
前言
我觉得我是真的和“YoloV3模型没有框”这个问题杠上了。
之前,我被这个问题卡了一个星期,后来虽然解决了,但总感觉这个解决方法看着不是很舒服。对于一个强迫症来说,你要我通过牺牲总体特征的检测效果来满足局部特征的检测,这个方法是有些无法接受的。具体我的解决方法是什么,大家可以参照我之前的两篇博客,我把博客链接写下来了,大家可以直接点击链接跳转过去看一下:

上次有同学私信我,他遇到的情况比计较离谱,他修改了模型的batch_size,其余代码均依照原作者,没有进行改动,loss值降到了21,但是效果还是不行,可行度非常低,而且还出现了分类错误的情况。这种情况下,不仅准确率不高,而且很可能会出现过拟合的现象。
我认为,说到底,我们需要解决的问题还是如何提高模型检测的准确度,只要准确度足够高,anchor box是一定会出现的。
下面我会对这位同学的现象做一些分析。
(以下两张图片由这位同学提供)

减小Batch_size的负面效果:
在之前的博客中,我对batch_size的作用有比较详细的描述。如果我们一次性训练的图片比较多,对这一组图片的总体特征掌握会比较准确,但是在细节方面可能会有所缺失,所以我建议减小batch_size对图片精修,以达到提升准确率的问题。
但是,这样的做法有一个非常明显的问题,我们每次都在寻找当前区域的最小值,而不注重梯度下降的大方向,便非常容易陷在局部最小值中跳不出来。
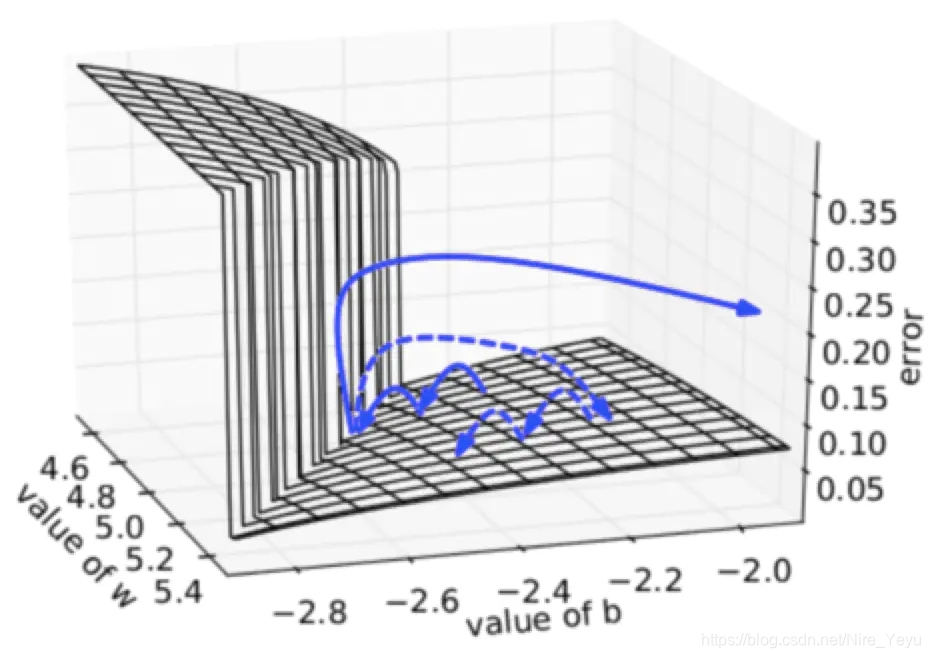
于是,我们看到的现象就是,loss值下降到一定程度后,维持不变,模型出现过拟合现象,但是检测精度依旧非常不理想。
不知道大家能不能理解我的意思。你们可以想象一下,自己正在下山,如果你关注的只是你脚边坡度的下降方向,你一定能很快地往海拔低得位置前进,但是万一遇到一个小坑,你就踩进去了,而且出不来了。你如果看得比较长远,关注坡度的总体下降趋势,你可能有的时候还会走上坡路,但是不会陷在小坑里出不来。
这就是batch_size的实际影响。很显然,这位同学就是遇到了这种情况,因为batch_size减小,陷在一个海拔很高的坑里出不来了,于是导致检测准确度很低。

Learning_rate对检测效果的改善:
为了抵消batch_size减小对于模型带来的负面影响,我们需要调节learning_rate参数值。
调整方法为:初始学习率与batch_size反方向调节。
大家可以想象一下,如果你每次只关注脚下的坡度下降方向,如何防止陷在坑里出不来?方法就是把每一步的步长拉大。
看着眼前,就把步子迈大一点。看着远方,就小心地走好每一步。

Yolo模型的弊端
以上为提高检测精度的一些通用型做法,但是如果检测效果差得离谱,还是需要检查一下下载来的代码是不是真的可靠。
有一种说法是:Yolo源码里的loss没有处理正负样本不平很的问题,所以在训练时容易产生各种各样的问题。对应现象不容易训练出来,而batch_size的减小,使得个别均衡样本促进了模型的收敛,从而大幅提高检测效果。
很多其他的版本,比如darknet对Yolo模型的缺点进行了改进,使得效果更好更稳定。所以如果各位对于这一课题有兴趣,推荐去研究一下不同版本的loss。
如果大家有什么想法,或者什么新的发现,非常欢迎和大家的交流。
