(范数部分matlab有现成函数,若有需要直接参照matlab_norm )
向量范数
x
∈
R
n
\boldsymbol x\in \boldsymbol R^n
x ∈ R n x ||满足:
∣
∣
x
∣
∣
≥
0
||\boldsymbol x|| \ge 0
∣ ∣ x ∣ ∣ ≥ 0 x =0 ,||x ||=0。任意实数λ
∣
∣
λ
x
∣
∣
=
∣
λ
∣
∣
∣
x
∣
∣
||\lambda\boldsymbol x||=|\lambda|||\boldsymbol x||
∣ ∣ λ x ∣ ∣ = ∣ λ ∣ ∣ ∣ x ∣ ∣
∣
∣
x
+
y
∣
∣
≤
∣
∣
x
∣
∣
+
∣
∣
y
∣
∣
||\boldsymbol{x+y}||\le ||\boldsymbol x||+||\boldsymbol y||
∣ ∣ x + y ∣ ∣ ≤ ∣ ∣ x ∣ ∣ + ∣ ∣ y ∣ ∣
∣
∣
x
∣
∣
1
=
∑
i
=
1
n
∣
x
i
∣
||\boldsymbol x||_1=\sum_{i=1}^n|x_i|
∣ ∣ x ∣ ∣ 1 = i = 1 ∑ n ∣ x i ∣
∣
∣
x
∣
∣
2
=
(
∑
i
=
1
n
x
i
2
)
1
2
||\boldsymbol x||_2=(\sum_{i=1}^nx_i^2)^{\frac{1}{2}}
∣ ∣ x ∣ ∣ 2 = ( i = 1 ∑ n x i 2 ) 2 1
∣
∣
x
∣
∣
∞
=
m
a
x
1
≤
i
≤
n
∣
x
i
∣
||x||_{\infty}=max_{1\le i\le n}|x_i|
∣ ∣ x ∣ ∣ ∞ = m a x 1 ≤ i ≤ n ∣ x i ∣
(
x
1
y
1
+
x
2
y
2
+
.
.
.
+
x
n
y
n
)
2
≤
(
x
1
2
+
x
2
2
+
.
.
.
+
x
n
2
)
(
y
1
2
+
.
.
.
+
y
n
2
)
(x_1y_1+x_2y_2+...+x_ny_n)^2\le (x_1^2+x_2^2+...+x_n^2)(y_1^2+...+y_n^2)
( x 1 y 1 + x 2 y 2 + . . . + x n y n ) 2 ≤ ( x 1 2 + x 2 2 + . . . + x n 2 ) ( y 1 2 + . . . + y n 2 )
∣
∣
x
∣
∣
p
=
(
∑
i
=
1
n
∣
x
i
∣
p
)
1
p
||\boldsymbol x||_p=(\sum_{i=1}^n|x_i|^p)^{\frac{1}{p}}
∣ ∣ x ∣ ∣ p = ( i = 1 ∑ n ∣ x i ∣ p ) p 1 x 无关的正常数c1 c2 分别乘||x ||a 能将||x ||b 夹在中间,称这两种范数等价。以∞-范数为媒介,容易证明有限维上不同范数是等价的。matlab_norm 矩阵范数
∣
∣
A
∣
∣
=
max
x
≠
0
∣
∣
A
x
∣
∣
∣
∣
x
∣
∣
||\boldsymbol A||=\max\limits_{\boldsymbol{x\ne 0}}\frac{||\boldsymbol {Ax}||}{||\boldsymbol x||}
∣ ∣ A ∣ ∣ = x = 0 max ∣ ∣ x ∣ ∣ ∣ ∣ A x ∣ ∣ x 的维度应等于A 的列数,乘出来的向量是维度为A 的行数的列向量,所以维度不一定和分母相同。不好理解的是与矩阵无关的向量x ,只要非0都可选,而且按照确定范数规则能得到统一的最大值。后面证明无穷范数时会理解一些。
∣
∣
A
x
∣
∣
≤
∣
∣
A
∣
∣
∣
∣
x
∣
∣
