前言
第一次尝试实现论文,以此记录自己的学习过程,加油鸭!
题目:Computerized Lung Sound Screening for Pediatric Auscultation in Noisy Field Environments 第三部分_信号增强
时间:2020.1.2-1.10
具体:
- A.针对失真音频信号,采用“三样条插值法”修复。
- C.针对心音信号的干扰,采用小波多尺度分解的方法,进行心音识别和心音替换,达到抑制心音信号的目的。
- D.针对哭声,采用径向量基的SVM分类器,将哭声和其他浊音区分开。
关键点:
- 三次样条插值法
- Butterworth滤波器(4阶、带通、50-250hz)
- Symlet分解滤波器(3层)-信号重构
- ARMA模型替换:1、多尺度积值大的部分(认为是心音)2、X(n)数据缺失的部分
- SVM分类器




三次样条插值
理论
三次样条插值是对于一个区间(a,b),将区间分成n-1个区间,通过已知的n+1个点来模拟未知的函数。
性质:
1.三次样条曲线在衔接点处是连续光滑的
2.三次样条的一阶导数和二阶导数是连续的
3.自由边界三次样条(Nature Cubic Spline)的边界二阶导数也是连续的
4.单个点并不会影响到整个插值曲线
三次样条插值的公式推导(端点条件:自由边界)

实验
程序步骤:
- 计算点与点之间的步长

- x,y 端点值带入矩阵方程,求解c(m向量)

- 计算系数
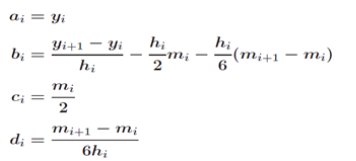
- 每个子区间内的样条函数值yy
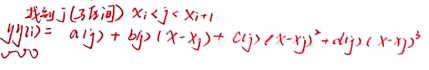
示例

%%失真函数
clear all; clc; close all;
x=-4*pi:0.01*pi:4*pi;
y=2*sin(x)+sin(2*x);
k1=( y>=2 ) ;k2=( y<=-2 );kk=(k1+k2); %失真点的位置
y(k1)=2 ;y(k2)=-2;
plot(x,y,'k-')
hold on;
axis([-15, 15, -3, 3]) %定义显示的坐标区间:x在(-15,15)之间,y在(-3,3)之间
grid on;
title('2sin(x)+sin(2x)'); xlabel('x'); ylabel('y');
%% 去掉失真点后的样本点xi和yi
xi=x;
yi=y;
j = find(kk==1);
xi(j)=[];
yi(j)=[];
%% 三次样条插值法
xx=-4*pi:0.01*pi:4*pi;
yy= Interpolation_Spline0(xi, yi, xx);
plot(xx,yy,'r--');
axis([-15, 15, -3, 3]) %定义显示的坐标区间:x在(-15,15)之间,y在(-3,3)之间
grid on;
title('三次多项式插值')
function yy = Interpolation_Spline0(x, y, xx)
%{
函数功能:三次样条插值法;
输入:
x:已知点横坐标;
y:已知点纵坐标;
xx:插值点;
输出:
yy:插值点的函数值;
%}
% = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = =
n = length(x);
a = y(1 : end - 1);
b = zeros(n - 1, 1);
d = zeros(n - 1, 1);
dx = diff(x);
dy = diff(y);
A = zeros(n);
B = zeros(n, 1);
A(1, 1) = 1;
A(n, n) = 1;
for i = 2 : n - 1
A(i, i - 1) = dx(i - 1);
A(i, i) = 2*(dx(i - 1) + dx(i));
A(i, i + 1) = dx(i);
B(i) = 3*(dy(i) / dx(i) - dy(i - 1) / dx(i - 1));
end
c = A \ B;%解
for i = 1 : n - 1
d(i) = (c(i + 1) - c(i)) / (3 * dx(i));
b(i) = dy(i) / dx(i) - dx(i)*(2*c(i) + c(i + 1)) / 3;
end
[mm, nn] = size(xx);
yy = zeros(mm, nn);
for i = 1 : mm*nn
for ii = 1 : n - 1
if xx(i) >= x(ii) && xx(i) <x(ii +1)
j = ii;
break;
elseif xx(i) == x(n)
j = n - 1;
end
end %找到对应到插值点 j
yy(i) = a(j) + b(j)*(xx(i) - x(j)) + c(j)*(xx(i) - x(j))^2 + d(j)*(xx(i) - x(j))^3;
end
感谢:https://www.cnblogs.com/ondaytobewhoyouwant/p/8989497.html
小波变换
理论
1.小波基的选取
在心音分析中,采用了symletsA小波系作为小波基,其形状如下,适合心音波形。

