前言
在互联网应用系统中,扩展最为方便的可能要数最基本的 Web 应用服务了。因为Web应用服务大部分情况下都是无状态的,也很少需要保存太多的数据,当然Session 这类信息比较例外。所以,对于基本的 Web应用服务器很容易通过简单的添加服务器并复制应用程序来做到 Scale Out(横向扩展)。
什么是Replication,干什么用的呢
MySQL Replication 功能主要解决Scale Out(横向扩展)。 通过MySQL 的 Replication 功能, 我们可以非常方便的将一个数据库中的数据复制到很多台MySQL主机上面,组成一个MySQL集群,然后通过这个 MySQL 集群来对外提供服务。这样,每台MySQL 主机所需要承担的负载就会大大降低,整个MySQL集群的处理能力也很容易得到提升。
Replication是怎么个工作的呢,背后的逻辑或原理是什么样子的
Replication 整体介绍
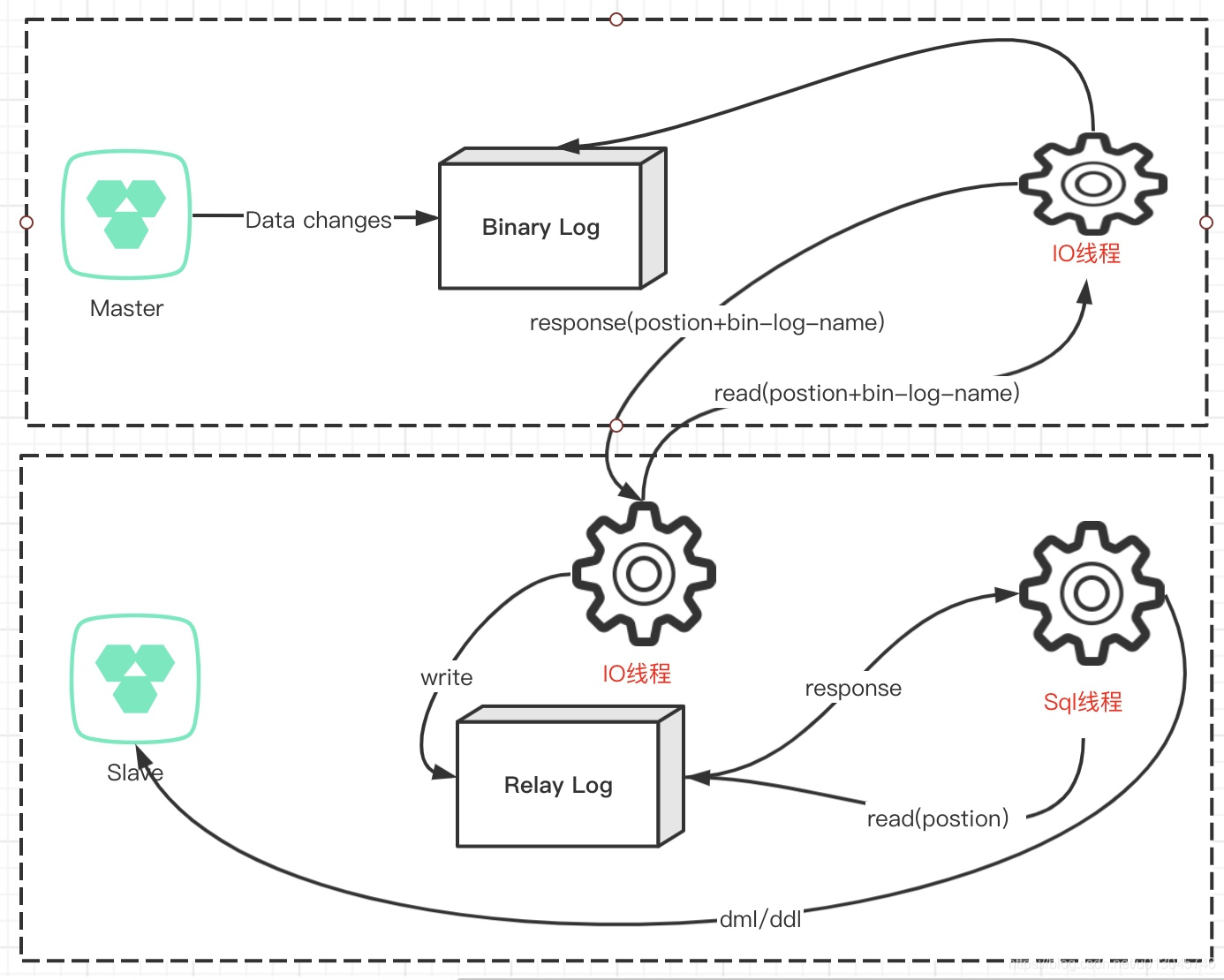
Mysql 的 Replication 是一个异步的复制过程,从一个 Mysql Instace(Master)复制到另一个Mysql Instance(Slave)。在Master与Slave之间的实现整个复制过程主要由三个线程来完成,其中两个线程(Sql线程和IO线程)在Slave端,另外一个线程(IO线程)在 Master端。
Replication 线程总结 敲黑板,划重点
Master
- IO线程
Slave
- IO线程
- Sql线程
背后操作逻辑(实现原理)
- 首先打开Master端的Binary Log(mysql- bin.xxxxxx)功能,否则无法实现。因为整个复制过程实际上就是Slave 从 Master 端获取 该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。
- Slave上面的IO线程连接上Master, 并请求从指定日志文件的指定位置 (或从者最开始的日志)之后的日志内容。
- Master接收到来自Slave的IO线程的请求后,通过负责复制的IO线程根据请求信息读取指定日志指定位置之后的日志信息,返回给Slave端的IO线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在Master端的Binary Log文件的名称以及在 Binary Log中的位置。
- Slave的IO线程接收到信息后,将接收到的日志内容依次写入到Slave端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的Master端的bin-log的文件名和位置记录到 master-info 文件中,以便在下一次读取的时候能够清楚的高速 Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”
- Slave的SQL线程检测到Relay Log中新增加了内容后,会马上解析该Log文件中的内容成为在Master 端真实执行时候的那些可执行的Query语句,并在自身执行这些Query。这样,实际上就是在Master端和Slave端执行了同样的Query,所以两端的数据是完全一样的
敲黑板、划重点、总结
- 开启Binary Log
- Slave上的IO线程连接上Master 根据postion+bin-name 拉取数据
