numpy 时目前python数值计算中最为重要的基础包。大多数计算包都提供了基于numpy的科学函数功能,将numpy的数组对象作为数据交换的通用语。
由于numpy 提供了一个非常易用的c 语言的API,这使得将数据传递给用底层语言编写的外部类库,再由外部类库将计算结果按照numpy数组的方式返回变得十分简单。这个特征使得python可以对存量C/C++/Frotran代码库进行封装,并为这些代码提供动态,易用的接口。
对于⼤部分数据分析应⽤⽽⾔,我最关注的功能主要集中在:
1.⽤于数据整理和清理、⼦集构造和过滤、转换等快速的⽮量化数组运算。
2.常⽤的数组算法,如排序、唯⼀化、集合运算等。
3.⾼效的描述统计和数据聚合/摘要运算。
4.⽤于异构数据集的合并/连接运算的数据对⻬和关系型数据运算。
5.使用数组表达式来表明条件逻辑,代替if-else条件分支的循环
6.分组数据的操作(聚合,变换以及函数式操作)
numpy 本身并不提供建模和科学函数,理解numpy 的数组以及基于数组的计算将帮助你更高效的使用基于数组的工具,比如pandas。
NumPy ndarray: 多维数组对象
numpy 的核心特征之一就是N- 维数组对象————ndarray。这是一个快速灵活的大型数据集容器。数组允许你使用类似于标量的操作语法再整块数据上进行数学计算。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
from numpy as np
data = np.random.randn(2,3) # 生成一个随机数组
data
>>>array([[ 0.52392054, -0.0217759 , -0.63695291],
[ 0.83896611, -0.2642878 , -0.19434032]])
data +data
data *10 # 进行一些数学操作
一个ndarray是一个通用的多维同类数据容器,也就说,它包含的每一个元素均为相同类型。每一个数组都有一个 shape 属性,用来表征每一维度的数量,每个数组都有一个 dtype 属性,用来描述数组的数据类型。
print(data.shape)
print(data.dtype)
print(data.itemsize) # 每个元素的大小(字节)
(2, 3)
float64
虽然深入理解numpy 对大部分数据分析应用时不用的,但是精通于数组的编程和思考是称为python 科学计算专家的重要一步。。。
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。 (来自菜鸟教程)。。。。
生成ndarray
生成数组最简单的方式就是 array函数。array 函数接受任意的序列型对象(当然也包括其他的数组),生成一个新的包含传递数据的numpy 数组。例如列表的转换:
data1=[6,7.5,8,2,3,4]
arr1 = np.array(data1)
print(type(arr1))
print(arr1)
<class 'numpy.ndarray'>
[6. 7.5 8. 2. 3. 4. ]
data1=[[1,2,3,4],[5,6,7,8]] # 嵌套数据,自动转换成多维数组
arr1 = np.array(data1)
print(arr1)
print(arr1.ndim,arr1.shape,arr1.dtype)
# 除非指定,否则会自动推断生成的数据类型,数据类型存储再一个特殊的元数据dtype 中。
[[1 2 3 4]
[5 6 7 8]]
2 (2, 4) int32
np.linspace(0,10,7) # 生成首位是0,末位是10,含7个数的等差数列
[ 0. 1.66666667 3.33333333 5. 6.66666667 8.33333333 10. ]
np.random.random((2,3)) # 产生2行,3列的随机矩阵
| 函数名 | 描述 如果没有指定默认的数据类型是 float64 |
|---|---|
| array | 将输入数据(可以是列表,元组,数组以及其他序列 转换为ndaray ,如果不指定数据类型,将自动推断。默认复制所有的输入数据 |
| asarray | 将输入的转为ndarray ,但如果输入已经是ndarray 则不再赋值。任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组 |
| arange | python内建函数range的数组版,返回一个数组 |
| ones | 根据给定的形状和数据类型生成全1 的数组 |