||\boldsymbol {Ax}||\le ||\boldsymbol A||~||\boldsymbol x||
∣ ∣ A x ∣ ∣ ≤ ∣ ∣ A ∣ ∣ ∣ ∣ x ∣ ∣
∣
∣
A
B
∣
∣
≤
∣
∣
A
∣
∣
∣
∣
B
∣
∣
||\boldsymbol {AB}||\le ||\boldsymbol A||~||\boldsymbol B||
∣ ∣ A B ∣ ∣ ≤ ∣ ∣ A ∣ ∣ ∣ ∣ B ∣ ∣ AB 是同维方阵。此式课本证明有点紊乱,调整如下:
∣
∣
A
B
x
∣
∣
=
∣
∣
A
(
B
x
)
∣
∣
||\boldsymbol{ABx}||=||\boldsymbol{A(Bx)}||
∣ ∣ A B x ∣ ∣ = ∣ ∣ A ( B x ) ∣ ∣ Bx 变成了向量。所以根据相容性条件,
∣
∣
A
B
x
∣
∣
≤
∣
∣
A
∣
∣
∣
∣
B
x
∣
∣
||\boldsymbol{ABx}||\le\boldsymbol{||A||~||Bx}||
∣ ∣ A B x ∣ ∣ ≤ ∣ ∣ A ∣ ∣ ∣ ∣ B x ∣ ∣
∣
∣
A
B
∣
∣
=
max
x
≠
0
∣
∣
A
B
x
∣
∣
∣
∣
x
∣
∣
≤
max
x
≠
0
∣
∣
A
∣
∣
∣
∣
B
x
∣
∣
∣
∣
x
∣
∣
||\boldsymbol {AB}||=\max\limits_{\boldsymbol{x\ne 0}}\frac{||\boldsymbol {ABx}||}{||\boldsymbol x||} \le\max\limits_{\boldsymbol{x\ne 0}}\frac{||\boldsymbol {A||~||Bx}||}{||\boldsymbol x||}
∣ ∣ A B ∣ ∣ = x = 0 max ∣ ∣ x ∣ ∣ ∣ ∣ A B x ∣ ∣ ≤ x = 0 max ∣ ∣ x ∣ ∣ ∣ ∣ A ∣ ∣ ∣ ∣ B x ∣ ∣
∣
∣
A
B
∣
∣
≤
∣
∣
A
∣
∣
max
x
≠
0
∣
∣
B
x
∣
∣
∣
∣
x
∣
∣
=
∣
∣
A
∣
∣
∣
∣
B
∣
∣
||\boldsymbol {AB}||\le||\boldsymbol A||\max\limits_{\boldsymbol{x\ne 0}}\frac{||\boldsymbol {Bx}||}{||\boldsymbol x||}=||\boldsymbol {A||~||B}||
∣ ∣ A B ∣ ∣ ≤ ∣ ∣ A ∣ ∣ x = 0 max ∣ ∣ x ∣ ∣ ∣ ∣ B x ∣ ∣ = ∣ ∣ A ∣ ∣ ∣ ∣ B ∣ ∣
对n 阶方阵A =(aij )n 有
∣
∣
A
∣
∣
∞
=
max
1
≤
i
≤
n
∑
j
=
1
n
∣
a
i
j
∣
||\boldsymbol {A}||_\infty=\max\limits_{1\le i\le n}\sum_{j=1}^n|a_{ij}|
∣ ∣ A ∣ ∣ ∞ = 1 ≤ i ≤ n max j = 1 ∑ n ∣ a i j ∣
∣
∣
A
∣
∣
1
=
max
1
≤
j
≤
n
∑
i
=
1
n
∣
a
i
j
∣
||\boldsymbol {A}||_1=\max\limits_{1\le j\le n}\sum_{i=1}^n|a_{ij}|
∣ ∣ A ∣ ∣ 1 = 1 ≤ j ≤ n max i = 1 ∑ n ∣ a i j ∣
∣
∣
A
∣
∣
2
=
λ
m
a
x
(
A
T
A
)
||\boldsymbol {A}||_2=\sqrt{\lambda_{max}(\boldsymbol{A^TA)}}
