写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
上一篇博客博主已经为大家从发展史到基本实战为大家详细介绍了StructedStreaming(具体请见:《看了这篇博客,你还敢说不会Structured Streaming?》)。本篇博客,博主将紧随前沿,为大家带来关于StructuredStreaming整合Kafka和MySQL的教程。
码字不易,先赞后看,养成习惯!

1.整合Kafka
1.1 官网介绍
http://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
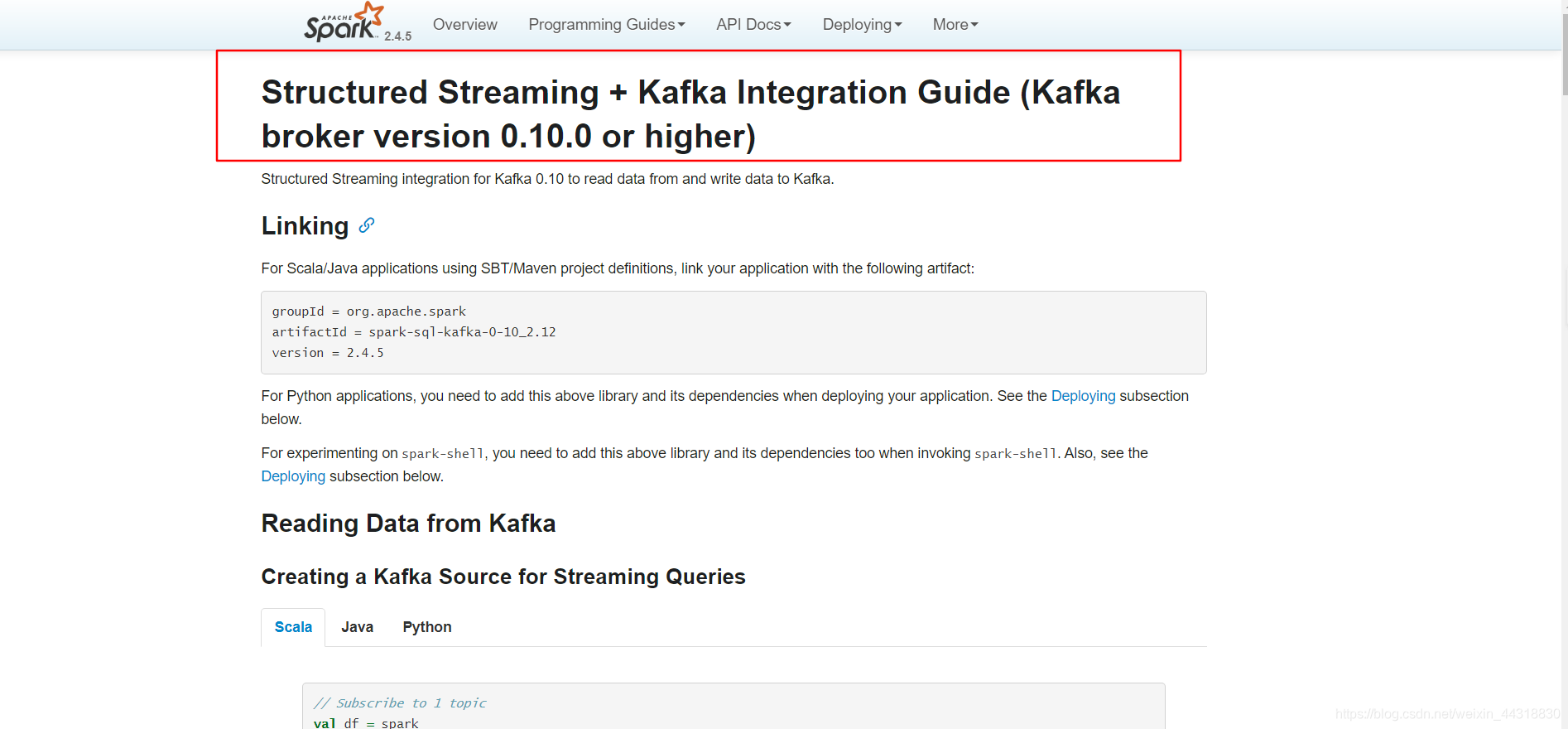
从官网上已经给出的申明来看,Kafka的版本需要0.10.0或更高版本
- Creating a Kafka Source for Streaming Queries
// Subscribe to 1 topic
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to multiple topics(多个topic)
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern(订阅通配符topic)
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
- Creating a Kafka Source for Batch Queries(kafka批处理查询)
// Subscribe to 1 topic
//defaults to the earliest and latest offsets(默认为最早和最新偏移)
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to multiple topics, (多个topic)
//specifying explicit Kafka offsets(指定明确的偏移量)
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""")
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""")
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern, (订阅通配符topic)at the earliest and latest offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
- 注意:读取后的数据的Schema是固定的,包含的列如下:
| Column | Type | 说明 |
|---|---|---|
| key | binary | 消息的key |
| value | binary | 消息的value |
| topic | string | 主题 |
| partition | int | 分区 |
| offset | long | 偏移量 |
| timestamp | long | 时间戳 |
| timestampType | int | 类型 |
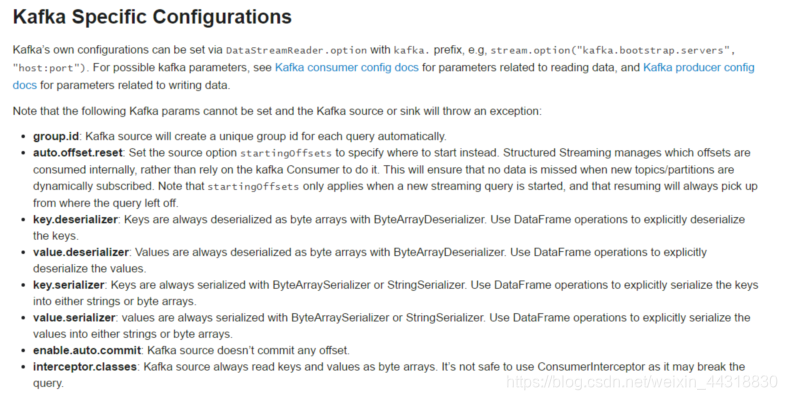
- 注意:下面的参数是不能被设置的,否则kafka会抛出异常:
group.id:kafka的source会在每次query的时候自定创建唯一的group id
auto.offset.reset:为了避免每次手动设置startingoffsets的值,structured streaming在内部消费时会自动管理offset。这样就能保证订阅动态的topic时不会丢失数据。startingOffsets在流处理时,只会作用于第一次启动时,之后的处理都会自动的读取保存的offset。
key.deserializer,value.deserializer,key.serializer,value.serializer:序列化与反序列化,都是ByteArraySerializer
enable.auto.commit:Kafka源不支持提交任何偏移量
1.2 整合环境准备
- 启动kafka
/export/servers/kafka/bin/kafka-server-start.sh -daemon
/export/servers/kafka/config/server.properties
