DL之RetinaNet:基于RetinaNet算法(keras框架)训练自己的数据集(.h5文件)从而实现目标检测daiding
目录
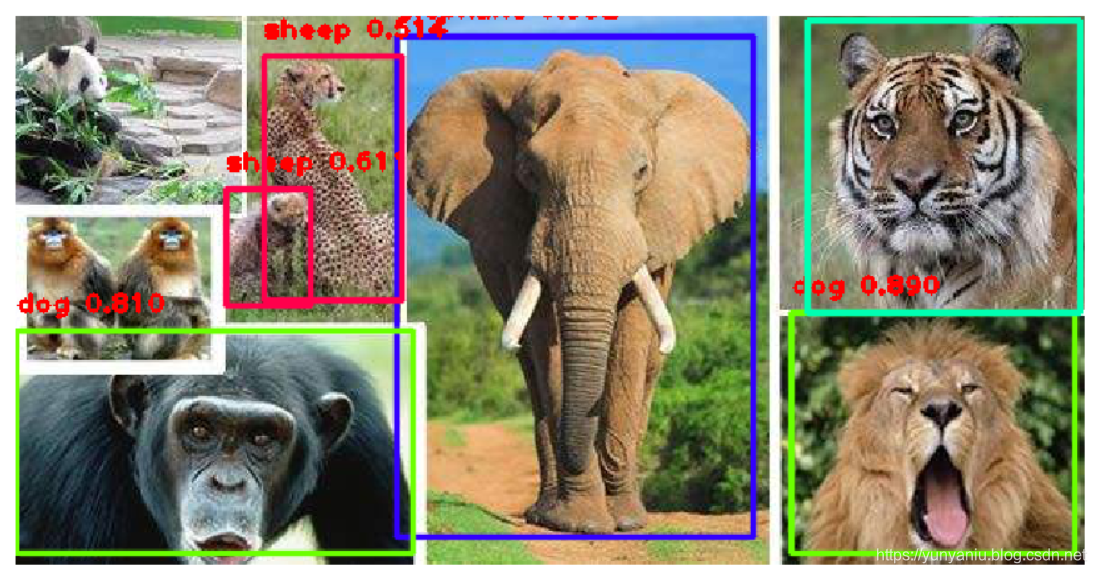
输出结果


设计思路
更新……
训练代码
#!/usr/bin/env python
"""
Copyright 2017-2018 Fizyr (https://fizyr.com)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
核心代码源自:http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
import argparse
import os
import sys
import warnings
import keras
import keras.preprocessing.image
import tensorflow as tf
# Allow relative imports when being executed as script.
if __name__ == "__main__" and __package__ is None:
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
import keras_retinanet.bin # noqa: F401
__package__ = "keras_retinanet.bin"
# Change these to absolute imports if you copy this script outside the keras_retinanet package.
from .. import layers # noqa: F401
from .. import losses
from .. import models
from ..callbacks import RedirectModel
from ..callbacks.eval import Evaluate
from ..models.retinanet import retinanet_bbox
from ..preprocessing.csv_generator import CSVGenerator
from ..preprocessing.kitti import KittiGenerator
from ..preprocessing.open_images import OpenImagesGenerator
from ..preprocessing.pascal_voc import PascalVocGenerator
from ..utils.anchors import make_shapes_callback
from ..utils.config import read_config_file, parse_anchor_parameters
from ..utils.keras_version import check_keras_version
from ..utils.model import freeze as freeze_model
from ..utils.transform import random_transform_generator
def makedirs(path):
# Intended behavior: try to create the directory,
# pass if the directory exists already, fails otherwise.
# Meant for Python 2.7/3.n compatibility.
try:
os.makedirs(path)
except OSError:
if not os.path.isdir(path):
raise
def get_session():
""" Construct a modified tf session.
"""
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
return tf.Session(config=config)
def model_with_weights(model, weights, skip_mismatch):
""" Load weights for model.
Args
model : The model to load weights for.
weights : The weights to load.
skip_mismatch : If True, skips layers whose shape of weights doesn't match with the model.
"""
if weights is not None:
model.load_weights(weights, by_name=True, skip_mismatch=skip_mismatch)
return model
def create_models(backbone_retinanet, num_classes, weights, multi_gpu=0,
freeze_backbone=False, lr=1e-5, config=None):
""" Creates three models (model, training_model, prediction_model).
Args
backbone_retinanet : A function to call to create a retinanet model with a given backbone.
num_classes : The number of classes to train.
weights : The weights to load into the model.
multi_gpu : The number of GPUs to use for training.
freeze_backbone : If True, disables learning for the backbone.
config : Config parameters, None indicates the default configuration.