∣ ∣ A ∣ ∣ 2 = λ m a x ( A T A )
以上还是比较晦涩的。我解释如下:(注意以上证明的式子只适用于方阵)矩阵范数的难点在找合适的x 向量。注意到在无穷范数定义式
∣
∣
A
∣
∣
∞
=
max
x
≠
0
∣
∣
A
x
∣
∣
∞
∣
∣
x
∣
∣
∞
||\boldsymbol A||_\infty=\max\limits_{\boldsymbol{x\ne 0}}\frac{||\boldsymbol {Ax}||_\infty}{||\boldsymbol x||_\infty}
∣ ∣ A ∣ ∣ ∞ = x = 0 max ∣ ∣ x ∣ ∣ ∞ ∣ ∣ A x ∣ ∣ ∞ x 中的最大量。对于能够使得
∣
∣
A
x
∣
∣
∞
∣
∣
x
∣
∣
∞
\frac{||\boldsymbol {Ax}||_\infty}{||\boldsymbol x||_\infty}
∣ ∣ x ∣ ∣ ∞ ∣ ∣ A x ∣ ∣ ∞
x
=
(
x
1
x
2
x
3
.
.
.
x
n
)
\boldsymbol x=\begin{pmatrix}x_1\\x_2\\x_3\\...\\x_n\end{pmatrix}
x = ⎝ ⎜ ⎜ ⎜ ⎜ ⎛ x 1 x 2 x 3 . . . x n ⎠ ⎟ ⎟ ⎟ ⎟ ⎞
x
k
=
max
0
≤
i
≤
n
∣
x
i
∣
x_k=\max\limits_{0\le i\le n}|x_i|
x k = 0 ≤ i ≤ n max ∣ x i ∣
∣
∣
A
(
x
/
x
k
)
∣
∣
∞
∣
∣
x
/
x
k
∣
∣
∞
\frac{||\boldsymbol {A}(\boldsymbol x/x_k)||_\infty}{||\boldsymbol x/x_k||_\infty}
∣ ∣ x / x k ∣ ∣ ∞ ∣ ∣ A ( x / x k ) ∣ ∣ ∞
x
/
x
k
\textbf x /x_k
x / x k x ,都不妨除以它里面绝对值最大的元素单位化成所有元素的绝对值都在0到1之间的向量。这时就有
∣
∣
A
∣
∣
∞
=
max
∣
∣
x
∣
∣
∞
=
1
∣
∣
Ax
∣
∣
∞
||\textbf A||_\infty=\max\limits_{||\textbf x||_\infty=1}||\textbf {Ax}||_\infty
∣ ∣ A ∣ ∣ ∞ = ∣ ∣ x ∣ ∣ ∞ = 1 max ∣ ∣ Ax ∣ ∣ ∞ A 中所有元素“尽其所能”来达到最大。例如对矩阵
A
=
(
1
−
2
6
2
3
4
−
5
4
3
)
\boldsymbol A = \begin{pmatrix}1&-2&6\\2&3&4\\-5&4&3\end{pmatrix}
A = ⎝ ⎛ 1 2 − 5 − 2 3 4 6 4 3 ⎠ ⎞
(Ax)
i
=
∑
j
=
1
3
a
i
j
x
j
\textbf {(Ax)}_i=\sum_{j=1}^3a_{ij}x_j
(Ax) i = j = 1 ∑ 3 a i j x j A 的第三行,x 取[-1;1;1] (列向量)。最终得到的结果就是
∣
∣
A
∣
∣
∞
=
max
1
≤
i
≤
n
∑
j
=
1
n
∣
a
i
j
∣
=
12
||\boldsymbol {A}||_\infty=\max\limits_{1\le i\le n}\sum_{j=1}^n|a_{ij}|=12
∣ ∣ A ∣ ∣ ∞ = 1 ≤ i ≤ n max j = 1 ∑ n ∣ a i j ∣ = 1 2
高斯-赛德尔迭代法 Ax=b 标量形式写作
∑
j
=
1
n
A
i
j
x
j
=
b
i
,
i
=
1
,
2
,
.