- 向topic中生产数据
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list node01:9092 --topic demo01
1.3 代码演示
书写代码
object demo03_kafka {
def main(args: Array[String]): Unit = {
// 准备环境
val spark: SparkSession = SparkSession.builder()
.appName("demo03")
.master("local[*]")
.getOrCreate()
// 设置日志级别
spark.sparkContext.setLogLevel("WARN")
// 导入隐式转换
import spark.implicits._
// 读取数据流中的数据
val kafkaDatas: DataFrame = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "node01:9092,node02:9092,node03:9092") // 设置kafka集群
.option("subscribe", "demo01") // 设置需要读取的主题topic
.load() // 加载数据
// kafkaDatas 内部数据是kafka数据(key,value)
val kafkaDataString: Dataset[(String, String)] = kafkaDatas.selectExpr("CAST(key AS string)","CAST(value AS string)").as[(String,String)]
// 处理,将数据按照空格切分
val word: Dataset[String] = kafkaDataString.flatMap(x=>x._2.split(" "))
// 利用DSL语句对数据进行wordcount
val wordCount: Dataset[Row] = word.groupBy("value").count().sort($"count".desc)
// 输出
wordCount.writeStream.format("console") // 输出方式,console表示控制台
.outputMode("complete") // 输出模式
.start() // 开启任务
.awaitTermination() // 等待程序停止
}
}
运行程序,此时kafka中还未生产数据,程序处于等待状态
接着,在kakfa集群生产一批数据
[root@node01 ~]# /export/servers/kafka_2.11-1.0.0/bin/kafka-console-producer.sh --broker-list node01:9092 --topic demo01
>hadoop hive spark hive flink
接着我们可以看到,
StructuredStreaming获取到kafka中生产的数据,并做了一个简单的wordcount并在控制台输出结果
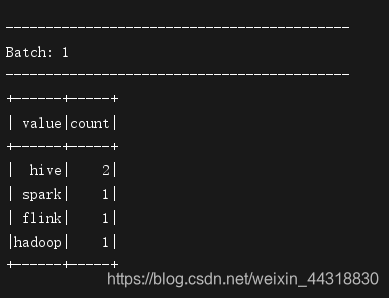
看到类似的效果,说明我们用StructuredStreaming整合Kafka就完成了~
2.整合MySQL
2.1 简介
- 需求
我们开发中经常需要将流的运算结果输出到外部数据库,例如MySQL中,但是比较遗憾Structured Streaming API不支持外部数据库作为接收器
如果将来加入支持的话,它的API将会非常的简单比如:
format(“jdbc”).option(“url”,“jdbc:mysql://…”).start()
但目前还无法做到,但是目前我们只能自己自定义一个JdbcSink,继承ForeachWriter并实现其方法。
- 参考网站
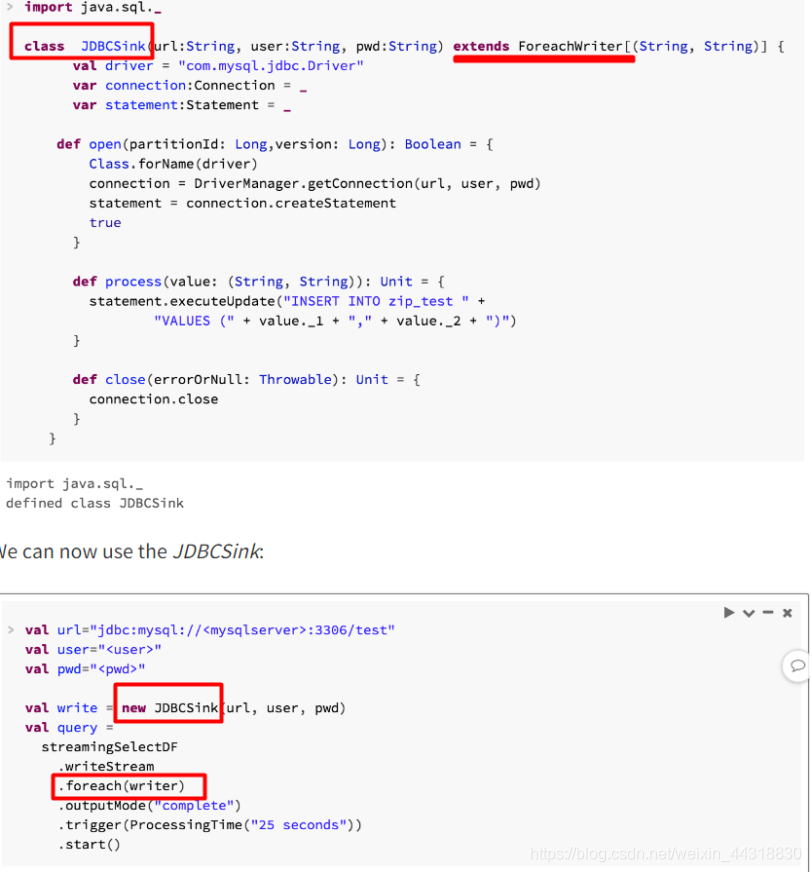
2.2 环境准备
在自己的数据库下创建一个表t_word,保存每个单词出现的次数
CREATE TABLE `t_word` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(255) NOT NULL,
`count` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `word` (`word`)