| ones_like | 根据给的数组生成一个形状一样的全1 数组 |
| zeros | 这个式生成全为0的 |
| zeros_like | 同上 |
| empty | 根据给定的形状生成一个没有初始化数值的空数组 |
| empty_like | 同上 |
| full | 根据给定的形状和数据类型来生成指定数值的数组 |
| full_like | 根据所给的数组生成一个形状一样但是内容是指定数值的数值 |
| eye,idnetity | 生成一个 N X N特征举证(对角位置都是1,其余位置是0) |
额。。。。学的线代都忘了,,,哎,,,,,,
np.empty((2,3,2) # 有时候使用这个来生成全零数值是不安全的,会生成未初始化的垃圾数值。
array([[[1.04756670e-311, 2.47032823e-322],
[0.00000000e+000, 0.00000000e+000],
[2.14321575e-312, 3.69776220e-062]],
[[5.33839006e-091, 2.74072578e-057],
[9.98973678e-048, 1.63271300e+185],
[3.99910963e+252, 1.46030983e-319]]])
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
- num 要生成的等步长的样本数量,默认为50
- endpoint 该值为 true 时,数列中包含stop值,反之不包含,默认是True。
- retstep 如果为 True 时,生成的数组中会显示间距,反之不显示。
numpy.logspace 函数用于创建一个于等比数列。格式如下:np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
- base 对数 log 的底数。
- start 序列的起始值为:base ** start
- stop 序列的终止值为:base ** stop。如果endpoint为true,该值包含于数列中
不管用不用的上,,,,见过在说。。。。。
ndarray的数据类型
数据类型,即 dtype 是一个特殊的对象,包含了ndarray需要为某一种类型数据所申明的内存块信息(也成为元数据,即表示数据的数据)
arr1 = np.array([1,2,3],dtype=np.int32)
dtype 是能够与其他系统数据灵活交换的原因。类型名: float,int,complex等,后面接上表示每个元素位数的数字。一个标准的双精度浮点值(python中的float)使用8或64位。因此这个类型就叫 float64
- 还是萌新的时候,只要关心数据的大类就行,当你需要再内存或硬盘上做更深入的存取操作的时候,尤其使大数据的时候,你才真正需要了解存储的数据类型。
| 类型 | 类型代码 | 描述 |
|---|---|---|
| int8,uint8 | i1,u1 | 有符号和无符号的8数位整数 |
| int16,uint16 | i2,u2 | 有符号和无符号的16数位整数 |
| int32,uint32 | i4,u4 | 32数位整数 |
| int64,uint64 | i8,u8 | 64数位整数 |
| float16 | f2 | 半精度浮点数 |
| float32 | f或f4 | 标准单精度浮点数,兼容C语言的float |
| float64 | f8 或 d | 标准双精度浮点数,兼容double |
| float128 | f16 或 g | 扩展精度浮点数 |
| complex64,128,256 | c8,c16,c32 | 分别基于32,64,128位浮点数的复数 |
| bool | ? | 布尔值,存储true flase |
| object | O | python object 类型 |
| string_ | S | 修正的ASC II字符串类型,例如生成一个长度为10的字符串类型: S10 |
| unicode_ | U | 修正的Unicode类型,U10 |
你可以使用 astype 方法显式的转换属猪的数据类型:
arr = np.array([1,2,3,4,5])
float_arr = arr.astype(np.float64)
如果我们把浮点数转换成整数,那么小数点后面的就会消失。如果你的数组式表达数字含义的字符串,也可以通过这个给方法来转换。
再 numpy中 使用numpy.string_ 类型作字符串数据要小心,因为会修正它的大小或删除输入且不发送警告。pandas再处理非数值数据式有更直观的开箱操作