- Master复制IO线程根据postion读取信息返回信息包含(postion+bin-name)
- Slave IO线程接受信息之后写Relay Log 读取Master返回的(postion+bin-name)写入master-info中,供下次使用
- Slave Sql线程检测Relay Log 新增的内容 解析并执行
流程图
仅供参考
扩展
实际上,在老版本中,MySQL的复制实现在Slave端并不是由SQL线程和IO线程 这两个线程共同协作而完成的,而是由单独的一个线程来完成所有的工作。但是MySQL的工程师们很快发现,这样做存在很大的风险和性能问题。
主要如下:
- 首先,如果通过一个单一的线程来独立实现这个工作的话,就使复制Master端的,Binary Log日志,以及解析这些日志,然后再在自身执行的这个过程成为一个串行的过程,性能自然会受到较大的限制,这种架构下的Replication的延迟自然就比较长了。
- 其次,Slave端的这个复制线程从Master端获取 Binary Log过来之后,需要接着解析这些内容,还原成Master端所执行的原始Query,然后在自身执行。在这个过程中,Master 端很可能又已经产生了大量的变化并生成了大量的Binary Log 信息。如果在这个阶段 Master 端的存储系统出现了无法修复的故障,那么在这个阶段所产生的所有变更将都 永远的丢失,无法再找回来。这种潜在风险在Slave端压力比较大的时候尤其突出,因为如果 Slave 压力比较大,解析日志以及应用这些日志所花费的时间自然就会更长一些,可能丢失的数据也就会更多。
- 所以,在后期的改造中,新版本的MySQL为了尽量减小这个风险,并提高复制的性能,将 Slave 端的复制改为两个线程来完成,也就是前面所提到的SQL线程和 IO 线程。既在很大程度上解决了性能问题, 缩短了异步的延时时间,同时也减少了潜在的数据量丢失。
- 当然,即使是换成了现在这样两个线程来协作处理之后,同样也还是存在Slave 数据延时以及数据丢失的可能性的,毕竟这个复制是异步的。只要数据的更改不是在一个事务中,这些问题都是存在的。如果要避免这些问题就需要用Mysql Cluster来解决。敬请关注
敲黑板、划重点、总结
- 历史版本 单线程操作、性能低下、延迟高
- 后期版本改进IO进程和SQL进程 提升性能、降低延迟
- 即使如此、存在数据延时、数据丢失的可能性、可以通过Mysql Cluster 来解决
上面我们了解了什么是Replication,以及是干什么的,下面我们来了解下Replication的复制实现级别
Replication 复制级别 整体介绍
MySQL的复制可以是基于一条语句(Statement Level),也可以是基于一条记录(Row level),可以在 MySQL的配置参数中设定这个复制级别,不同复制级别的设置会影响到 Master端的Binary Log记录成不同的形式。
Statement Level
每一条会修改数据的Query都会记录到Master的Binary Log中。Slave在复制的时候SQL线程会解析成和原来Master端执行过的相同的Query来再次执行。
优点
Statement Level下的优点首先就是解决了Row Level下的缺点,不需要记录每一行数据的变化,减少Binary Log日志量,节约了IO成本,提高了性能。因为他只需要记录在 Master上所执行的语句的细节,以及执行语句时候的上下文的信息。
