由问题驱动思考,由目标驱动前进的动力。
为什么函数调用时会需要栈这种数据结构?
栈结构图:
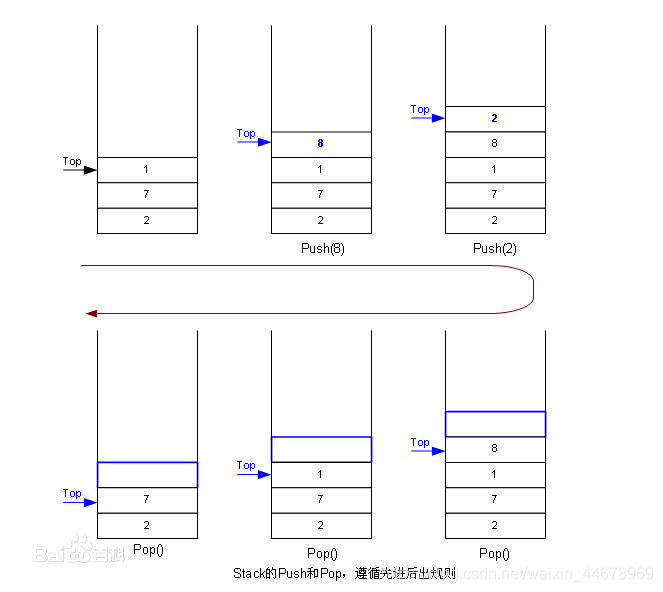 特点是: 先进后出(FILO),就像打手枪一样当然得排除左轮这种,例如毛瑟手枪。装弹的时候,先装的最后才打出来。
特点是: 先进后出(FILO),就像打手枪一样当然得排除左轮这种,例如毛瑟手枪。装弹的时候,先装的最后才打出来。
前面一篇博客中写到了指令跳转,我们知道了 if…else 的指令跳转是跳到某个地方就在那里执行,直到结束也不会跳回到当初的跳转点。
而在函数调用的时候恰恰相反,会跳转到当初的跳转点然后向下依次执行。
那问题来了,有什么办法能让指令跳转回当初的跳转点呢?就拿这个函数举例:
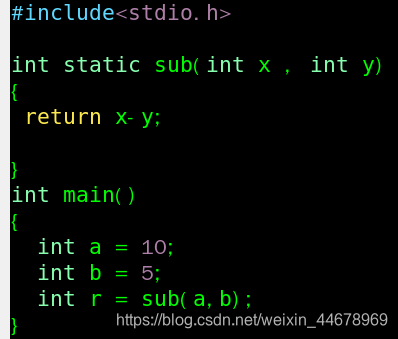
方法1: 直接将 sub 函数的语句放置到 main 中调用部分,这样岂不是不用跳转指令,而且也能减少 cpu 的指令数了? 性能也会相应的提高。但,如果在 sub 函数中在调用 别的函数,依次递归下去,后果可想而知。
方法 2: 利用寄存器,将需要返回的地址记录下来。这样是可以解决,但如果有太多的指令地址需要存下来,那针对于 Intel i7 CPU 只有16个64位寄存器,调用的层数一多就存不下了。
主角登场-- 栈 , 这种数据结构很好的解决了以上两个方法的不足点。
栈的大小是动态生成的,在程序中会分配栈底的地址然后依次向上递减,所以在程序中栈是倒过来的,即栈底在上面,栈顶在下面。