Returns
model : The base model. This is also the model that is saved in snapshots.
training_model : The training model. If multi_gpu=0, this is identical to model.
prediction_model : The model wrapped with utility functions to perform object detection (applies regression values and performs NMS).
"""
modifier = freeze_model if freeze_backbone else None
# load anchor parameters, or pass None (so that defaults will be used)
anchor_params = None
num_anchors = None
if config and 'anchor_parameters' in config:
anchor_params = parse_anchor_parameters(config)
num_anchors = anchor_params.num_anchors()
# Keras recommends initialising a multi-gpu model on the CPU to ease weight sharing, and to prevent OOM errors.
# optionally wrap in a parallel model
if multi_gpu > 1:
from keras.utils import multi_gpu_model
with tf.device('/cpu:0'):
model = model_with_weights(backbone_retinanet(num_classes, num_anchors=num_anchors, modifier=modifier), weights=weights, skip_mismatch=True)
training_model = multi_gpu_model(model, gpus=multi_gpu)
else:
model = model_with_weights(backbone_retinanet(num_classes, num_anchors=num_anchors, modifier=modifier), weights=weights, skip_mismatch=True)
training_model = model
# make prediction model
prediction_model = retinanet_bbox(model=model, anchor_params=anchor_params)
# compile model
training_model.compile(
loss={
'regression' : losses.smooth_l1(),
'classification': losses.focal()
},
optimizer=keras.optimizers.adam(lr=lr, clipnorm=0.001)
)
return model, training_model, prediction_model
def create_callbacks(model, training_model, prediction_model, validation_generator, args):
""" Creates the callbacks to use during training.
Args
model: The base model.
training_model: The model that is used for training.
prediction_model: The model that should be used for validation.
validation_generator: The generator for creating validation data.
args: parseargs args object.
Returns:
A list of callbacks used for training.
"""
callbacks = []
tensorboard_callback = None
if args.tensorboard_dir:
tensorboard_callback = keras.callbacks.TensorBoard(
log_dir = args.tensorboard_dir,
histogram_freq = 0,
batch_size = args.batch_size,
write_graph = True,
write_grads = False,
write_images = False,
embeddings_freq = 0,
embeddings_layer_names = None,
embeddings_metadata = None
)
callbacks.append(tensorboard_callback)
if args.evaluation and validation_generator:
if args.dataset_type == 'coco':
from ..callbacks.coco import CocoEval
# use prediction model for evaluation
evaluation = CocoEval(validation_generator, tensorboard=tensorboard_callback)
else:
evaluation = Evaluate(validation_generator, tensorboard=tensorboard_callback, weighted_average=args.weighted_average)
evaluation = RedirectModel(evaluation, prediction_model)
callbacks.append(evaluation)
# save the model
if args.snapshots:
# ensure directory created first; otherwise h5py will error after epoch.
makedirs(args.snapshot_path)
checkpoint = keras.callbacks.ModelCheckpoint(
os.path.join(
args.snapshot_path,
'{backbone}_{dataset_type}_{{epoch:02d}}.h5'.format(backbone=args.backbone, dataset_type=args.dataset_type)
),
verbose=1,
# save_best_only=True,
# monitor="mAP",
# mode='max'
)
checkpoint = RedirectModel(checkpoint, model)
callbacks.append(checkpoint)
callbacks.append(keras.callbacks.ReduceLROnPlateau(
monitor = 'loss',
factor = 0.1,
patience = 2,
verbose = 1,
mode = 'auto',
min_delta = 0.0001,
cooldown = 0,
min_lr = 0
))
return callbacks
def create_generators(args, preprocess_image):
""" Create generators for training and validation.
Args
args : parseargs object containing configuration for generators.
preprocess_image : Function that preprocesses an image for the network.