) ENGINE=InnoDB AUTO_INCREMENT=26 DEFAULT CHARSET=utf8;
检查创建出的表,此时还没有数据
2.3 代码演示
object StructStreamingKafkaMysql {
def main(args: Array[String]): Unit = {
// 准备环境
val spark: SparkSession = SparkSession.builder()
.appName("demo03")
.master("local[*]")
.getOrCreate()
// 设置日志级别
spark.sparkContext.setLogLevel("WARN")
// 导入隐式转换
import spark.implicits._
val kafkaDatas: DataFrame = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "node01:9092,node02:9092,node03:9092")
.option("subscribe", "demo01")
.load()
//3.处理数据
//注意:StructuredStreaming整合Kafka获取到的数据都是字节类型,所以需要按照官网要求,转成自己的实际类型
// kafkaDatas 内部数据是kafka数据(key,value)
val kafkaDataString: Dataset[(String, String)] = kafkaDatas.selectExpr("CAST(key AS string)", "CAST(value AS string)").as[(String, String)]
// 处理
val word: Dataset[String] = kafkaDataString.flatMap(x => x._2.split(" "))
val wordCount: Dataset[Row] = word.groupBy("value").count().sort($"count".desc)
val intoMYSQL: intoMysql = new intoMysql("jdbc:mysql://localhost:3306/rng_comment?characterEncoding=UTF-8", "root", "root")
// 输出
wordCount.writeStream.foreach(intoMYSQL) // 遍历流中的数据,调用功能类,将其保存/更新到数据库
.outputMode("complete") // 设置输出模式
.start() // 开启任务
.awaitTermination() // 等待程序结束
}
// 创建一个类,编写将数据更新/插入到mysql数据库的代码
class intoMysql(url: String, username: String, password: String) extends ForeachWriter[Row] with Serializable {
// 准备连接对象
var connection: Connection = _
// 设置sql
var preparedStatement: PreparedStatement = _
// 用于打开数据库连接
override def open(partitionId: Long, version: Long): Boolean = {
// 获取链接
connection = DriverManager.getConnection(url, username, password)
//获取链接无误返回True
true
}
// 用于更新/插入数据到mysql
override def process(value: Row): Unit = {
// value内的第一个数是单词
val word: String = value.get(0).toString
// value内的第二个数是单词的数量
val count: Int = value.get(1).toString.toInt
// 打印结果
println("word:" + word + "\tcount:" + count)
//REPLACE INTO:表示如果表中没有数据这插入,如果有数据则替换
//注意:REPLACE INTO要求表有主键或唯一索引
val sql = "REPLACE INTO `t_word` (`id`, `word`, `count`) VALUES (NULL, ?, ?)"