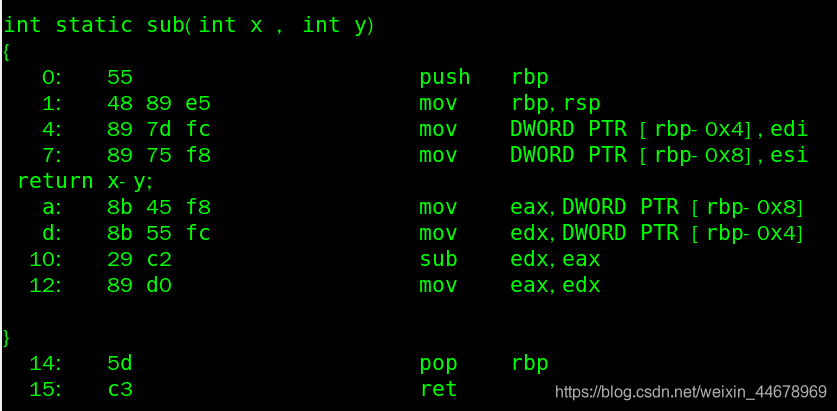
在 Linux中对上面函数进行反汇编:
 关键字解释:
关键字解释:
每个函数都有自己的一个栈。
push 入栈 (给枪上子弹) , pop(出栈,打枪) , rbp: 栈帧指针(把调用者的栈底地址压到栈顶) , rsp : 栈顶指针(始终指向栈顶)
mov rbp rsp (即将指向栈底的 rbp 跟随 rsp 指向栈顶)
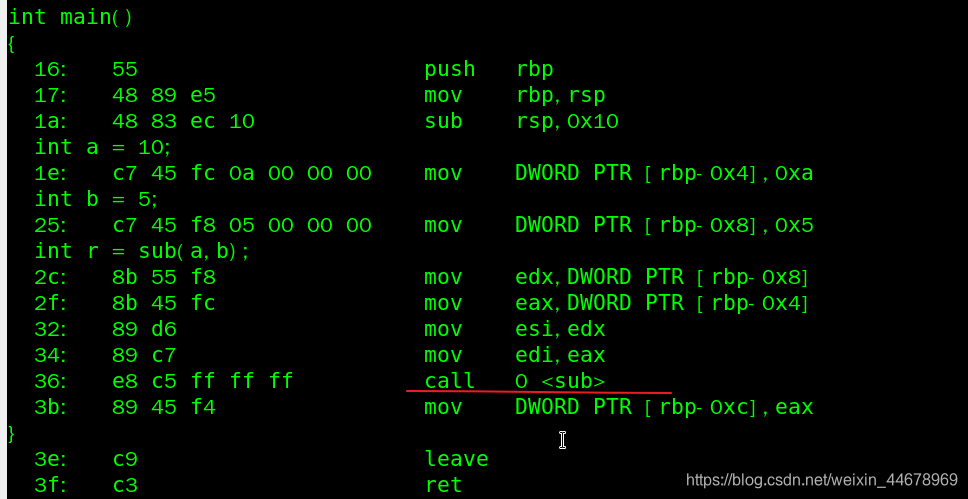
先从 main 看:
main 给自己创建一个栈,将rbp , rsp 入栈,并加入相关的局部变量:
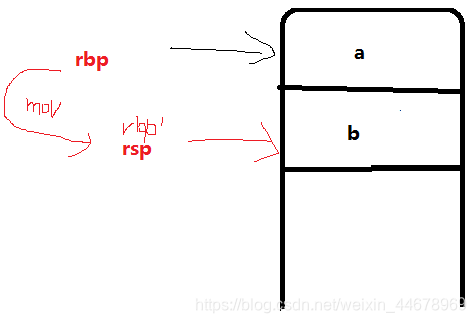
直到 call 发生指令跳转,跳转到 sub 函数的入口,同样的道理也会创建一个栈将有关变量压入。最后将结果 pop() 出来 ret 返回到 main , 继续执行main函数剩余的部分。
什么情况会发生 Stack overflow :
即递归调用,向下面这个函数一样:
public void show()
{
show();
}
性能调优: (空间换时间)
当调用的层次很少的时候,就可执行上面 方法1 的想法。这样会减少 cpu 的指令数,但内存的消耗会加重。
在用 gcc 编译时需要加参数 -O 让程序自动优化:
gcc -g -c -O test.c
objdump -d -M intel -S test.o
总结: 了解程序栈一个概念,以及在函数调用中它起到的作用。
