目录:
- 一、参数类型
- 1、不可变类型参数
- 2、可变类型
- 二、命名空间
- 1、命名空间的访问
- 2、命名空间加载顺序
- 3、命名空间查找顺序
- 三、作用域
- 四、全局变量和局部变量
- 五、global 和 nonlocal 关键字
- 六、内建函数(高阶函数)
- 1、abs()
- 2、max()
- 3、min()
- 4、map()
- 5、filter()
- 6、zip()
- 7、eval()
- 七、匿名函数 [重点]
- 八、闭包,装饰器 [重点]
- 1、闭包
- 2、装饰器 [这里简单讲解、详细参考我博客另外篇文章,详解装饰器]
创作不易,各位看官,点个赞收藏、关注必回关、QAQ、您的点赞是我更新的最大动力!(别问为什么我每篇文章排版有点不同,问就是我想到啥用啥。。。。太难了)


一、参数类型
1、不可变类型参数| 不可变参数类型:整数、字符串、元组 函数内部修改参数的值,只是修改另一个复制的对象,不会影响变量本身 |
传递不可变类型参数,不会影响参数本身
a = 1000
print("函数外边a的值---->",id(a))
print("a的值",a)
def func(b):
# a和 b的id值相同
print("函数内容传递过来的id值",id(b))
print("b的值",b)
# 修改b的值
b = 200
print("修改后b的id--->",id(b))
print("修改后b的值",a)
func(a)
print("b值修改后,a的值",a)
print(id(a))


2、可变类型
| 可变类型:列表、字典。如fun(la) 则是将参数真正的传过去,修改后函数外部的变量也会受影响 |
传递可变类型参数,会影响参数本身
list_outer = [1,2,3]
print("list_outer的值和id值",list_outer,id(list_outer))
def func(list_inner):
print("list_inner的值和id值",list_inner,id(list_inner))
list_inner.append(4)
print("修改后的list_inner的值和id值",list_inner,id(list_inner))
func(list_outer)
print("修改后的list_outer的值和id值",list_outer,id(list_outer))


笔试原题
def func(name,lst=[]):
lst.append(name)
print(lst)
func("刘亦菲")
func("刘亦菲")
func("刘亦菲",[])
func("刘亦菲")

二、作用空间
| 命名空间指的是保存程序中的变量名和值的地方。 |
| 命名空间的本质是一个字典,用来记录变量名称和值。字典的 key 是变量的名称,字典的 value 对于的是变量的值 |
| 例如 {‘name’:’zs’,’age’:10} 命名空间一共分为三种: 局部命名空间、全局命名空间、内置命名空间 |
| 局部空间:每个函数都有自己的命名空间,叫做局部空间,它记录了函数的变量,包括函数的参数和局部定义的变量 |
| 全局空间:每个模块拥有它自已的命名空间,叫做全局命名空间,它记录了模块的变量,包括函数、类、其它导入的模块 |
| 内置命名空间:任何模块均可访问它,它存放着内置的函数和异常input,print,str,list,tuple… |
1、命名空间的访问
局部名称空间使用 locals() 函数来访问
全局命名空间的访问使用 globals()函数访问
局部命名空间和全局命名空间:
num = 5
def func(name,age):
num1 = 10
ret = locals()
print(ret)
func("稳稳c9",20)
ret = globals()
print(ret)

只截取了一部部分,太长了后面。。。。。
第一个是 func 函数内部打印出来的
第二个是 程序最后 打印出来的 那一长串,拉到最后,发现这个是全局变量,还有好多内置变量名称

