文章目录
1.什么是数据库索引?
1.1概念
- 索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
1.2作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 如果没有索引,在数据库中进行查找就要把整个表遍历一遍,很耗时.
- 索引对于提高数据库的性能 (主要是提高查找效率,修改增加删除效率还会有所下降) 有很大的帮助。
- 本质上索引就是为了避免数据库进行顺序查找,提高查找效率.
1.3使用场景
- 要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。(用空间效率换取时间效率)
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
1.4如何使用
- 创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
- 查看索引
mysql> show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 1 | NULL | NULL | | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
- 创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
mysql> show index from student;
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 1 | NULL | NULL | | BTREE | | |
| student | 1 | idx_student_name | 1 | name | A | 1 | NULL | NULL | YES | BTREE | | |
+---------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
- 删除索引
如果是主键、唯一约束、外键索引不可删除
mysql> drop index idx_student_name on student;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 1 | NULL | NULL | | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
2.索引的数据结构是什么?
2.1可以是二叉搜索树或者红黑树吗?
- 不可以
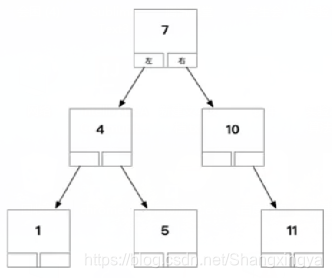
- 二叉搜索树的平均查找效率是O(logN)
- 如果数据很多的话,二叉搜索树最多俩个分支,所以树的深度会很大,查找效率其实不高
- 如果是查找范围的时候还需要对二叉搜索树进行中序遍历 (因为二叉搜索树中序遍历是有序序列) 又不是很高效O(N)
2.2可以是哈希表吗?
- 不可以
- 如果是处理相等情况,哈希表很高效
- 但是哈希表不可以处理其他逻辑,比如范围查找 > >= < <= between and
- 因为哈希的查找是把key带入哈希函数得到下标,再根据下标取对应的链表,再去遍历链表比较key是否相等,无法进行范围查找
2.3可以是B-树吗?
- 本质可以,但为了更高的效率不选它
- B-树与二叉树差异
- 为了结点不是2叉而是N叉
- 为了结点不是存储一个数据,而是可能存储多个数据
- 每个节点存储数据的个数和该节点的度是有关系的 度=存储数据的个数+1
- 此时在B-树上查找就是一个N分查找,效率比二叉树还高
- 由于每个及节点存储了多个数据,每个节点又有多个度,所以和二叉树相比,B-树的高度会低很多,查找起来效率一会高一下.而且简单的范围查找会容易一些.
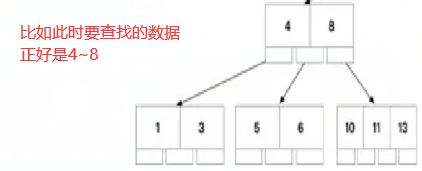
- 因为其叶子 非叶子 都是存储数据都要放在磁盘上,所以遇到较复杂的范围查找,需要读取磁盘的次数还是较高,所以效率还不是很好
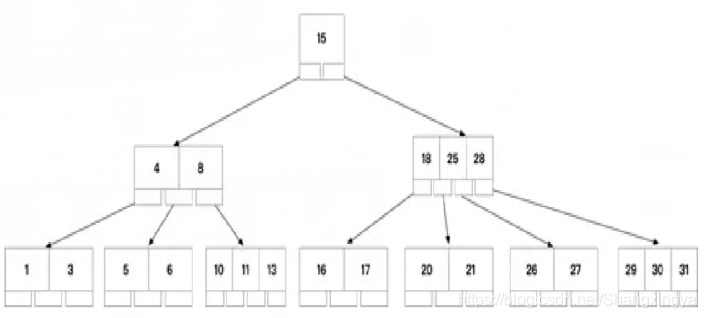
2.4可以是B+树吗?
