哈希表
在此致谢小码哥的恋上数据结构,堪称经典中的经典。
在此致谢小码哥的恋上数据结构,堪称经典中的经典。
在此致谢小码哥的恋上数据结构,堪称经典中的经典。
引出哈希表
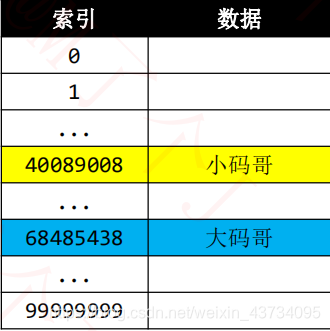
设计一个写字楼通讯录,存放所有公司的通讯信息
- 座机号码作为 key(假设座机号码最长是8位)
公司详情(名称、地址等)作为 value - 添加、删除、搜索的时间复杂度要求是
我们用这种思路,将座机号码作为索引值数组数组索引,公司详情作为数据元素值。
由于数组添加、删除、搜索元素的时间复杂度都是
,可以达到要求。
private Company[] companies = new Company[100000000];
public void add(int phone, Company company){
companies[phone] = company;
}
public void remove(int phone){
companies[phone] = null;
}
public Company get(int phone){
return companies[phone];
}
但是这种做法有缺点。
- 空间复杂度非常大
要保证必须存储的下元素,必须开辟一个非常大的空间。 - 空间使用率极其低,非常浪费内存空间
就拿电话号码来说,开辟了100000000大小的空间,但是1~99999999之间有很多数字是索引值是用不到的。
其实 数组companies 就是一个哈希表,典型的【空间换时间】。
哈希表
哈希表也叫做散列表(hash有“剁碎”的意思)
哈希表是如何实现高效处理数据的?
put("Jack",666);
put("Rose",777);
put("Kate",888);
1.利用哈希函数生成 key 对应的 index【
】
2.根据 index 操作定位数组元素【
】
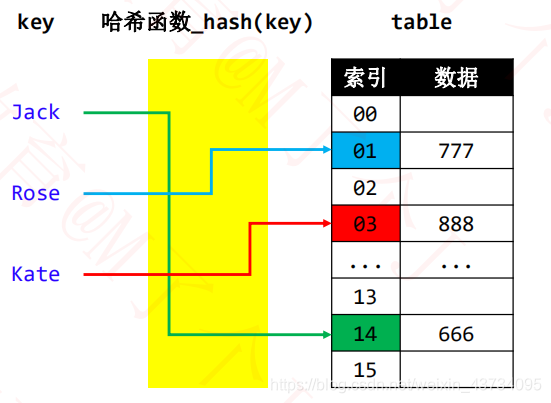
- 哈希表添加、搜索、删除的流程都是类似的
- 哈希表是【空间换时间】的典型应用
- 哈希函数,也叫做散列函数
- 哈希表内部的数组元素,很多地方也叫 Bucket(桶),整个数组叫 Buckets 或者 Bucket Array
哈希冲突
哈希冲突也叫做哈希碰撞
- 2个不同的 key,经过哈希函数计算出相同的结果
- key1 key2, hash(key1) = hash(key2)
如下图,“Rose” 不等于 “Kate”,但是经过哈希函数算出来的索引确实相同的,此时就产生了冲突。

解决哈希冲突的常见方法
- 开放定址法(Open Addressing)
按照一定规则向其他地址探测,直到遇到空桶 - 再哈希法(Re-Hashing)
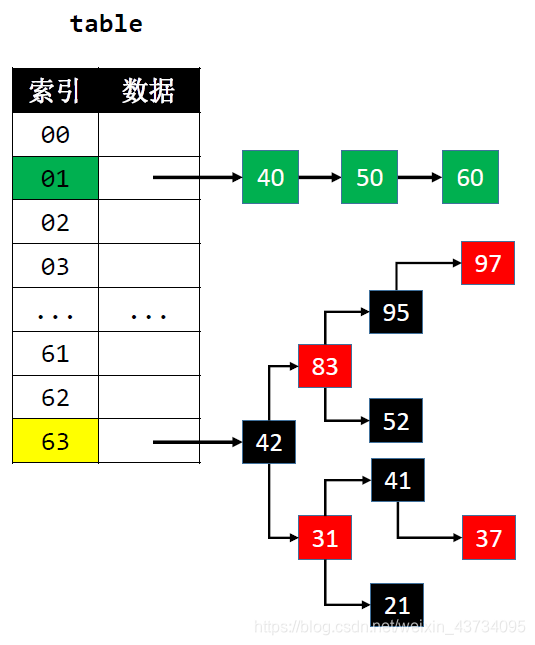
设计多个哈希函数 - 链地址法(Separate Chaining)
比如通过链表将同一 index 的元素串起来
JDK1.8的哈希冲突解决方案
- 默认使用单向链表将元素串起来
- 在添加元素时,可能会由单向链表转为红黑树来存储元素
比如当哈希表容量 ≥ 64 且 单向链表的节点数量大于 8 时 - 当红黑树节点数量少到一定程度时,又会转为单向链表
- JDK1.8中的哈希表是使用链表+红黑树解决哈希冲突
思考:这里为什么使用单链表而不是双向链表?