2.小波去噪
有三种方法:默认阈值去噪处理、给定阈值去噪处理、强制去噪处理。

实验
- 使用小波变换工具箱
(1)小波分解
导入,设置选用的小波基函数和层次(sym6、3)

(2)去噪
固定阈值、软阈值

- 采用MATLAB中函数
用相关函数分别实现了小波分解、信号重构、软阈值去噪、硬阈值去噪,结果图如下。

代码如下:
%小波分解
[c,l]=wavedec(Y,3,'sym3'); %小波分解,3代表分解3层,'sym3'
%重构
a3=appcoef(c,l,'sym3',3);%提取低频小波系数
d3=detcoef(c,l,3);%提取高频小波系数
d2=detcoef(c,l,2);%提取高频小波系数
d1=detcoef(c,l,1);%提取高频小波系数
dd3=zeros(1,length(d3));
dd2=zeros(1,length(d2));
dd1=zeros(1,length(d1));
c1=[a3' dd3 dd2 dd1];
s1=waverec(c1,l,'sym3');
%小波去噪
[thr,sorh,keepapp] = ddencmp('den','wv',Y);%ddencmp生成去噪默认阈值 den去噪,wv小波
denoisexs = wdencmp('gbl',Y,'sym3',3,thr,'s',keepapp);
denoisexh = wdencmp('gbl',Y,'sym3',3,thr,'h',keepapp);
audiowrite('01-3denoisexh.wav',denoisexh,fs);
subplot(511);plot(Y);
title('原始信号');
subplot(512);plot(x);
title('无噪声信号')
subplot(513);plot(a3);
title('重构信号(仅节点3-0)')%幅值明显低于原始信号
subplot(514);plot(denoisexs);
title('软阈值去噪信号');
subplot(515);plot(denoisexh);
title('硬阈值去噪信号');
小波包树:

说明:
左图 小波包树图
小波包是从原始信号,分级向下分解。
节点0.0 1.0 1.1 2.0 2.1…,对应顺序1.2.3.4.5…
每个节点对应的小波包系数 表示频率大小(可以点节点,显示相应波形)
右图 小波时间频率图
x轴 有1024个点 每个点为1/1024s 整个为1s(0:1/1024:1)
y轴 有8段 分别对应小波树的最后一层
采样频率是1024Hz,根据采样定理,奈奎斯特采样频率是512Hz
最后一层的频率区间是 512/8=64Hz
颜色重的 8(65Hz-128Hz)和13(257Hz-320Hz)
为什么是有颜色的地方是竖线:由于原始信号的频率在整个1秒钟内都没有改变
端点检测
理论
语音的端点检测是指从包含语音的一段信号中确定出语音的起始点和结束点位置。
方法:双门限法、相关法、方差法、谱距离法、小波变换法等。这次主要学习了双门限法端点检测。
双门限法是基于短时平均能量和短时平均过零率,采用二级判决。
步骤:
1.基于短时能量的第一级判决
(1)在短时平均能量包络线上选取一个较高的阈值(T2),阈值与短时能量包络线的交点(C、D)之间,肯定为语音。
(2)再在短时平均能量包络线上选取一个较低的阈值(T1),交点为(B、E),BE段就是根据短时能量判定的语音段起止点位置。
2.基于短时平均过零率的第二级判决
在短时平均过零率包络线上选取一个阈值(T3),BE向左向右搜索取到交点(A、F),则AF段,是双门限法判定的语音段。
实验
根据心音信号,选定T1 T2 T3的值,以及minlen(最短语音时间)和maxsilence(最长静音时间),端点检测结果如下。

