deconvolution
起初是看FCN图像分割论文的时候,看到论文中用到deconvolution和up-sampling,不是特别理解up-samping和deconv之间的关系,也不知道deconv是以一种怎么样计算过程完成的。所以就去搜了相关资料,同时了解了空洞卷积-dilated conv的原理,在此博客记录一下。
deconv(反卷积、转置卷积)
deconv和up-sampling是FCN图像分割网络中用到的两个扩大feature map尺寸的重要操作。因为在FCN全卷积网络中,其要实现的是一个图像分割的任务,在网络的前半部分,其通过卷积和池化层实现对输入图像的特征提取,一步步将feature map降到很小,然后对其每一个像素进行分类,在网络的后半段,FCN又通过up-samping将网络层前半段不同阶段的feature map进行上采样和反卷积操作(虽然FCN提到了deconv,但是其并没有用到,而是直接使用的up-sampling中的双线性插值直接对feature扩大几倍以达到恢复输入尺寸的效果),以将feature map复原到输入图像的尺寸大小,以此输出针对每一个像素分类后的分割图像。
很多人都将deconv反卷积称作转置卷积,但是好像也有说它们两者还是有一点区别,目前还不知道究竟有什么区别,所以我暂且先认为它俩的概念一致好了。
普通的卷积和池化
-
计算feature_map输出尺寸的公式也比较简单,如下所示:
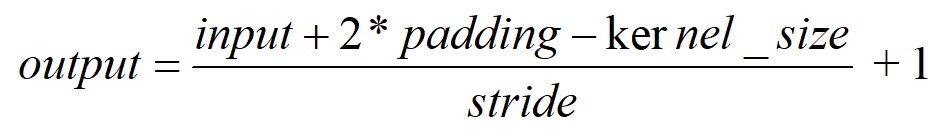
output:卷积后输出feature map的尺寸大小
input:输入图像尺寸大小
padding:在输入图像周围补圈数,padding=1表示在输入图像周围加一圈0
kernel_size:卷积核的大小
stride:卷积核在输入图像作卷积时每一次卷积移动的步长 -
以图二为例:
input=5,padding=1,kernel_size=3,stride=2
output=(5+2x1-3)/2+1=3
- No padding,no strides 图一
- Padding,strides 图二
deconv(transposed conv)
deconv输入输出计算
deconv输出尺寸计算,就是将普通卷积的计算公式中的input和outpu对调下位置。
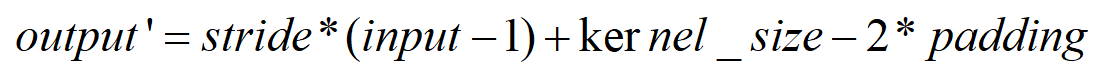

- 以图三为例
input=2,padding=0,kernel_size=3,stride=1
output’=1x(2-1)+3-2x0=4
- No padding,no strides,transposed 图三
- Padding,strides,transposed 图四
deconv原理介绍
根据知乎高赞回答,暂时可以理解了deconv和普通卷积的区别:
- deconv和conv的区别在于在进行网络的前向传播和反向传播计算的时候作相反的计算。
- conv的反向计算公式是deconv的前向传播计算公式,conv的前向传播计算公式deconv的反向传播计算公式
从公式上理解就是如下:
对于一个输入是4x4的feature map,输出是2x2的feature map的conv层
输入矩阵可以展开为16维向量,记为x
输出矩阵可展开为4维向量,记为y
那么卷积运算可以表示y=Cx
C为稀疏矩阵:
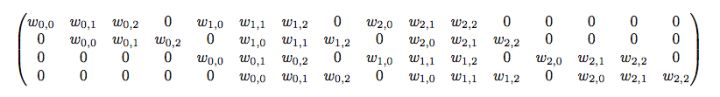
那么前向传播的就是基本的矩阵运算,而反向传播计算类似如下过程:
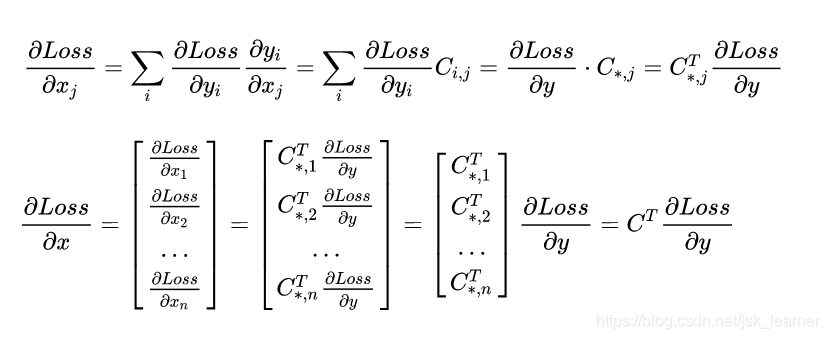
相当于,conv层在进行反向传播的时候是用C的转置矩阵去和梯度作卷积运算。
那么deconv既然称为反卷积,那么确实就和你想的一样,deconv在进行前向传播的时候是用C的转置矩阵去左乘输入矩阵,而在反向传播的时候是用C去左乘输入梯度矩阵。这个就是deconv和conv在计算时的不同,正因为原理是正好反过来的,所以被称为deconv。
仔细观察图一和图三,你会发现它们在No padding和No strides的基础上,输入输出都正好是相反的,这也在一定程度验证了,两者的计算原理确实也正好是相反的。
up sampling(上采样)
根据我查到的资料来看,deconv是up sampling的一种,除此之外还有双线性插值法、up pooling法,但是双线性插值因其简单有效占用资源有少,而且不需要学习参数,一直是图像分割领域使用比较多的上采样方法,FCN这篇图像分割的开山之作就是使用双线性插值法去进行up sampling。
双线性插值法进行up sampling
双线性插值的计算,就是利用待求像素四个相邻像素的灰度在两个方向上作线性内插。
- 示意图如下图所示。