- 每次都是从头节点开始遍历
- 单向链表比双向链表少一个指针,可以节省内存空间
哈希函数
哈希表中哈希函数的实现步骤大概如下:
- 先生成 key 的哈希值(必须是整数)
- 再让 key 的哈希值跟数组的大小进行相关运算,生成一个索引值
public int hash(Object key) {
return hash_code(key) % table.length;
}
为了提高效率,可以使用 & 位运算 取代 % 运算
【前提:将数组的长度设计为 2 的幂(2n)】
public int hash(Object key) {
return hash_code(key) & (table.length - 1);
}
将数组的长度设计为 2 的幂( )是因为 的二进制必然为全 1
1 2^1-1=1
11 2^2-1=3
111 2^3-1=7
1111 2^4-1=15
11111 2^5-1=31
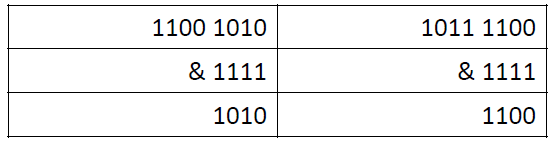
哈希值的二进制与一个全为1的二进制 &(相与),结果必然小于等于哈希值,如下图。
如何生成 key 的哈希值
key 的常见种类可能有
- 整数、浮点数、字符串、自定义对象
- 不同种类的 key ,哈希值的生成方式不一样,但目标是一致的
- 尽量让每个 key 的哈希值是唯一的
- 尽量让 key 的所有信息参与运算
在Java中,HashMap 的 key 必须实现 hashCode、equals 方法,也允许 key 为null
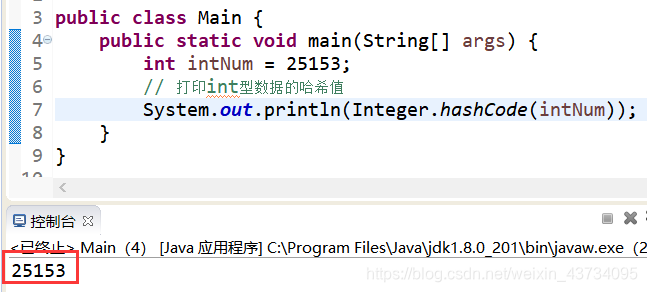
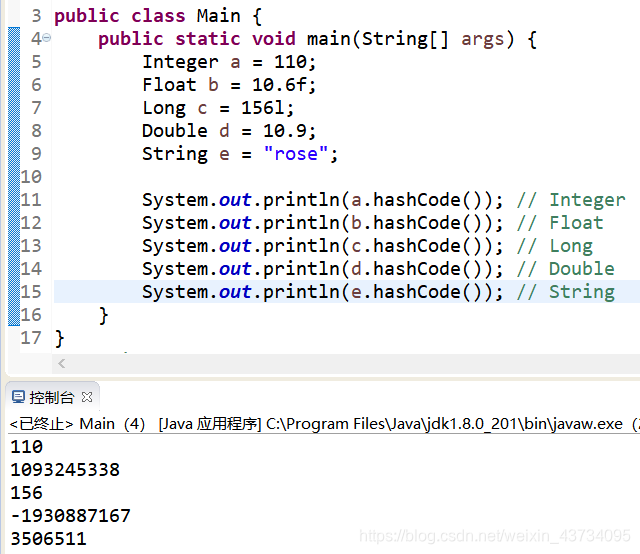
Integer 的哈希值计算
- 整数值当做哈希值
- 比如10的哈希值就是10
Java 中 Integer.hashCode() 源码:

让我们亲自打印一下:
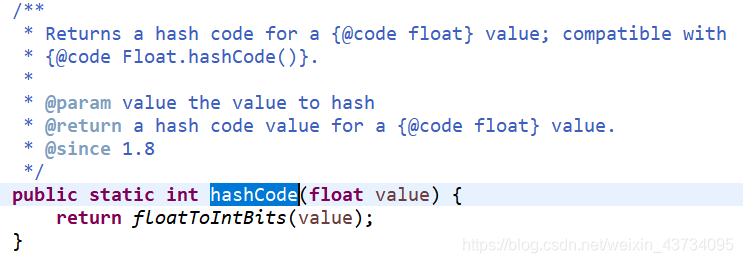
Float 的哈希值计算
- 将存储的二进制格式转为整数值
public static int hashCode(flaot value){
return floatToInBits(value);
}
Java 中 Float.hashCode() 源码:
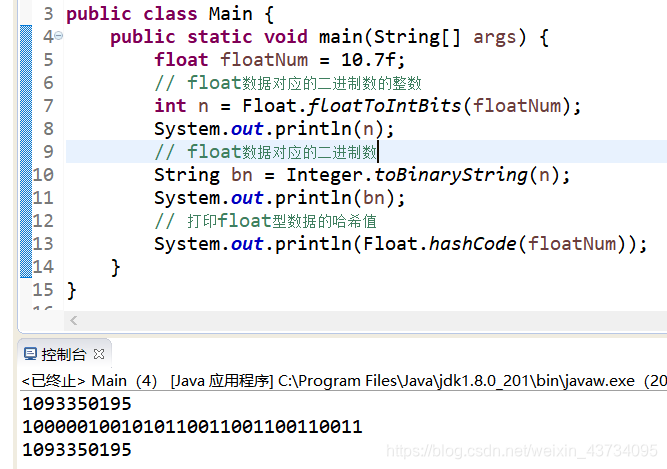
验证一下,float型数据的哈希值就是将对应的二进制数转为整数,只是浮点数的二进制跟整数的相比,在计算机中的存储方式更复杂,也更难计算。
Long 的哈希值计算
Long.HashCode()的计算有点奇怪,Java源码如下:
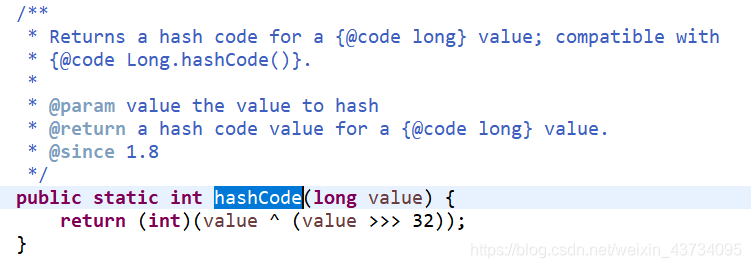
那么, ^ 和 >>> 的作用是什么呢?
- 高32bit 和 低32bit 混合计算出 32bit 的哈希值
- 充分利用所有信息计算出哈希值
>>> 即 无符号右移,代码中的 value >>> 32 即将 value 的值无符号右移 32 位。
^ 即位运算中的异或,它的作用是:两数异或,不同为1,相同为0。

由这张图可以知道,将 64bit 的二进制数字,无符号右移 32bit 后,左边32位必然全为0(第二行), 右边则为为左32位的数字,(value ^ (value >>> 32))相当于用自己的右32位去异或自己的左32位,最后(int)强转回了 32bit ,相当于把左边的32位全部去掉。这样可以充分利用了自身所有信息来计算哈希值。
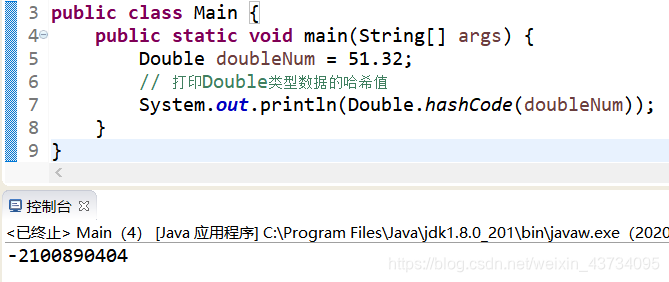
Double 的哈希值计算
惊奇的发现,Double.HashCode()的计算和 Long 差不多呢,就不多说了。

验证一下,果然是个奇奇怪怪的数字。
String 的哈希值计算
思考一下:整数 5489 是如何计算出来的?