.
.
,
n
\sum_{j=1}^nA_{ij}x_{j}=b_i,i=1,2,...,n
j = 1 ∑ n A i j x j = b i , i = 1 , 2 , . . . , n i 的一项提出来,写作
A
i
i
x
i
+
∑
j
=
1
,
j
≠
i
n
A
i
j
x
j
=
b
i
,
i
=
1
,
2
,
.
.
.
,
n
A_{ii}x_i+\sum_{j=1,j\ne i}^nA_{ij}x_j=b_i,i=1,2,...,n
A i i x i + j = 1 , j = i ∑ n A i j x j = b i , i = 1 , 2 , . . . , n i ,得到
x
i
=
1
A
i
i
(
b
i
−
∑
j
=
1
,
j
≠
i
n
A
i
j
x
j
)
,
i
=
1
,
2
,
.
.
.
,
n
x_i=\frac{1}{A_{ii}}(b_i-\sum_{j=1,j\ne i}^nA_{ij}x_j),i=1,2,...,n
x i = A i i 1 ( b i − j = 1 , j = i ∑ n A i j x j ) , i = 1 , 2 , . . . , n
x
i
←
1
A
i
i
(
b
i
−
∑
j
=
1
,
j
≠
i
n
A
i
j
x
j
)
,
i
=
1
,
2
,
.
.
.
,
n
x_i\leftarrow\frac{1}{A_{ii}}(b_i-\sum_{j=1,j\ne i}^nA_{ij}x_{j}),i=1,2,...,n
x i ← A i i 1 ( b i − j = 1 , j = i ∑ n A i j x j ) , i = 1 , 2 , . . . , n i 的某个新值xi k+1 ,就用新值代替老值做某步剩下的计算。这是它与雅可比迭代法 的区别。在雅可比迭代法中,每一个大步都用上次迭代得到的值。高斯-赛德尔迭代通常效果更好些,但某些情况会出现雅可比迭代法收敛而高斯-赛德尔迭代法发散的情况。首先选取初值x 。如果不知道怎么选好点,就可以随机选。将上式每次得到的结果再代入上式,相邻两次迭代的x 的差距小到一个标准。松弛法加速
x
i
(
k
)
x_i^{(k)}
x i ( k )
x
i
~
(
k
+
1
)
\widetilde{x_i}^{(k+1)}
x i
( k + 1 )
x
i
k
+
1
x_i^{k+1}
x i k + 1
x
i
←
w
A
i
i
(
b
i
−
∑
j
=
1
,
j
≠
i
n
S
i
j
x
j
)
+
(
1
−
w
)
x
i
,
i
=
1
,
2
,
.
.
.