敲黑板、划重点、总结
- 数据量少、节约IO成本、性能提升
缺点
由于它是记录的执行语句,所以,为了让这些语句在slave 端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所语有句在 slave 端杯执行的时候能够得到和在Master端执行时候相同的结果。另外就是,由于Mysql现在发展比较快,很多的新功能不断的加入,使Mysql 得复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在statement level下,目前已经发现的就有不少情况会造成mysql的复制出现问题,主要是修改数据的时候使用某了些特定的函数或者功能的时候会出现,比如:sleep(),rand()函数在有些版本中就不能真确复制,在存储过程中使用了 last_insert_id()函数,可能会使 slave 和 master上得到不一致的id等等。由于row level是基于每一行来记录的变化,所以不会出现类似的问题。
敲黑板、划重点、总结
- 为了保证正确的执行,需要记录上下文信息
- 由于是语句复制,特定的函数无法复制,例如:rand()last_insert_id()。
Row Level
Binary Log中会记录成每一行数据被修改的形式,然后在Slave端再对相同的数据进行修改。
优点
在 Row Level模式下,Binary Log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以Row Level 的日志内容会非常清楚的记录下每一行数据修改的细节, 非常容易理解。 而且不会出现某些特情定况下的存储过程,或function以及trigger的调用和触发无法被正确复制的问题。
敲黑板、划重点、总结
- 数据准确、清晰、易理解
- 不会出现特殊函数复制不了的问题
缺点
Row Level下,所有的执行的语句当记录到Binary Log 中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,
比如有这样一条update语句
UPDATE group_message SET group_id = 1 where group_id = 2
执行之后,日志中记录的不是这条update语句所对应的事件(MySQL 以事件的形式来记录Binary Log日志)
而是这条语句所更新的每一条记录的变化情况,这样就记录成很多条记录被更新的很多个事件。自然Binary Log日志的量就会很大。
尤其是当执行ALTER TABLE 之类的语句的时候,产生的日志量是惊人的。
因为MySQL对于ALTER TABLE之类的DDL变更语句的处理方式是重建整个表的所有数据,也就是说表中的每一条记录都需要变动,那么该表的每一条记录都会被录记到日志中。
敲黑板、划重点、总结
- 数据量大、IO消耗比较大、性能低
Replication 常用的架构
- 常规复制架构(Master - Slaves)
- Dual Master复制架构(Master - Master)
- 级联复制架构(Master - Slaves - Slaves …)
- Dual Master与级联复制结合架构(Master - Master - Slaves)