// val sql = "INSERT INTO t_word (id, word, count) VALUES (null,?,?) ON DUPLICATE KEY UPDATE count = ?"
val prepareStatement: PreparedStatement = connection.prepareStatement(sql)
// 设置字段
prepareStatement.setString(1, word)
prepareStatement.setInt(2, count)
//prepareStatement.setInt(3, count)
// 执行
prepareStatement.executeUpdate()
}
// 关闭数据库连接
override def close(errorOrNull: Throwable): Unit = {
if (connection != null) {
connection.close()
}
if (preparedStatement != null) {
preparedStatement.close()
}
}
}
}
运行程序
然后在node01的kafka节点上生成一批数据
[root@node01 ~]# /export/servers/kafka_2.11-1.0.0/bin/kafka-console-producer.sh --broker-list node01:9092 --topic demo01
>flink hadoop spark flume spark hive
>spark flink hadoop hive hive
观察IDEA的控制台
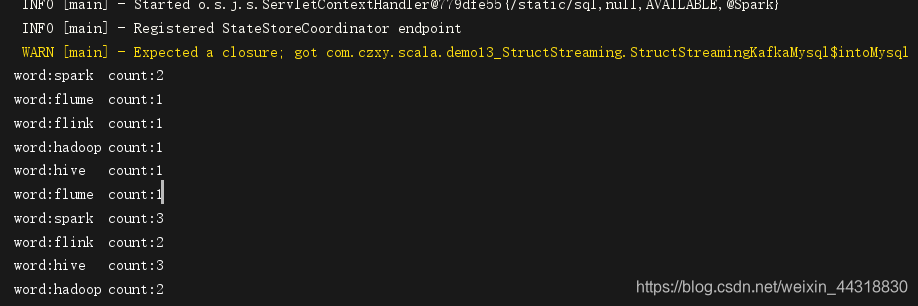
已经对每批次的数据做了一个wordcount
返回到数据库中观察数据
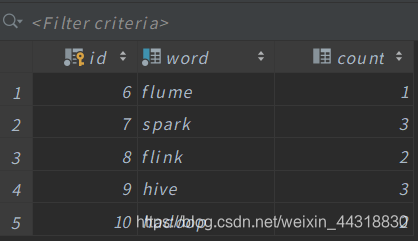
可以发现StructuredStreaming将从Kafka中生产的数据做了处理之后,将计算结果写入到了MySQL中。
当我再生产一批数据
CSDN Alice Hadoop BigData Hadoop
返回更新一下数据库
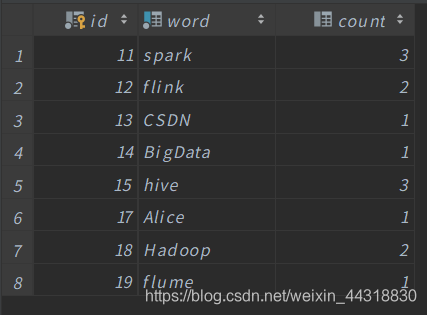
看到类似的效果,说明我们的StructuredStreaming整合MySQL就生效了!
结语
好了,本篇主要为大家带来的就是StructuredStreaming整合Kafka和MySQL的过程,看完了是不是觉得很简单呢( ̄▽ ̄)~*受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波(^U^)ノ~YO