- 真实的索引结构
- 与B-树相比的差异
- 每一层的元素之间都链接在一起
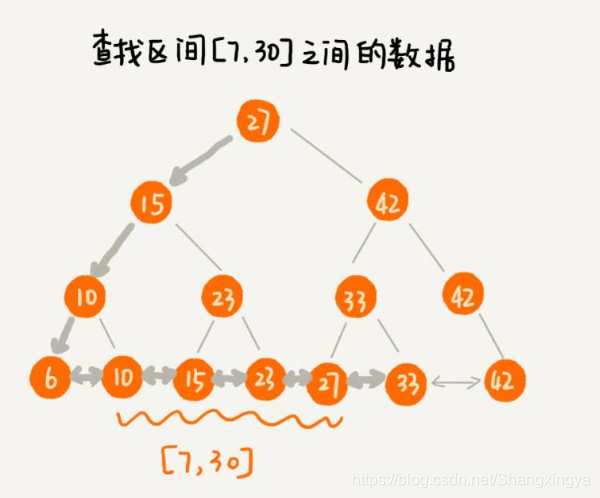
- 数据(表的一行记录)只存在叶子节点上,非叶子节点只保存一些辅助查找的边界信息
- 查询任一条记录都比较平均,不会出现效率差异很大的情况
- 不需要额外进行中序遍历,遍历叶子节点就是中序结果,所以处理范围查找很高效
- 叶子放在磁盘上,非叶子放在内存中,减少了访问磁盘的次数,查找也就更高效了,而且索引在内存中实际开销有不高
- 索引引起的效果就是加快查找效率, 减慢插入删除修改的效率 (因为需要同步调整索引结果)
- 索引也会占用额外空间(本质上使用空间换取时间)
- 给具体表中某列加索引的时候,加在主键的索引和加在其他列的索引是截然不同的.
- 主键索引的叶子结点value存的是表的一行完整数据, 其他索引的叶子节点value只存的是主键的信息(如id)
2.5explain查看SQL的执行
- 帮助我们分析SQL的执行过程,能够看到是否使用索引,以及使用了哪个索引
- key等于null表示没用到索引,否则会显示用到哪个索引
mysql> explain select * from student where id = 1;
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
3.什么是事务?
3.1概念
- 事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
- 在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
3.2如何使用
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)回滚或提交:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功
3.2.1 commit全部成功

mysql> select * from student;
+----+-----------+---------+
| id | name | classId |
+----+-----------+---------+
| 1 | 张翼德 | 10 |
| 2 | 刘备 | 10 |
+----+-----------+---------+
2 rows in set (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> update student set classId = classId + 1 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update student set classId = classId - 1 where id = 2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from student;
+----+-----------+---------+
| id | name | classId |
+----+-----------+---------+
| 1 | 张翼德 | 11 |
| 2 | 刘备 | 9 |
+----+-----------+---------+
2 rows in set (0.00 sec)
3.2.2rollback全部失败

mysql> select * from student;
+----+-----------+---------+
| id | name | classId |
+----+-----------+---------+
| 1 | 张翼德 | 12 |
| 2 | 刘备 | 8 |
+----+-----------+---------+
2 rows in set (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> update student set classId = classId + 1 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update student set classId = classId - 1 where id = 2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> rollback;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from student;
+----+-----------+---------+
| id | name | classId |
+----+-----------+---------+
| 1 | 张翼德 | 12 |
| 2 | 刘备 | 8 |
+----+-----------+---------+
2 rows in set (0.00 sec)
3.3事务的特点
- 原子性(最重要): 事务中的若干个操作,要么全部执行成功,要么全部不执行(本质上不是全部不执行,那是把已执行的步骤回滚(rollback)回去,借助逆向操作,把原来操作造成的影响进行还原)
- 一致性: 执行事务前后,数据库始终处于一种合法的状态
- 持久性: 事务一旦执行完毕, 此时对于数据库的修改是持久生效的
- 隔离性:较复杂难点,后面解释.
MySQL~详细介绍事务的一个重要特性–隔离性 (解决脏读、不可重复读、幻读)