2、命名空间的加载
| 内置命名空间(程序运行前加载)->全局命名空间(当程序运行的时候加载全局命名空间)->局 部命名空间(程序运行中:函数被调用时才加载)当函数返回结果或抛出异常时,被删除。每 一个递归调用的函数都拥有自己的命名空间 |
| 简单总结: 内置->全局–>局部 |
3、命名空间查找顺序
| 当使用某个变量的时候,先从局部命名空间中找,如果能找到则停止搜索,如果找不到在去 全局名称空间中查找,如果找到则停止搜索,如果找不到则到内置名称空间中查找,如果找 不到则报错 |
# 命名空间加载顺序:内置->全局-->局部
print("hello world")
name = "稳稳"
# print(name)
def func():
name = "小明"
print(name)
# 命名空间查找顺序:局部-->全局-->内置
name = "稳稳"
id = 3
def func2():
# id = 10
print(id)
func2()
# 嵌套函数:当前函数-->父函数-->全局-->内置
id = 10
def func1():
# id = 20
def func2():
# id = 30
print(id)
func2()
func1()
# 内置命名空间有一个id()函数
# 全局变量空间中有一个id=10变量
id = 10
def func():
# 局部命名空间中有一个id = 20 变量
id = 20
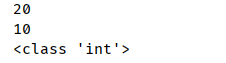
print(id) # 先打印20,然后打印10,最后打印id函数的内存地址
func()
print(id) # 全局变量id
print(type(id)) # 全局变量id的类型

嵌套函数的情况:
1、先在当前 (嵌套的或 lambda) 函数的命名空间中搜索
2、然后是在父函数的命名空间中搜索
3、接着是模块命名空间中搜索
4、最后在内置命名空间中搜索
三、作用域
作用域指的是变量在程序中的可应用范围
作用域按照变量的定义位置可以划分为 4 类即
LEGB Local(函数内部)局部作用域
Enclosing(嵌套函数的外层函数内部)嵌套作用域(闭包)
Global(模块全局)
全局作用域 Built-in(内建)内建作用域

