本人CSDN博客专栏:https://blog.csdn.net/yty_7
Github地址:https://github.com/yot777/
在机器学习和深度学习中的数据预处理环节,一个非常重要的步骤是对数据进行归一化和标准化处理。
归一化的概念
什么是归一化?简单的说,就是通过计算把所有的数据归纳统一到指定范围中去,一般这个范围是0~1。
归一化的公式
如何进行归一化?可以通过以下两个公式进行:
(1)变换系数公式
![]()
item代表数组每列中所有的元素
max为该列所有数据的最大值,min为该列所有数据的最小值
原始array数组如下:
>>> import numpy as np
>>> data = np.array([[36,46],[45,25],[6,79]])
>>> print(data)
[[36 46]
[45 25]
[ 6 79]]步骤1:求出每列的最小值和最大值
>>> n_max=np.max(data,axis=0)
>>> print(n_max)
[45 79]
>>> n_min=np.min(data,axis=0)
>>> print(n_min)
[ 6 25]步骤2:由原始矩阵的每一个元素减去该列元素的最小值n_min,得到公式的分子
>>> fenzi = np.subtract(data,n_min)
>>> print(fenzi)
[[30 21]
[39 0]
[ 0 54]]讲解:n_min原来是一维数组(,2),data是二维数组(3,2)
由于要进行数组的subtract()减法,计算中n_min由Python自动进行了广播化,变成了二维数组(3,2)
[[6 25]
[6 25]
[6 25]]
因此np.subtract(data,n_min)的计算过程是

步骤3:由原始矩阵的每列的最大值n_max减去每列的最小值n_min,得到公式的分母
>>> fenmu = np.subtract(n_max,n_min)
>>> print(fenmu)
[39 54]讲解:
np.subtract(n_max,n_min)的结果是
[45 79] - [6 25] = [39 54]
步骤4:由分子除以分母,就得到变换系数的最终值
>>> x = np.divide(fenzi,fenmu)
>>> print(x)
[[0.76923077 0.38888889]
[1. 0. ]
[0. 1. ]]讲解:fenzi是二维数组(3,2),fenmu是一维数组(,2)
由于要进行数组的divide()除法,计算中fenmu由Python自动进行了广播化,变成了二维数组(3,2)
[[39 54]
[39 54]
[39 54]]
因此np.divide(fenzi,fenmu)的计算过程是
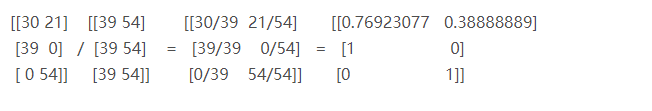
熟练之后,以上4步可以用以下一行完成,代码如下:
>>> x = np.divide(np.subtract(data,np.min(data,axis=0)),np.subtract(np.max(data,axis=0),np.min(data,axis=0)))
>>> print(x)
[[0.76923077 0.38888889]
[1. 0. ]
[0. 1. ]](2)范围变换公式
![]()
mx为选定范围的最大值,mi为选定范围的最小值。
特例,如果需要归一化的值的范围就是在0~1之间,也就是mx=1,mi=0的时候无需进行范围变换,因为:
![]()
如果我们需要把x'矩阵变化到-1到1之间,也就是mx=1,mi=-1的时候:
>>> mx = 1
>>> mi = -1
>>> xx = x*(mx-mi)+mi
>>> print(xx)
[[ 0.53846154 -0.22222222]
[ 1. -1. ]
[-1. 1. ]]讲解:x是二维数组(3,2),mx-mi = 2,x*(mx-mi)就是

最终结果x*(mx-mi)+mi就是

标准化的概念
把每一列的数据尽可能的接近标准的高斯分布(均值为0,标准差为1)
标准化的公式
![]()
item代表数组每列中所有的元素,mean为该列所有数据的平均值
σ为该列所有数据的标准差
注意:mean可以由numpy的mean()函数计算,σ可以由numpy的std()函数计算
代码:
>>> import numpy as np
>>> data = np.array([[36,46],[45,25],[6,79]])
>>> print(data)
[[36 46]
[45 25]
[ 6 79]]
#根据标准化的公式:X = (item - mean) / σ
#item代表数组每列中所有的元素,mean为该列所有数据的平均值,σ为该列所有数据的标准差
#mean可以由numpy的mean()函数计算
>>> n_mean = np.mean(data,axis=0)
>>> print(n_mean)
[29. 50.]
##σ可以由numpy的std()函数计算
>>> n_std = np.std(data,axis=0)
>>> print(n_std)
[16.673332 22.22611077]
#将mean和σ代入公式,得到最终结果
>>> xxx = np.divide(np.subtract(data,n_mean),n_std)
>>> print(xxx)
[[ 0.4198321 -0.17996851]
[ 0.95961623 -1.12480318]
[-1.37944833 1.30477168]]
总结
1. 归一化的公式是

item代表数组每列中所有的元素
max为该列所有数据的最大值,min为该列所有数据的最小值
mx为选定范围的最大值,mi为选定范围的最小值
如果归一化的范围就是0~1,无需计算第二个公式
2. 标准化的公式是
![]()
item代表数组每列中所有的元素,mean为该列所有数据的平均值
σ为该列所有数据的标准差
mean可以由numpy的mean()函数计算,σ可以由numpy的std()函数计算
本人CSDN博客专栏:https://blog.csdn.net/yty_7
Github地址:https://github.com/yot777/
如果您觉得本篇本章对您有所帮助,欢迎关注、评论、点赞!Github欢迎您的Follow、Star!