"""
common_args = {
'batch_size' : args.batch_size,
'config' : args.config,
'image_min_side' : args.image_min_side,
'image_max_side' : args.image_max_side,
'preprocess_image' : preprocess_image,
}
# create random transform generator for augmenting training data
if args.random_transform:
transform_generator = random_transform_generator(
min_rotation=-0.1,
max_rotation=0.1,
min_translation=(-0.1, -0.1),
max_translation=(0.1, 0.1),
min_shear=-0.1,
max_shear=0.1,
min_scaling=(0.9, 0.9),
max_scaling=(1.1, 1.1),
flip_x_chance=0.5,
flip_y_chance=0.5,
)
else:
transform_generator = random_transform_generator(flip_x_chance=0.5)
if args.dataset_type == 'coco':
# import here to prevent unnecessary dependency on cocoapi
from ..preprocessing.coco import CocoGenerator
train_generator = CocoGenerator(
args.coco_path,
'train2017',
transform_generator=transform_generator,
**common_args
)
validation_generator = CocoGenerator(
args.coco_path,
'val2017',
**common_args
)
elif args.dataset_type == 'pascal':
train_generator = PascalVocGenerator(
args.pascal_path,
'trainval',
transform_generator=transform_generator,
**common_args
)
validation_generator = PascalVocGenerator(
args.pascal_path,
'test',
**common_args
)
elif args.dataset_type == 'csv':
train_generator = CSVGenerator(
args.annotations,
args.classes,
transform_generator=transform_generator,
**common_args
)
if args.val_annotations:
validation_generator = CSVGenerator(
args.val_annotations,
args.classes,
**common_args
)
else:
validation_generator = None
elif args.dataset_type == 'oid':
train_generator = OpenImagesGenerator(
args.main_dir,
subset='train',
version=args.version,
labels_filter=args.labels_filter,
annotation_cache_dir=args.annotation_cache_dir,
parent_label=args.parent_label,
transform_generator=transform_generator,
**common_args
)
validation_generator = OpenImagesGenerator(
args.main_dir,
subset='validation',
version=args.version,
labels_filter=args.labels_filter,
annotation_cache_dir=args.annotation_cache_dir,
parent_label=args.parent_label,
**common_args
)
elif args.dataset_type == 'kitti':
train_generator = KittiGenerator(
args.kitti_path,
subset='train',
transform_generator=transform_generator,
**common_args
)
validation_generator = KittiGenerator(
args.kitti_path,
subset='val',
**common_args
)
else:
raise ValueError('Invalid data type received: {}'.format(args.dataset_type))
return train_generator, validation_generator
def check_args(parsed_args):
""" Function to check for inherent contradictions within parsed arguments.
For example, batch_size < num_gpus
Intended to raise errors prior to backend initialisation.
Args
parsed_args: parser.parse_args()
Returns
parsed_args
"""
if parsed_args.multi_gpu > 1 and parsed_args.batch_size < parsed_args.multi_gpu:
raise ValueError(
"Batch size ({}) must be equal to or higher than the number of GPUs ({})".format(parsed_args.batch_size,
parsed_args.multi_gpu))
if parsed_args.multi_gpu > 1 and parsed_args.snapshot:
raise ValueError(
"Multi GPU training ({}) and resuming from snapshots ({}) is not supported.".format(parsed_args.multi_gpu,
parsed_args.snapshot))
if parsed_args.multi_gpu > 1 and not parsed_args.multi_gpu_force:
raise ValueError("Multi-GPU support is experimental, use at own risk! Run with --multi-gpu-force if you wish to continue.")
if 'resnet' not in parsed_args.backbone:
warnings.warn('Using experimental backbone {}. Only resnet50 has been properly tested.'.format(parsed_args.backbone))
return parsed_args
def parse_args(args):
""" Parse the arguments.
"""
parser = argparse.ArgumentParser(description='Simple training script for training a RetinaNet network.')
subparsers = parser.add_subparsers(help='Arguments for specific dataset types.', dest='dataset_type')
subparsers.required = True
coco_parser = subparsers.add_parser('coco')
coco_parser.add_argument('coco_path', help='Path to dataset directory (ie. /tmp/COCO).')
pascal_parser = subparsers.add_parser('pascal')
pascal_parser.add_argument('pascal_path', help='Path to dataset directory (ie. /tmp/VOCdevkit).')
kitti_parser = subparsers.add_parser('kitti')
kitti_parser.add_argument('kitti_path', help='Path to dataset directory (ie. /tmp/kitti).')
def csv_list(string):
return string.split(',')
oid_parser = subparsers.add_parser('oid')
oid_parser.add_argument('main_dir', help='Path to dataset directory.')
oid_parser.add_argument('--version', help='The current dataset version is v4.', default='v4')
oid_parser.add_argument('--labels-filter', help='A list of labels to filter.', type=csv_list, default=None)
oid_parser.add_argument('--annotation-cache-dir', help='Path to store annotation cache.', default='.')
oid_parser.add_argument('--parent-label', help='Use the hierarchy children of this label.', default=None)
csv_parser = subparsers.add_parser('csv')
csv_parser.add_argument('annotations', help='Path to CSV file containing annotations for training.')
csv_parser.add_argument('classes', help='Path to a CSV file containing class label mapping.')
csv_parser.add_argument('--val-annotations', help='Path to CSV file containing annotations for validation (optional).')
group = parser.add_mutually_exclusive_group()
group.add_argument('--snapshot', help='Resume training from a snapshot.')