1.Python 内层作用域访问外层作用域时的顺序
2.Python搜索4个作用域
3.[本地作用域(L)之后是上一层结构中def或者lambda的本地作用域(E),
4.之后是全局作用域(G)最后是内置作用域(B)(即 Python 的内置类和函数等)
5.并且在第一处能够找到这个变量名的地方停下来。
6.如果变量名在整个的搜索过程中都没有找到,Python 就会报错
注意:
1.在Python 中,模块(module),类(class)、函数(def、lambda)会产生新的作用域,
2.其他代码块是不会产生作用域的,也就是说,类似条件判断(if…..else)、
3.循环语句(for x in data)、 异常捕捉(try…catch)等的变量是可以全局使用的
四、全局变量和局部变量
1.在函数中定义的变量称为局部变量,只在函数内部生效
2.在程序一开始定义的变量称为全局变量,全局变量的作用域是整个程序
全局变量是不可变数据类型,函数无法修改全局变量的值
# 全局变量与局部变量重名后,是否相互影响?
age = 10
def test3():
age = 20
print(age) # --> 20
test3()
print(age) #--> 10
全局变量是可变数据类型,函数可以修改全局变量的值
names = ["小明","小红"]
def func():
names.append("稳稳")
func()
print(names)
五、global 和 nonlocal关键字
1、global 关键字可以将局部变量变成一个全局变量
# global
name = "稳稳"
def func():
global name #声明全局变量
name = "小明"
print("内部:",name) # --> 内部: 小明
func()
print("外部:",name) # --> 外部:小明
2、nonlocal 关键字可以修改外层(非全局)变量
# nonlocal
name = "稳稳"
def func1():
name = "小明"
def func2():
#在func2中修改name = "小明"
nonlocal name
name = "小红"
func2()
print("嵌套:",name) # --> 嵌套:小红
func1()
print("全局:",name) # --> 全局:稳稳
六、内建函数(高阶函数)
参考网址:http://www.runoob.com/Python/Python-built-in-functions.html
这里有些就只提到基本用法,大部分详解扩展
| 这里就提到常用到的 | |
|---|---|
| abs( ) | 求绝对值 |
| max( ) | 最大值 |
| min( ) | 最小值 |
| map( ) | 是按照指定规则进行数据转换 |
| filter( ) | 用于按照条件是否满足进行数据过滤 |
| zip( ) | 是按照数据映射关系进行关联/合并/压缩 |
| eval( ) | 给函数 eval()传递一个字符串参数,将这个字符串参数转换成 python 表达式直接执行。 |
1、abs( ) 函数
print(abs(-5)) # 5
2、max() 函数
1.max(ITerable, key, default) 求迭代器的最大值
2.其中 ITerable 为迭代器,max 会 for i in … 遍历一遍这个迭代器
3.然后将迭代器的每一个返回值当做参数传给 key=func 中的 func
4.func(一般用 lambda 表达式定义) ,然后将 func 的执行结果传给 key,
5.然后以 key 为标准进行大小的判断
简而言之 max(迭代式(数据,参数,变量),key=函数名)
需要知道 会自动 for 遍历!!!!注意!!!!别老想着自己去遍历!!!
(1) 简单使用 max() 函数
lst = [2,1,6,3,4]
ret = max(lst)
print(ret) # --> 6
(2) 使用key 关键字
# #求绝对值最大的数 -8
lst2 = [-2,5,-8,3,6,1]
ret = max(lst2,key=abs) #[2,5,8,3,6,1]
print(ret) # --> -8
#求相反数最大的数 -10
lst3 = [2,6,-10,50]
def func(num):
return -1*num
ret = max(lst3,key=func)
print(ret) # --> -10
string = "abc1122aabdddccddwddd"
#使用max()函数找出出现次数最多的字符
ret = max(string,key=string.count)
print(ret) # --》d
可以看到,不仅仅这个函数可以是内置,还可以是自定义
(3)根据 age 和 score 返回最大信息
lst = [
{"name":"小明","age":20,"score":90},
{"name":"小王","age":22,"score":95},
{"name":"稳稳","age":21,"score":97},
]
# 返回年龄最大的那组信息 #{'name': '小王', 'age': 22, 'score': 95}
# 返回分数最大的那组信息 #{'name': '稳稳', 'age': 21, 'score': 97}
def max_age(dic):
return dic["age"]
ret1 = max(lst,key=max_age)
print(ret1)
def max_score(dic):
return dic["score"]
ret2 = max(lst,key=max_score)
print(ret2)
3、min()函数
略过,参考 max() QAQ
4、map()函数
# map(func,iterable) 函数,第一个参数是函数,第二个参数是可迭代对象。
# 函数会作用在可迭代内容的每一个元素上进行计算,返回一个新的可迭代内容
# 求列表中每一个元素的平方
lst3 = [1,2,3]
ret = [i*i for i in lst3]
print(ret) #[1,4,9]
def func(num):
return num**2
ret2 = map(func,lst3)
print(ret2) # <map object at 0x000001C418E19B38>
# for i in ret:
# print(i,end=' ')
print(list(ret2)) #[1, 4, 9]
看第二个例子
#求两个列表中元素相加的和
lst1 = [1,2,3,4,5,6,7,8]
lst2 = [2,3,4,5,6]
def func(x,y):
return x+y
ret = map(func,lst1,lst2)
print(list(ret))
5、filter()函数
1.filter() 函数用于过滤序列,过滤掉不符合条件的元素,