字符串是由若干个字符组成的
- 比如字符串 jack,由 j、a、c、k 四个字符组成(字符的本质就是一个整数)
- 因此,jack 的哈希值可以表示为
等价于 (这样写效率比上面更高)
new String().hashCode() 源码如下: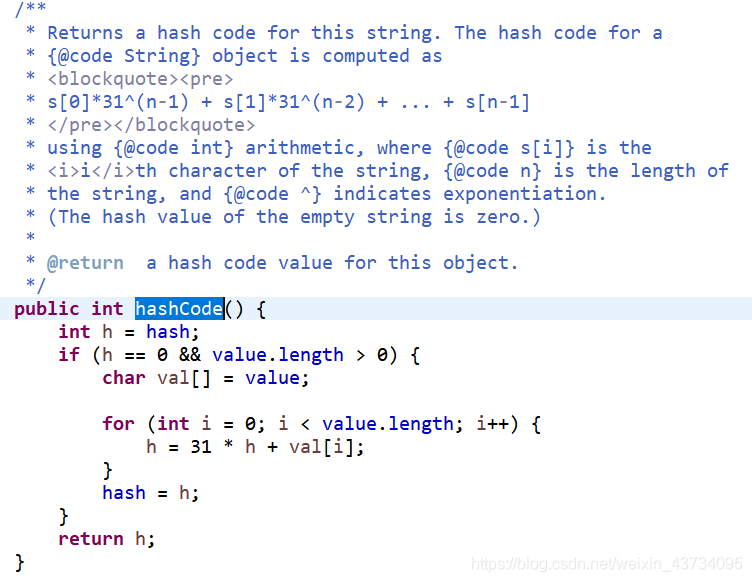
由上图可知,在JDK中,乘数n为31,为什么使用31?(了解一下)
- JVM 会将
31 * i优化成(i << 5) - i - 31 不仅仅是符合 ,它是个奇素数(既是奇数,又是素数,也就是质数)
- 素数和其他数相乘的结果比其他方式更容易产成唯一性,减少哈希冲突
- 最终选择 31 是经过观测分布结果后的选择
因此在Java中,下面两种写法完全等价。

哈希值计算总结
Java 中内置了计算哈希值的函数。
自定义对象的哈希值
我们写一个简单的Person类。
public class Person {
private int age;
private float height;
private String name;
public Person(int age, float height, String name) {
super();
this.age = age;
this.height = height;
this.name = name;
}
}
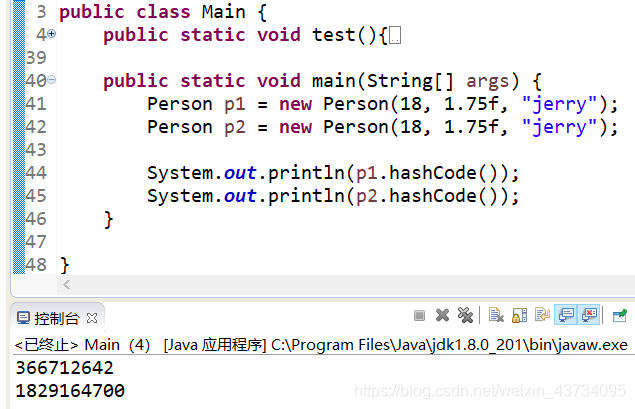
不重写hashCode
可以看到不重写hashCode也不重写equals的情况下,虽然自定义对象的属性值都是相等的,但是计算出来的哈希值不一样。(不重写hashCode的情况下,默认的哈希值的计算与内存地址有关系,即内存地址相同才有相同的哈希值)
重写hashCode
在 Person.java 内部重写了hashCode方法,使用了 Person 类所有的信息来计算哈希值。
public class Person {
private int age;
private float height;
private String name;
public Person(int age, float height, String name) {
super();
this.age = age;
this.height = height;
this.name = name;
}
@Override
public int hashCode() {
int hashCode = Integer.hashCode(age);// *31是因为JVM内部优化
hashCode = hashCode * 31 + Float.hashCode(height);
hashCode = hashCode * 31 + (name!=null ? name.hashCode() : 0);
return hashCode;
}
}
可见,重写hashCode的情况下,只要自定义对象的属性值都是相等的,计算出来的哈希值也是相等的。
重写hashCode方法和equals方法
hashCode方法的作用上面已经说过了,这里主要看一下 equals 方法。
equals 用以判断2个key 是否为同一个key。
- 自反性
对于任何非 null 的 x
x.equals(x)必须返回 true - 对称性
对于任何非 null 的 x、y
如果y.equals(x)返回 true
x.equals(y)必须返回 true - 传递性
对于任何非 null 的 x、y、z
如果x.equals(y)、y.equals(z)返回 true
那么x.equals(z)必须返回 true - 一致性
对于任何非 null 的 x、y
只要 equals 的比较操作在对象中所用的信息没有被修改
x.equals(y)的结果就不会变
不同类型的数据有可能计算出相同的哈希值,例如 String类型的数据与Double类型的数据的哈希值可能相同,此时会产生冲突,Java中解决冲突的方法为单链表与红黑树。
当两个 key 不相等,但是哈希值相等时,我们需要用 equals 方法来判断两个 key 是否为同一个key,此时就需要重写 equals。