group.add_argument('--imagenet-weights', help='Initialize the model with pretrained imagenet weights. This is the default behaviour.', action='store_const', const=True, default=True)
group.add_argument('--weights', help='Initialize the model with weights from a file.')
group.add_argument('--no-weights', help='Don\'t initialize the model with any weights.', dest='imagenet_weights', action='store_const', const=False)
parser.add_argument('--backbone', help='Backbone model used by retinanet.', default='resnet50', type=str)
parser.add_argument('--batch-size', help='Size of the batches.', default=1, type=int)
parser.add_argument('--gpu', help='Id of the GPU to use (as reported by nvidia-smi).')
parser.add_argument('--multi-gpu', help='Number of GPUs to use for parallel processing.', type=int, default=0)
parser.add_argument('--multi-gpu-force', help='Extra flag needed to enable (experimental) multi-gpu support.', action='store_true')
parser.add_argument('--epochs', help='Number of epochs to train.', type=int, default=50)
parser.add_argument('--steps', help='Number of steps per epoch.', type=int, default=10000)
parser.add_argument('--lr', help='Learning rate.', type=float, default=1e-5)
parser.add_argument('--snapshot-path', help='Path to store snapshots of models during training (defaults to \'./snapshots\')', default='./snapshots')
parser.add_argument('--tensorboard-dir', help='Log directory for Tensorboard output', default='./logs')
parser.add_argument('--no-snapshots', help='Disable saving snapshots.', dest='snapshots', action='store_false')
parser.add_argument('--no-evaluation', help='Disable per epoch evaluation.', dest='evaluation', action='store_false')
parser.add_argument('--freeze-backbone', help='Freeze training of backbone layers.', action='store_true')
parser.add_argument('--random-transform', help='Randomly transform image and annotations.', action='store_true')
parser.add_argument('--image-min-side', help='Rescale the image so the smallest side is min_side.', type=int, default=800)
parser.add_argument('--image-max-side', help='Rescale the image if the largest side is larger than max_side.', type=int, default=1333)
parser.add_argument('--config', help='Path to a configuration parameters .ini file.')
parser.add_argument('--weighted-average', help='Compute the mAP using the weighted average of precisions among classes.', action='store_true')
# Fit generator arguments
parser.add_argument('--workers', help='Number of multiprocessing workers. To disable multiprocessing, set workers to 0', type=int, default=1)
parser.add_argument('--max-queue-size', help='Queue length for multiprocessing workers in fit generator.', type=int, default=10)
return check_args(parser.parse_args(args))
def main(args=None):
# parse arguments
if args is None:
args = sys.argv[1:]
args = parse_args(args)
# create object that stores backbone information
backbone = models.backbone(args.backbone)
# make sure keras is the minimum required version
check_keras_version()
# optionally choose specific GPU
if args.gpu:
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
keras.backend.tensorflow_backend.set_session(get_session())
# optionally load config parameters
if args.config:
args.config = read_config_file(args.config)
# create the generators
train_generator, validation_generator = create_generators(args, backbone.preprocess_image)
# create the model
if args.snapshot is not None:
print('Loading model, this may take a second...')
model = models.load_model(args.snapshot, backbone_name=args.backbone)
training_model = model
anchor_params = None
if args.config and 'anchor_parameters' in args.config:
anchor_params = parse_anchor_parameters(args.config)
prediction_model = retinanet_bbox(model=model, anchor_params=anchor_params)
else:
weights = args.weights
# default to imagenet if nothing else is specified
if weights is None and args.imagenet_weights:
weights = backbone.download_imagenet()
print('Creating model, this may take a second...')
model, training_model, prediction_model = create_models(
backbone_retinanet=backbone.retinanet,
num_classes=train_generator.num_classes(),
weights=weights,
multi_gpu=args.multi_gpu,
freeze_backbone=args.freeze_backbone,
lr=args.lr,
config=args.config
)
# print model summary
print(model.summary())
# this lets the generator compute backbone layer shapes using the actual backbone model
if 'vgg' in args.backbone or 'densenet' in args.backbone:
train_generator.compute_shapes = make_shapes_callback(model)
if validation_generator:
validation_generator.compute_shapes = train_generator.compute_shapes
# create the callbacks
callbacks = create_callbacks(
model,
training_model,
prediction_model,
validation_generator,
args,
)
# Use multiprocessing if workers > 0
if args.workers > 0:
use_multiprocessing = True
else:
use_multiprocessing = False
# start training
training_model.fit_generator(
generator=train_generator,
steps_per_epoch=args.steps,
epochs=args.epochs,
verbose=1,
callbacks=callbacks,
workers=args.workers,
use_multiprocessing=use_multiprocessing,
max_queue_size=args.max_queue_size
)
if __name__ == '__main__':
main()