2.返回由符合条件元素组成的新列表 该接收两个参数,第一个为函数,第二个为序列,
3.序列的每个元素作为参数传递给函数进判 然后返回 True 或 False,
4.最后将返回 True 的元素放到新列表中
重点是过滤筛选
lst4 = [1,2,3,4,5,6,7,8,9]
#过滤列表中的所有奇数
def func(num):
if num%2==0:
return True
else:
return False
# return num%2==0
# return True if num%2==0 else False
ret = filter(func,lst4) # [2,4,6,8]
print(list(ret))
6、zip()函数
1.zip 函数接受任意多个可迭代对象作为参数,将对象中对应的元素打包成一个 tuple
2.然后返回一个可迭代的 zip 对象.这个可迭代对象可以使用循环的方式列出其元素
3.若多个可迭代对象的长度不一致,则所返回的列表与长度最短的可迭代对象相同
其实可以制作密码表
lst1 = [1,2,3]
lst2 = [4,5,6]
#转换为(1,4),(2,5),(3,6)
ret = zip(lst1,lst2)
print(list(ret))
#密码表制作可以可以
str1 = "abc"
str2 = "12345"
ret = zip(str1,str2)
print(tuple(ret))
# 现有两个元组(('a'),('b')),(('c'),('d')),请生成[{'a':'c'},{'b':'d'}格式。
tup1 = ('a','b')
tup2 = ('c','d')
def func(x,y):
return {x:y}
ret = map(func,tup1,tup2)
print(list(ret))
def func(tup):
return {tup[0]:tup[1]}
ret = zip(tup1,tup2)
# print(tuple(ret))
ret2 = map(func,ret)
print(list(ret2))
ret = list(map(lambda tup:{tup[0]:tup[1]},zip(tup1,tup2)))
print(ret)
7、eval()函数
1.给函数 eval()传递一个字符串参数
2.eval()函数会将这个字符串参数转换成 python 表达式直接执行。
我经常用来做目录跳转
简单的页面跳转
# 登录菜单跳转字典
login_dict = {
"1": "login()",
"2": "regist()",
}
#首页界面
def show_menu():
#打印菜单
print(" 1.用户登录")
print(" 2.用户注册")
#做出选择
choice = input("请输入您的选项:")
# 从登录菜单跳转字典获取相应的选项结果
result = login_dict.get(choice,"show_menu()")
"""
choice:用户选项
"show_menu()":如果用户没有输入 跳转字典的对应键 即编号 就返回show_menu()
有的话就 返回 值(函数名称)
"""
eval(result) #执行函数 return eval(result)
def login():
print("我是登录")
def regist():
print("我是注册")
show_menu()
如果出现问题 可以进行判断是否为空
# 用户输入选项
choice = input("请输入您的选项:").strip()
opra = login_dict.get(choice, "show_menu()")
res = eval(opra)
if res != None:
return eval(res)
七、匿名函数
| 匿名函数,就是没有名称的函数,只需要函数的声明即可! |
| python 中提供了一个 lambda语法用来表示匿名函数 |
| 语法: |
|---|
| 变量名= lambda 参数:表达式(block) 参数:可选,通常以逗号分隔的变量表达式形式,也就是位置参数 表达式:不能包含循环、return,可以包含 if…else… |
| 注意: |
|---|
| 1.表达式中不能包含 循环,return |
| 2.可以包含 if…else…语句 |
| 3.表达式计算的结果直接返回 |
1、创建函数,无参数
ret = lambda :3<5
print(ret()) # True
2、创建函数,有参数
ret2 = lambda x,y:x<y
print(ret2(3,5)) #True
# 用三元表达式
ret3 = lambda x,y:x if x<y else y
print(ret3(3,5))
3、返回参数中较小的数
lst = [
{"name":"小明","age":20,"score":90},
{"name":"小王","age":22,"score":95},
{"name":"小红","age":21,"score":97},
]
#返回年龄最大的那组信息,使用匿名函数
ret = max(lst,key=lambda dic:dic["age"])
print(ret) # {'name': '小王', 'age': 22, 'score': 95}
4、求列表中每一个元素的平方
lst3 = [1,2,3]
ret = list(map(lambda i:i**2,lst3))
print(ret) # --> [1,4,9]
5、过滤列表中的所有奇数
lst4 = [1,2,3,4,5,6,7,8,9]
ret = list(filter(lambda i:i%2==0,lst4))
print(ret) # -->[2, 4, 6, 8]
6、现有两个元组((‘a’),(‘b’)),((‘c’),(‘d’)),请生成[{‘a’:‘c’},{‘b’:‘d’}格式
tup1 = ('a','b')
tup2 = ('c','d')
tup3 = tuple(zip(tup1,tup2))
print(tup3) # -->(('a', 'c'), ('b', 'd'))
ret = list(map(lambda tup:{tup[0]:tup[1]} ,tup3))
print(ret) # -->[{'a': 'c'}, {'b': 'd'}]
| lambda 表达式也会产生一个新的局部作用域。 |
| 在 def 定义的函数中嵌套 labmbda 表达式 |
| lambda 表达式 能够看到所有 def 定义的函数中可用的变量 |
def func():
name = "稳稳"
ret = lambda :name
print(ret()) # -->稳稳
func()
def func():
x = 4
action = lambda n,y=x:y**n
return action
x = func()
print(x(2)) # -->16