- 我自己手推的计算过程:

up pooling(反池化)
简单原理:在池化过程中,记录下max-pooling在对应kernel中的坐标,在反池化过程中,将一个元素根据kernel进行放大,根据之前的坐标将元素填写进去,其他位置补0
dilated conv
概念背景
No padding, no stride, dilation 空洞卷积示意图
dilated conv就是空洞卷积,其提出的原因背景是:在网络层的下采样中,会将input尺寸进行缩小,但是在图像分割或是其他一些任务甚至是一些特别的网络设计中,为了让input和output的尺寸一致,所以会在网络中进行up sampling,但是up sampling会丢失一部分信息,这是肯定的,无论是采取哪种方式都会丢失信息。所以如果不采用pooling,那么就不需要下采样和上采样步骤了,但是kernel的感受野又会变小,失去了对全局特征的掌握。而采用大的kernel,那么会导致参数增多而且失去了小kernel的正则作用,所以直接将kernel size直接变大不太行。
所以,dilated conv可以在不改变kernel size的条件下,增大卷积核的感受野。
而且设置不同的dilation rate还可以获得多尺度信息。
知乎高赞里的回答:
Up-sampling / pooling layer (e.g. bilinear interpolation) is deterministic. (a.k.a. not learnable)内部数据结构丢失;
空间层级化信息丢失;
小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)
公式计算
dialted conv中的计算有两种方式:
- 将kernel卷积核按照dialted rate进行放大,然后对原图进行卷积
- 将kernel卷积核对feature map进行间隔采样,采样频率就是dilation rate。
1)从原图角度,所谓空洞就是在原图上做采样。采样的频率是根据rate参数来设置的,当rate为1时候,就是原图不丢失任何信息采样,此时卷积操作就是标准的卷积操作,当rate>1,比如2的时候,就是在原图上每隔一(rate-1)个像素采样,如图b,可以把红色的点想象成在原图上的采样点,然后将采样后的图像与kernel做卷积,这样做其实变相增大了感受野。
2)从kernel角度去看空洞的话就是扩大kernel的尺寸,在kernel中,相邻点之间插入rate-1个零,然后将扩大的kernel和原图做卷积 ,这样还是增大了感受野。

(a)图对应3x3的1-dilated conv,和普通的卷积操作一样
(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv)
©图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
公式计算:
k代表kernel size
d代表dilate rate(d=1时表示标准卷积)

用计算得到的新的kernel size去计算output大小。

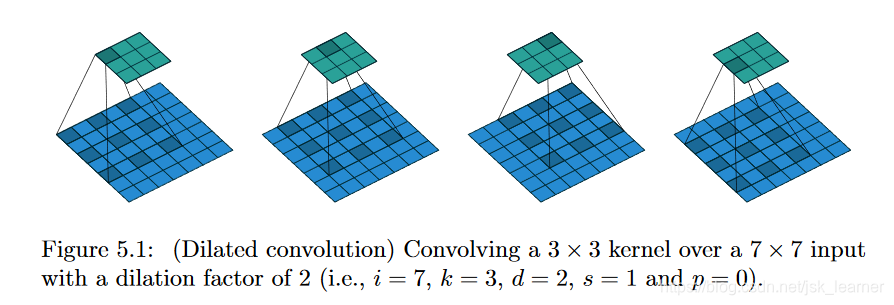
以下图为例计算一下空洞卷积的输出:

一些参考链接:
A guide to convolution arithmetic for deeplearning
动图演示来源
知乎关于deconv原理高赞回答
上采样-up sampling的三种方式
Transposed Convolution, Fractionally Strided Convolution or Deconvolution
Visualizing and Understanding Convolutional Networks
图像处理中两种基本的插值算法(最邻近插值法和双线性内插法)
关于空洞卷积知乎高赞回答
空洞卷积的理解
2019.10.18.
希望能帮到你。点赞是对我最大的认可。谢谢。