,
n
x_i\leftarrow \frac{w}{A_{ii}}(b_i-\sum_{j=1,j\ne i}^nS_{ij}x_j)+(1-w)x_i,i=1,2,...,n
x i ← A i i w ( b i − j = 1 , j = i ∑ n S i j x j ) + ( 1 − w ) x i , i = 1 , 2 , . . . , n
ω
o
p
t
≈
2
1
+
1
−
(
Δ
x
k
+
p
/
Δ
x
(
k
)
)
1
/
p
\omega_{opt}\approx\frac{2}{1+\sqrt{1-(\Delta x^{k+p}/\Delta x^(k))^{1/p}}}
ω o p t ≈ 1 + 1 − ( Δ x k + p / Δ x ( k ) ) 1 / p
2 (k) 的值;然后依次进行p次迭代,记录最后一次迭代的Δxk+p 的值,最后使用松弛法加速,按照上述松弛因子ω公式最后得出结果。matlab_按元素乘(这里用来求内积) matlab_抛出错误 matlab_输入参数个数nargin 运行句柄函数feval
function [ x, numIteration, omega] = gaussSeidel ( func, x, maxIteration, epsilon)
% 输入的func是迭代函数句柄
% x是初始化的向量,maxIteration是最大允许的迭代次数 ( 默认500 )
% epsilon是允许的误差 ( 默认1.0e-7 )
% 输出的x是解得的值
% numIteration是迭代次数
% omega是松弛因子
if nargin < 4 ; epsilon = 1.0e-7 ; end
if nargin < 3 ; maxIteration = 500 ; end
k = 10 ; p = 1 ; omega = 1 ;
for numIteration = 1 : maxIteration
xOld = x;
x = feval ( func, x, omega) ;
dx = sqrt ( dot ( x - xOld, x - xOld) ) ; % 求两次迭代解的差的内积
if dx < epsilon;
return ; % 退出函数
end
if numIter == k; dx1 = dx; end
if numIter == k + p
omega = 2 / ( 1 + sqrt ( 1 - ( dx/ dx1) ^ ( 1 / p) ) ) ;
end
end
error ( '迭代次数超要求' )
当然,基础的写法是
function [ x] = gaussSeidelBasic ( func, x)
dx= 1 ;
while dx > 1.0e-7
xOld = x; x = feval ( func, x) ;
dx = sqrt ( dot ( x - xOld, x - xOld) ) ;
end
例如,解以前描述过的以三对角矩阵为系数矩阵的方程
(
−
2
1
0
0
.
.
.
0
0
0
1
−
1
2
−
1
0
.
.
.
0
0
0
0
0
−
1
2
−
1
.
.
.
0
0
0
0
.
.
.
0
0
0
0
.
.
.
−
1
2
−
1
0
0
0
0
0
.
.
.
0
−
1
2
−
1
1
0
0
0
.
.
.
0
0
−
1
2
)
(
x
1
x
2
.
.
.
.
.
.
.
.
.
.
.
x
n
)
=
(
0
0
0
0
0
.
.
1
)
\begin{pmatrix}-2&1&0&0&...&0&0&0&1\\-1&2&-1&0&...&0&0&0&0\\0&-1&2&-1&...&0&0&0&0\\...\\0&0&0&0&...&-1&2&-1&0\\0&0&0&0&...&0&-1&2&-1\\1&0&0&0&...&0&0&-1&2\end{pmatrix}\begin{pmatrix}x_1\\x_2\\...\\...\\...\\..\\x_n\end{pmatrix}=\begin{pmatrix}0\\0\\0\\0\\0\\..\\1\end{pmatrix}
⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ − 2 − 1 0 . . . 0 0 1 1 2 − 1 0 0 0 0 − 1 2 0 0 0 0 0 − 1 0 0 0 . . . . . . . . . . . . . . . . . . 0 0 0 − 1 0 0 0 0 0 2 − 1 0 0 0 0 − 1 2 − 1 1 0 0 0 − 1 2 ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ x 1 x 2 . . . . . . . . . . . x n ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ = ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ 0 0 0 0 0 . . 1 ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞
x
i
=
1
A
i
i
(
b
i
−
∑
j
=
1
,
j
≠
i
n
A
i
j
x
j
)
,
i
=
1
,
2
,
.
.
.
,
n
x_i=\frac{1}{A_{ii}}(b_i-\sum_{j=1,j\ne i}^nA_{ij}x_j),i=1,2,...,n
x i = A i i 1 ( b i − j = 1 , j = i ∑ n A i j x j ) , i = 1 , 2 , . . . , n
function x = functionSol ( x, omega)
% 为上述方程书写迭代函数
n = length ( x) ;
x ( 1 ) = omega* ( x ( 2 ) - x ( n) ) / 2 + ( 1 - omega) * x ( 1 ) ;
for i = 2 : n- 1
x ( i) = omega* ( x ( i- 1 ) + x ( i+ 1 ) ) / 2 + ( 1 - omega) * x ( i) ;
end
x ( n) = omega * ( 1 - x ( 1 ) + x ( n- 1 ) ) / 2 + ( 1 - omega) * x ( n) ;
在命令行中书写
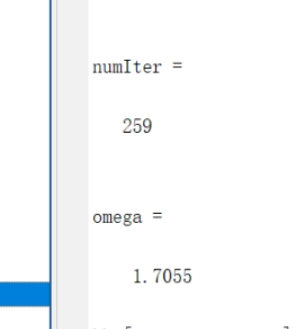
[ x, numIter, omega] = gaussSeidel ( @functionSol, zeros ( 20 , 1 ) )
算得结果
这里精确到1.0e-9,迭代了259次。
function x = functionSol ( x)
% 为上述方程书写迭代函数
n = length ( x) ;
x ( 1 ) = ( x ( 2 ) - x ( n) ) / 2 ;
for i = 2 : n- 1
x ( i) = ( x ( i- 1 ) + x ( i+ 1 ) ) / 2 ;
end
x ( n) = ( 1 - x ( 1 ) + x ( n- 1 ) ) / 2 ;
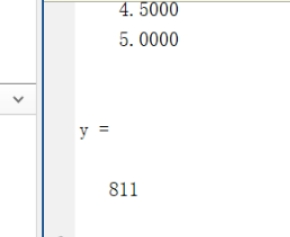
在那个简单写法里加个计数器,在命令行里输入
[ x, y] = gaussSeidelBasic ( @functionSol, zeros ( 20 , 1 ) )
迭代公式的矩阵表示
迭代原理:已知
Ax=b
\textbf{Ax=b}
Ax=b
x=Bx+f
\textbf{x=Bx+f}
x=Bx+f
x
k
+
1
=
Bx
k
+
f
,
k
=
0
,
1
,
.
.
.
\textbf{x}^{k+1}=\textbf {Bx}^k+\textbf f,k=0,1,...
x k + 1 = Bx k + f , k = 0 , 1 , . . . x 收敛于x *
lim
k
→
+
∞
x
(
k
)
=
x
∗
\lim_{k\rightarrow +\infty}\boldsymbol x^{(k)}=\boldsymbol x^*
k → + ∞ lim x ( k ) = x ∗ x *就是解。对于一般的线性方程组,将系数矩阵分解成
A
=
−
L
+
D
+
U
\boldsymbol{A=-L+D+U}
A = − L + D + U
x
i
=
1
A
i
i
(
b
i
−
∑
j
=
1
,
j
≠
i
n
A
i
j
x
j
)
,
i
=
1
,
2
,
.
.
.
,
n
x_i=\frac{1}{A_{ii}}(b_i-\sum_{j=1,j\ne i}^nA_{ij}x_j),i=1,2,...,n
x i = A i i 1 ( b i − j = 1 , j = i ∑ n A i j x j ) , i = 1 , 2 , . . . , n
x
(
k
+
1
)
=
D
−
1
(
b
+
L
x
(
k
+
1
)
+
U
x
k
)
\boldsymbol x^{(k+1)}=\boldsymbol D^{-1}(\boldsymbol b+ \boldsymbol {Lx}^{(k+1)}+\boldsymbol {Ux}^k)
x ( k + 1 ) = D − 1 ( b + L x ( k + 1 ) + U x k ) (k+1) 的项移到一起,得到
x
k
+
1
=
Bx
k
+
f
,
k
=
0
,
1
,
.
.
.
\textbf{x}^{k+1}=\textbf {Bx}^k+\textbf f,k=0,1,...
x k + 1 = Bx k + f , k = 0 , 1 , . . .
b
=
(
D
−
L
)
−
1
U
\boldsymbol {b=(D-L)}^{-1}\boldsymbol U
b = ( D − L ) − 1 U
f
=
(
D
−
L
)
−
1
b
\boldsymbol {f=(D-L)}^{-1}\boldsymbol b
f = ( D − L ) − 1 b 共轭梯度法
f
(
x
)
=
1
2
x
T
A
x
−
b
T
x
f(x)=\frac{1}{2}x^TAx-b^Tx
f ( x ) = 2 1 x T A x − b T x
A
x
=
b
Ax=b
A x = b
function [ x, numIter] = conjGrad ( func, x, b, epsilon)
% func = handle of function that returns the vector A* v
% x = 初始化解向量
% b = constant vector in A* x = b
% epsilon = 最大误差 ( 默认1.0e-9 )
% x 输出的解
% numIter 执行迭代的次数
if nargin == 3 ; epsilon = 1.0e-9 ; end
n = length ( b) ;
r = b - feval ( func, x) ; s = r;
for numIter = 1 : n
u = feval ( func, s) ;
alpha = dot ( s, r) / dot ( s, u) ;
x = x + alpha* s;
r = b - feval ( func, x) ;
if sqrt ( dot ( r, r) ) < epsilon
return
else
beta = - dot ( r, u) / dot ( s, u) ;
s = r + beta* s;
end
end
error ( 'Too many iterations' )
仍然举高斯-赛德尔迭代法中的例子
(
−
2
1
0
0
.
.
.
0
0
0
1
−
1
2
−
1
0
.
.
.
0
0
0
0
0
−
1
2
−
1
.
.
.
0
0
0
0
.
.
.
0
0
0
0
.
.
.
−
1
2
−
1
0
0
0
0
0
.
.
.
0
−
1
2
−
1
1
0
0
0
.
.
.
0
0
−
1
2
)
(
x
1
x
2
.
.
.
.
.
.
.
.
.
.
.
x
n
)
=
(
0
0
0
0
0
.
.
1
)
\begin{pmatrix}-2&1&0&0&...&0&0&0&1\\-1&2&-1&0&...&0&0&0&0\\0&-1&2&-1&...&0&0&0&0\\...\\0&0&0&0&...&-1&2&-1&0\\0&0&0&0&...&0&-1&2&-1\\1&0&0&0&...&0&0&-1&2\end{pmatrix}\begin{pmatrix}x_1\\x_2\\...\\...\\...\\..\\x_n\end{pmatrix}=\begin{pmatrix}0\\0\\0\\0\\0\\..\\1\end{pmatrix}
⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ − 2 − 1 0 . . . 0 0 1 1 2 − 1 0 0 0 0 − 1 2 0 0 0 0 0 − 1 0 0 0 . . . . . . . . . . . . . . . . . . 0 0 0 − 1 0 0 0 0 0 2 − 1 0 0 0 0 − 1 2 − 1 1 0 0 0 − 1 2 ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ x 1 x 2 . . . . . . . . . . . x n ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ = ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ 0 0 0 0 0 . . 1 ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞
function Av = functionSol ( v)
n = length ( v) ;
Av = zeros ( n, 1 ) ;
Av ( 1 ) = 2 * v ( 1 ) - v ( 2 ) + v ( n) ;
Av ( 2 : n- 1 ) = - v ( 1 : n- 2 ) + 2 * v ( 2 : n- 1 ) - v ( 3 : n) ;
Av ( n) = - v ( n- 1 ) + 2 * v ( n) + v ( 1 ) ;
在命令行中输入
[ x, numIter] = conjGrad ( @functionSol, x, b)
得到