public class Person {
private int age;
private float height;
private String name;
public Person(int age, float height, String name) {
super();
this.age = age;
this.height = height;
this.name = name;
}
@Override
/**
* 比较两个对象是否相等
*/
public boolean equals(Object obj) {
if(this == obj) return true;
if(obj == null || obj.getClass() != getClass()) return false;
Person person = (Person)obj;
return person.age == age
&& person.height == height
&& person.name==null ? name==null : person.name.equals(name);
// 传入name若为空,则当前对象name也必须为空才为 true
// 传入name若不为空,则调用equals方法比较即可
}
@Override
public int hashCode() {
int hashCode = Integer.hashCode(age);
hashCode = hashCode * 31 + Float.hashCode(height);
hashCode = hashCode * 31 + (name!=null ? name.hashCode() : 0);
return hashCode;
}
}
验证一下重写了equals和hashCode的作用:
- 由于重写
hashCode,p1、p2 哈希值必然相等,则放入 map 会去比较 key - 由于重写
equals,p1、p2 为同一 key,则 p1 会覆盖 p2
public static void main(String[] args) {
Person p1 = new Person(18, 1.75f, "jerry");
Person p2 = new Person(18, 1.75f, "jerry");
// 由于重写 hashCode(),p1、p2哈希值必然相等
Map<Object, Object> map = new HashMap<>();
map.put(p1, "abc");
map.put("test", "bcd");
// 由于 p1 与 p2 哈希值相等
// 会比较 p1 与 p2 是否为同一key
// 由于重写 equals(), p1、p1为同一key
map.put(p2, "ccc"); // 同一 key 则覆盖,map里的元素数量不增加
System.out.println(map.size()); // 2
}
2
- 若只重写
hashCode
由于重写hashCode,p1、p2 哈希值必然相等,则放入 map 会去比较 key
但是equals默认比较地址,p1、p2地址不同,不为同一 key,因此map.size()为3 - 若只重写
equals
由于没有重写hashCode,p1、p2 哈希值大概率不相等(有极小可能相等)
一般情况下,p1、p2哈希值不相等,map.size()值应当为3
若是真遇到了哈希值相等的情况,由于重写了equals,map.size()值为2
结论就是,重写 hashCode 与 equals 是最稳妥的做法。
易错点总结
- 哈希值相等,根据哈希函数求的索引必然相等
- 哈希值不相等,根据哈希函数求的索引有可能相等
原因是hash_code(key) & (table.length - 1)取模运算可能会遇到相等的情况
可以理解为 2 % 3 = 2,5 % 3 = 2,2 和 3 不相等,%3 的结果却相等 - HashMap 的 key 必须实现 hashCode、equals 方法,也允许 key 为
null