def func():
x = 4
def action(n,y=x):
return y**n
return action
x = func()
print(x(2)) # 16
#y是一个默认参数,形参
def func():
x = 4
action = lambda n,x=x:x**n
return action
x = func()
print(x(2))
7、请说出 acts0的值,并且说明为什么
def makeAction():
lst = []
for i in range(4):
lst.append(lambda x:i**x)
return lst
acts = makeAction()
print(acts[0](2),acts[1](2),acts[2](2),acts[3](2))

八、闭包、装饰器
1、闭包闭包是一种函数声明语法,就是在函数中声明函数!
| 闭包三要素 |
|---|
| 1.嵌套 |
| 2.内层函数使用外层函数的变量 |
| 3.外层函数返回内层函数的引用 |
def outter(num):
def inner():
print(num)
return inner
ret = outter(5)
ret()
| 为什么要使用闭包? |
|---|
| 真正开发的时候,开发人员分模块开发使用变量或者函数名可能会重复、合并的时造成 [全局污染] |
| 闭包就是在函数中定义的函数!闭包的操作是多人协同开发时,不同的功能模块可能会造 成全局变量的冲突,会导致全局变量的数据互相覆盖。所以通过闭包的方式将不同的功能 模块进行分离的过程 |
def wenwen_program():
tools = "测试"
def use():
print(f"{tools}")
use()
def admin_program():
tools = "维护"
def use():
print(f"{tools}")
use()
wenwen_program()
admin_program()
2、装饰器
| 软件开发原则 |
|---|
| 软件开发过程中,约定俗成了一些开发规则,这些开发规则都是一些成熟的经验,在满足规则的情况下开发软件,可以最大程度的减少错误出现的几率。 |
| 通常有软件开发六原则的说法: |
| ⚫ 开闭原则(OCP):软件中对扩展开放,对修改关闭 ⚫ 依赖导致原则 ⚫ 接口隔离原则 ⚫ 迪米特法则 ⚫ … |
| 剩余的可以百度百科、那么这里就运用到开闭原则 |
| 需求分析 |
|---|
| 不同部门都需要进行验证 |
1、在之前没有接触的话,肯定在每个封装函数里面加入验证功能
def f1():
print("身份验证")
print("f1")
def f2():
print("身份验证")
print("f2")
def f3():
print("身份验证")
print("f3")
f1()
f2()
f3()
2、但是发现上面那种太复杂了,能不能将身份验证单独成立个共性函数(先复习下闭包)
那么我们遵循OCP 软件开闭原则
#封闭:已经写好的代码,不轻易修改
#开放:可以对外拓展功能
def outter(f):
def inner():
print("身份验证")
f()
return inner
def f1():
print("f1")
f1 = outter(f1)
f1()
"""
1.定义outter,f1函数
2.调用outter函数,并将函数对象f1当成参数传递过去 f1-->f
定义inner函数,将inner函数对象返回
并赋值给等号左边的f1变量 f1实际指向inner函数
3.f1() 执行inner函数
-->print("身份验证")
-->执行f,即执行传过来的函数对象f1(), print("f1")
"""
3、复习完闭包完善一下代码 即装饰器的运用
def outter(f): # f = func()
def inner():
print("--before inner--")
f()
print("--after inner--")
print("--outter---")
return inner
@outter # →func = outter(func)
def func():
print("这是func函数")
# func = outter(func)
func()

详细的装饰器原理,参考我的另外篇文章: