文章目录
正则表达式:
正则表达式就是一些用来匹配和处理文本的字符串,其可以看作是内嵌在其他语言里的“迷你”语言
正则表达式的用途
1、查找特定的信息(搜索);
2、查找并编辑特定的信息(替换)
可以认为正则表达式表述了一个字符串的书写规则,判断用户输入的密码是否合法,判断用户输入的邮箱正则表达式的匹配是按照每个位置的字符进行判断验证的
正则表达式的组成-元字符
正则表达式就是由普通字符以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串
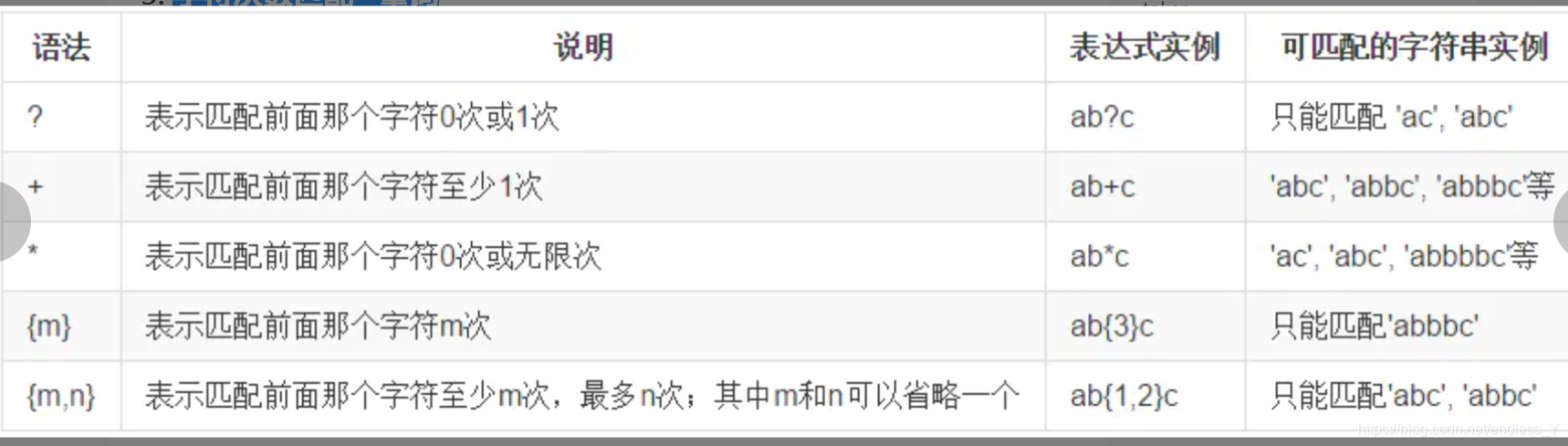
字符次数匹配–量词
在正则表达式中,我们还可以指定匹配某个字符出现次数
说明: {m,n}中的m和n可以省略其中一个,{,n}相当于{0,n},{m,}相当于{m,整数最大值}。
我们可以得出以下结论:
{0,1}或{,1} 等价于 ?
{1,} 等价于 +
{0,} 等价于 *
我们优先选择使用 ?, + 和 *,因为他们书写简单,也可以使整个正则表达式变得简洁。
说明: ? 这个字符在正则表达中与 ?, +, *, {m,n}连用时还有一个额外的功能,就是将匹配模式由贪婪模式(尽可能的增加匹配次数) 变成 非贪婪模式(尽可能减少匹配次数), 这个会在下面的内容中进行详细说明。
单个字符匹配
说明: 所有的特殊字符在[ ]内都将失去其原有的特殊含义:
有些特殊字符在[ ]中被赋予新的特殊含义,如 ‘^‘出现在[ ]中的开始位置表示取反,它出现在[]中的其他位置表示其本身(变成了一个普通字符);
有些特殊字符则变为普通字符,如 ‘.’, ‘*’, ‘+’, ‘?’, ‘$’
有的普通字符变为特殊字符,如 ‘-’ 在[ ]中的位置不是第一个字符则表示一个数字或字母区间,如果在[ ]中的位置是第一个字符则表示其本身(一个普通字符)
在[ ]中,如果要使用’-’, ‘^’ 或’]’,可在在它们前面加上反斜杠,或把’-’, ']‘放在第一个字符的 位置,把’^'放在非第一个字符的位置。

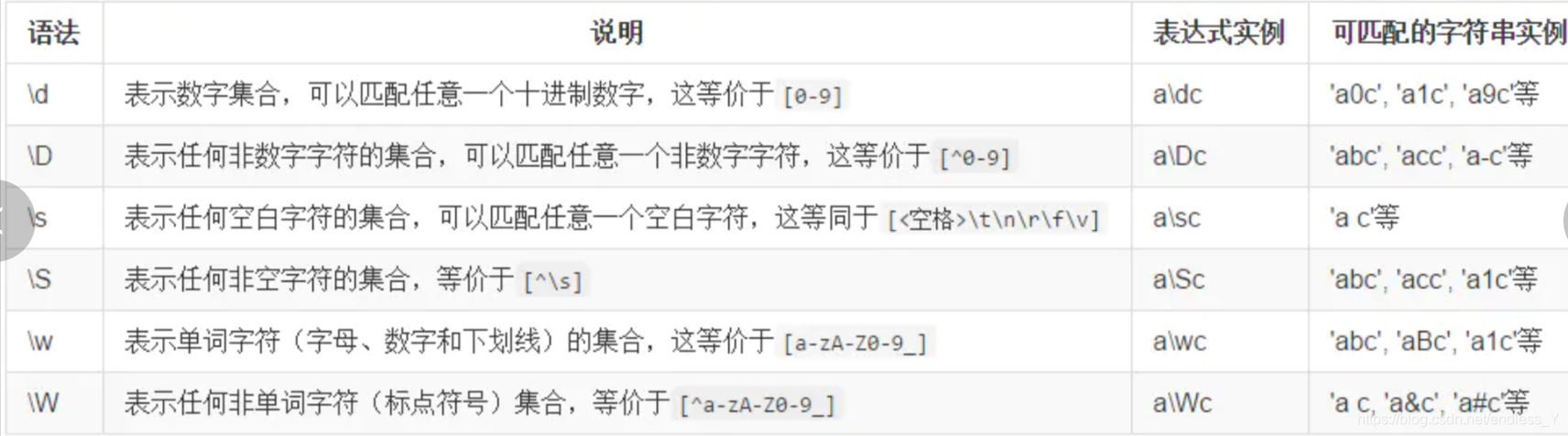
预定义字符集
我们可以在反斜杠后面跟上一个指定的字母来表示预定义的字符集合
正则表达式的特点
- 灵活性、逻辑性和功能性非常的强;
- 可以迅速低用极简单的方式达到字符串的复杂控制;
- 对于刚接触的人来说,比较晦涩难懂。
正则表达式中的标志位-flag
上面提到的贪婪模式与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,而这里所说的标志位将会影响正则表达式的整体工作方式。不同编程语言中通常都会有预设的常量值来表示这些标志位,大家在用到时自己查下文档既可以。常用的标志位如下:

JavaScript中的正则表达式解析
<script lang ge="java script">
//去左空格;
function ltrim(s){
return s.replace( /^\\s*/, "");
}
//去右空格;
function rtrim(s){
return s.replace( /\\s*$/, "");
}
//去左右空格;
function trim(s){
return rtrim(ltrim(s));
}
//是否为空值;
function IsEmpty(_str){
var tmp_str = trim(_str);
return tmp_str.length == 0;
}
//是否有效的Email;
function IsMail(_str){
var tmp_str = trim(_str);
var pattern = /^[_a-z0-9-]+(.[_a-z0-9-]+)*@[a-z0-9-]+(.[a-z0-9-]+)*$/;
return pattern.test(tmp_str);
}
HTML代码的屏蔽
function mask_HTMLCode(strInput) {
var myReg = /<(\w+)>/;
return strInput.replace(myReg, "<$1>");
}
/*验证是否是中文*/
function IsChinese(str)
{
var pattern=/^[\?-\龥]+$/;
if(!pattern.test(str))
{return false;}
return tr;
}
//是否有效的数字;
function IsNumber(_str){
var tmp_str = trim(_str);
var pattern = /^[0-9]/;
return pattern.test(tmp_str);
}
//是否有效的颜色值;
function IsColor(color){
var temp=color;
if (temp=="") return tr;
if (temp.length!=7) return false;
return (temp.search(/\\#[a-fA-F0-9]{6}/) != -1);
}
//是否有效的链接;
function IsURL(url){
var sTemp;
var b=tr;
sTemp=url.s string(0,7);
sTemp=sTemp.toUpperCase();
if ((sTemp!="http://") target="_blank" ... #124;|(url.length<10)){
b=false;
}
return b;
}
//是否有效的手机号码;
function IsMobile(_str){
var tmp_str = trim(_str);
var pattern = /13\\d{9}/;
return pattern.test(tmp_str);
}
</script>
RegExp
RegExp 是正则表达式的缩写。
当您检索某个文本时,可以使用一种模式来描述要检索的内容。RegExp 就是这种模式。
简单的模式可以是一个单独的字符。
更复杂的模式包括了更多的字符,并可用于解析、格式检查、替换等等。
您可以规定字符串中的检索位置,以及要检索的字符类型,等等。
定义 RegExp
RegExp 对象用于存储检索模式。
通过 new 关键词来定义 RegExp 对象。以下代码定义了名为 patt1 的 RegExp 对象。
var patt1=new RegExp(pattern, attributes);;
参数 pattern 是一个字符串,指定了正则表达式的模式或其他正则表达式。
参数 attributes 是一个可选的字符串,包含属性 “g”、“i” 和 “m”,分别用于指定全局匹配、区分大小写的匹配和多行匹配。ECMAScript 标准化之前,不支持 m 属性。如果 pattern 是正则表达式,而不是字符串,则必须省略该参数。
语法
/正则表达式主体/修饰符(可选)
var patt = /runoob/i
RegExp 对象有 3 个方法:
1.test() 方法检索字符串中的指定值。返回值是 true 或 false。
2.exec() 方法检索字符串中的指定值。返回值是被找到的值。如果没有发现匹配,则返回 null。
3.compile() 既可以改变检索模式,也可以添加或删除第二个参数。
Regex类

重复操作与后向引用
当对组使用重复操作符时,缓存里后向引用内容会被不断刷新,只保留最后匹配的内容。
例
正则表达式([abc]+)=\1
可以匹配文本cab=cab
但正则表达式([abc])+=\1不会匹配文本cab=cab
因为
([abc])第一次匹配文本c时,\1已经代表的是c
([abc])继续匹配到了文本a \1已经代表的是a
([abc])继续匹配到了文本b 最后\1已经代表的是b
所以正则表达式([abc])+=\1只会匹配到文本cab=b
应用:检查重复单词
当编辑文字时,很容易就会输入重复单词如the the
使用 \b(\w+)\s+\1\b可以检测到这些重复单词。
要删除第二个单词,只要简单的利用替换功能替换掉“\1”即可
正则表达式的匹配模式
正则表达式引擎都支持三种匹配模式
/i 使正则表达式对大小写不敏感
/s 开启“单行模式”,即点号.匹配换行符(nweline)
/m 开启“多行模式”,即^和$匹配换行符(nweline)的前面和后面的位置。
在正则表达式内部打开或关闭模式
如果你在正则表达式内部插入修饰符(?ism)
则该修饰符只对其右边的正则表达式起作用。 (?-i)是关闭大小写不敏感。你可以很快的进行测试。
(?i)te(?-i)st应该匹配 TEst,但不能匹配 teST 或 TEST
怎么用正则表达式表达邮箱
我们只需要根据正则表达式的规则组合就可以了。
比如说:
26个大小写英文字母表示为a-zA-Z
数字表示为0-9
下划线表示为_
中划线表示为-
由于名称是由若干个字母、数字、下划线和中划线组成,所以需要用到+表示多次出现
根据以上条件得出邮件名称表达式:[a-zA-Z0-9_-]+
一般域名的规律为
“[N级域名][三级域名.]二级域名.顶级域名”
比如:
“qq.com”、“www.qq.com”、“mp.weixin.qq.com”、“12-34.com.cn”,分析可得域名类似
**
.**
.** .**
组成。
“ * ” 部分可以表示为[a-zA-Z0-9_-]+
" .** " 部分可以表示为.[a-zA-Z0-9_-]+
“.** .** ” 可以表示为(.[a-zA-Z0-9_-]+)+
综上所述,域名部分可以表示为[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+
最终表达式:
由于邮箱的基本格式为“名称@域名”,需要使用“^”匹配邮箱的开始部分
用$匹配邮箱结束部分以保证邮箱前后不能有其他字符,所以最终邮箱的正则表达式为:
`^[a-zA-Z0-9_-]+`@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
然后具体使用的时候可以用string的matches方法来判断字符串是否匹配正则
例:
String name = "12345678";
Boolean ntrue =name.matches("^[A-Za-z0-9]{3,16}$"))
返回的是boolean类型。
正则表达式对象的方法
方法含义
compile正则表达式比较
exec执行查找
test进行匹配
toSource返回特定对象的定义(literal representing),其值可用来创建一个新的对象。重载Object.toSource方法得到的。
toString返回特定对象的串。重载Object.toString方法得到的。
valOf返回特定对象的原始值。重载Object.valOf方法得到
常用匹配
"^-[0-9]*[1-9][0-9]*$" //负整数
"^-?\\d+$" //整数