int_array = np.arange(10)
float_array=np.arange(5,dtype=float) # numpy可以使用于python数据类型相同的别名,即float64,也可以是类型代码f8
int_array.astype(float_array.dtype)
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.]) # astype 总是生成一个新的数组
NumPy 数组计算
数组之所以重要就是因为它允许你进行批量操作而无需任何for循环。称这种特性为向量化。任何两个等尺寸数组之间的算数操作都应用了逐元素操作的方式:
arr = np.array([[1,2,3],[4,5,6]])
print(arr*arr)
print(1/arr) # 带有标量计算的算数操作,会把计算参数传递给数组的每一个元素。
[[ 1 4 9]
[16 25 36]]
[[1. 0.5 0.33333333]
[0.25 0.2 0.16666667]]
arr2 = np.array([[3,4,1],[9,8,5]]) # 同尺寸数组之间的比较,会产生一个布尔值数组
arr2>arr
array([[ True, True, False],
[ True, True, False]])
# 不同尺寸的数组操作,会用到广播特性。。。大部分是不用深入理解广播特性的
基础索引与切片
数组索引是一个大话题,有很多种方式可以让你选中的数据的子集或某个单个元素。一位数组比较简单,看起来和python的列表差不多
arr=np.arange(10)
arr[5] >>> 5
arr[5:8] >>>array([5,6,7])
arr[5:8]=12
array([0,1,2,3,4,12,12,12,8,9])
区别于python的列表,数组的切片就是原数组的视图,就是说,任何对于视图的修改都会反映到原数组上
arr=np.arange(10)
arr_slice=arr[5:8]
arr_slice[1]=12345 # 这里修改arr_slice也会改变原数组
arr
array([ 0, 1, 2, 3, 4, 5, 12345, 7, 8,
9])
如果你希望得到数据切片的拷贝而不是一个视图,要显示的复制这个数组,arr[5:8].copy()
对于更高维的数据,会有更多的选择,在一个二维数组中,每个索引值对应的元素不再是一个值,而是一个i一位数组。
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(arr2d[2])
print(arr2d[2][2])
print(arr2d[2,2]) # 这两种方式是相同的
[7 8 9]
9
9
再多维数组中,你可以省略后续索引值,返回的对象将是一个降低一个维度的数组,因此在一个 223 的数组中:
arr3d=np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(arr3d)
print(arr3d[0]) # 一个2*3 的数组
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]]
[[1 2 3]
[4 5 6]]
old_values = arr3d[0].copy()
arr3d[0] =42 # 标量和数组都可以传递给arr3d[0]
print(arr3d)
arr3d[0]=old_values
print(arr3d)
[[[42 42 42]
[42 42 42]]
[[ 7 8 9]
[10 11 12]]]
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]]
arr3d[1,0] # 返回一个一位数组
需要注意的是以上数组子集选择中,返回的数组都是视图
数组的切片索引
与python列表的一维对象类似,数组可以通过类似的语法进行切片。
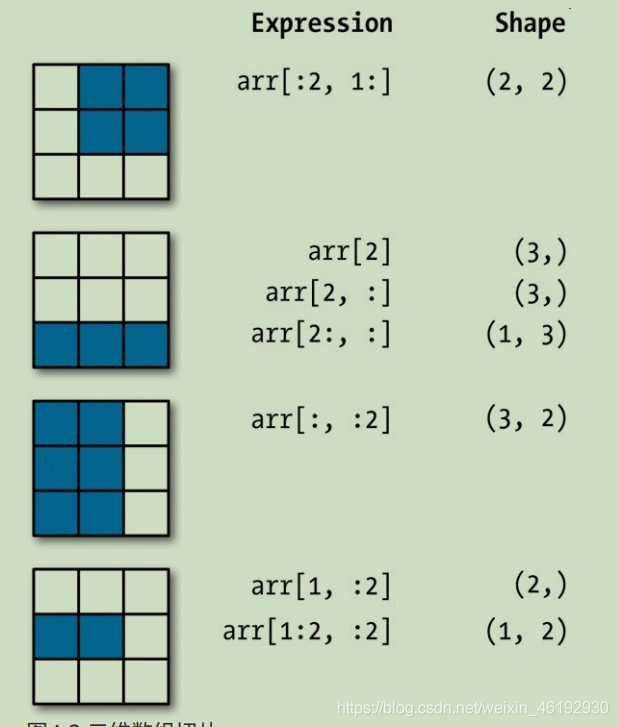
对于二维数组,切片是略有不同:
arr2d[:2] # 选择arr2d的前两行
array([[1, 2, 3],
[4, 5, 6]])
arr2d[:2,1:] # 多组切片
array([[2, 3],
[5, 6]])
arr2d[1,1:] # 索引和切片相结合
array([5, 6])
arr2d[:2,2]
array([3, 6])
arr2d[:,:2] =0 # 单独一个冒号,表示第一层所有数组
print(arr2d)
array([[0, 0, 3],
[0, 0, 6],
[0, 0, 9]])