令替换为:
nslookup www.aiit.or.kr bitsy.mit.edu
四、问题与思考
在实验的基础上,回答以下问题:
(1)你的浏览器运行的是HTTP1.0,还是HTTP1.1?你所访问的服务器所运行的HTTP版本号是多少?
(2)你的浏览器向服务器指出它能接收何种语言版本的对象?
(3)你的计算机的IP地址是多少?服务器gaia.cs.umass.edu的IP地址是多少?
(4)从服务器向你的浏览器返回的状态代码是多少?
(5)你从服务器上所获取的HTML文件的最后修改时间是多少?
(6)返回到你的浏览器的内容以供多少字节?
(7)分析服务器响应报文的内容,服务器是否明确返回了文件的内容?如何获知?
(8)服务器对第二个HTTP GET请求的响应中的HTTP状态代码是多少?服务器是否明确返回了文件的内容?请解释。
(9)与这个HTTP GET请求相对应的响应报文的状态代码和状态短语是什么?
(10)你的浏览器一共发出了多少个HTTP GET请求?这些请求被发送到的目的地的IP地址是多少?
(11)对于浏览器发出的最初的HTTP GET请求,服务器的响应是什么(状态代码和状态短语)?
(12)当浏览器发出第二个HTTP GET请求时,在HTTP GET报文中包含了哪些新的字段?
(13)DNS查询报文的目的端口号是多少?DNS查询响应报文的源端口号是多少?
如有不足之处,还望指正 [1]。
如果对您有帮助可以点赞、收藏、关注,将会是我最大的动力 ↩︎