"^\\d+([url=file://\\.\\d+)?$]\\.\\d+)?$[/url]" //非负浮点数(正浮点数 + 0)
"^(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数
"^((-\\d+([url=file://\\.\\d+)?)|(0+(\\.0+)?))$]\\.\\d+)?)|(0+(\\.0+)?))$[/url]" //非正浮点数(负浮点数 + 0)
"^(-(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数
"^(-?\\d+)([url=file://\\.\\d+)?$]\\.\\d+)?$[/url]" //浮点数
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^\\w+$" //由数字、26个英文字母或者下划线组成的字符串
"^[\\w-]+([url=file://\\.[\\w-]+)*@[\\w-]+(\\.[\\w-]+)+$]\\.[\\w-]+)*@[\\w-]+(\\.[\\w-]+)+$[/url]" //email地址
"^[a-zA-z]+://([url=file://\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$]\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$[/url]" //url
应用实例
// 用户名:
"/^[a-zA-Z]{1}([a-zA-Z0-9]|[_]){4,19}$/"
// 无符号字符串:
"/^[^\s]{1}[^-_\~!@#\$%\^&\*\.\(\)\[\]\{\}<>\?\\\/\'\"]*$/"
// Email:
"/^\w+([-+.]\w+)*@\w+([-.]\\w+)*\.\w+([-.]\w+)*$/"
// 电话号码:
"/^((\(\d{3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9]\d{6,7}$/"
// 手机号码:
"/^((\(\d{3}\))|(\d{3}\-))?13\d{9}$/"
// URL:
"/^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$/"
// 身份证:
"/^\d{15}(\d{2}[A-Za-z0-9])?$/"
// 货币:
"/^\d+(\.\d+)?$/"
// 货币:
"/^\-\d+(\.\d+)*?$/"
// 数字:
"/^\d+$/"
// 邮政编码:
"/^[1-9]\d{5}$/"
// QQ:
"/^[1-9]\d{4,8}$/"
// 整数:
"/^[-\+]?\d+$/"
// 实数:
"/^[-\+]?\d+(\.\d+)?$/"
// 英文:
"/^[A-Za-z]+$/"
// 中文
"/^[\Α-\¥]+$/"
// 密码(必须含有大写字母、小写字母、标点、数字中的至少两种。呵呵,这个比较变态吧~)
"/^(([A-Z]*|[a-z]*|\d*|[-_\~!@#\$%\^&\*\.\(\)\[\]\{\}<>\?\\\/\'\"]*)|.{0,5})$|\s/"
利用正则表达式限制网页表单里的文本框输入内容:
<!-- 用正则表达式限制只能输入数字和英文 -->
<input οnkeyup="value=value.replace(/[/W]/g,'')"
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/d]/g,''))"id="text1" name="text1"> )"
<!-- 用正则表达式限制只能输入数字 -->
<input οnkeyup="value=value.replace(/[^/d]/g,'') "
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/d]/g,''))"id="text2" name="text2">
<!-- 用正则表达式限制只能输入全角字符 -->
<input οnkeyup="value=value.replace(/[^/uFF00-/uFFFF]/g,'')"
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/uFF00-/uFFFF]/g,''))"
id="text3" name="text3">
<!-- 用正则表达式限制只能输入中文 -->
<input οnkeyup="value=value.replace(/[^/u4E00-/u9FA5]/g,'')"
onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/u4E00-/u9FA5]/g,''))"
id="text4" name="text4">