说明:
图中:实线为心音起始点,虚线为心音结束点
命令行:返回值依次为,第n段心音、起始点对应的帧数、终止点对应的帧数、本段心音持续帧数。
端点检测代码
流程图:

function [voiceseg,vsl,SF,NF]=vad_ezm1(x,wlen,inc,NIS,maxsilence,minlen)
%功能:端点检测(不适用于中等或较小信噪比情况 )
%输入:语音信号(x)、帧长(wlen)、帧移(inc)、前导无话段的帧数(NIS)、最长静音的帧数(maxsilence)、最短语音帧数(minlen)
%输出:开始/结束/语音长度(帧;结构数据;voiceseg)、端点检测数(个;vsl)、有话帧(1*fn数组;SF)、无话帧(1*fn数组;NF)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
x=x(:); % 把x转换成列数组
status = 0;
count = 0;
silence = 0;
y=enframe(x,wlen,inc)'; % 分帧
fn=size(y,2); % 帧数
amp=sum(y.^2); % 求取短时平均能量
zcr=zc2(y,fn); % 计算短时平均过零率
ampth=mean(amp(1:NIS)); % 计算初始无话段区间能量和过零率的平均值
zcrth=mean(zcr(1:NIS));
amp2=2*ampth; amp1=4*ampth; % 设置能量和过零率的阈值
zcr2=2*zcrth;
%开始端点检测
xn=1;
for n=1:fn
switch status
case {0,1} % 0 = 静音, 1 = 可能开始
if amp(n) > amp1 % 确信进入语音段
x1(xn) = max(n-count(xn)-1,1);
status = 2;
silence(xn) = 0;
count(xn) = count(xn) + 1;
elseif amp(n) > amp2 | ... % 可能处于语音段
zcr(n) > zcr2
status = 1;
count(xn) = count(xn) + 1;
else % 静音状态
status = 0;
count(xn) = 0;
x1(xn)=0;
x2(xn)=0;
end
case 2, % 2 = 语音段
if amp(n) > amp2 & ... % 保持在语音段
zcr(n) > zcr2
count(xn) = count(xn) + 1;
else % 语音将结束
silence(xn) = silence(xn)+1;
if silence(xn) < maxsilence % 静音还不够长,语音尚未结束
count(xn) = count(xn) + 1;
elseif count(xn) < minlen % 语音长度太短,认为是静音或噪声
status = 0;
silence(xn) = 0;
count(xn) = 0;
else % 语音结束
status = 3;
x2(xn)=x1(xn)+count(xn);
end
end
case 3, % 语音结束,为下一个语音准备
status = 0;
xn=xn+1;
count(xn) = 0;
silence(xn)=0;
x1(xn)=0;
x2(xn)=0;
end
end
el=length(x1);
if x1(el)==0, el=el-1; end % 获得x1的实际长度
if x2(el)==0 % 如果x2最后一个值为0,对它设置为fn
fprintf('Error: Not find endding point!\n');
x2(el)=fn;
end
SF=zeros(1,fn); % 按x1和x2,对SF和NF赋值
NF=ones(1,fn);
for i=1 : el
SF(x1(i):x2(i))=1;
NF(x1(i):x2(i))=0;
end
speechIndex=find(SF==1); % 计算voiceseg
voiceseg=findSegment(speechIndex);
vsl=length(voiceseg);
ARMA模型
理论
AR auto-regressive 自回归模型
含义:现在的输出是现在的输入和过去p个输入的加权和
表达:AR§
MA moving-average 移动平均模型
含义:在t时刻的随机变量的取值是前q个的随机扰动的多元线性函数
表达:MA(q)
ARMA
含义:随机变量的取值,与以前p期的序列值和与前q期的随机扰动有关。
推导

实验(ing)
假设肺音信号是局部平稳的,采用ARMA模型,使用过去值或未来值,来替代缺失的x(n)数据。
思路:
对移除的片段进行平稳性检查
若后邻段不平稳,则使用正向线性预测;
若后邻段平稳,则使用逆向线性预测。
