大家好, 我是上白书妖!
知识源于积累,登峰造极源于自律
今天我根据以前所以学的一些文献,笔记等资料整理出一些小知识点,有不当之处,欢迎各位斧正
ERROR: java.util.concurrent.ExecutionException: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /HBase/.tmp/data/default/staff1/6a1ca482b0fd986322689abfc376b0c7/.regioninfo could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and no node(s) are excluded in this operation.
图示:
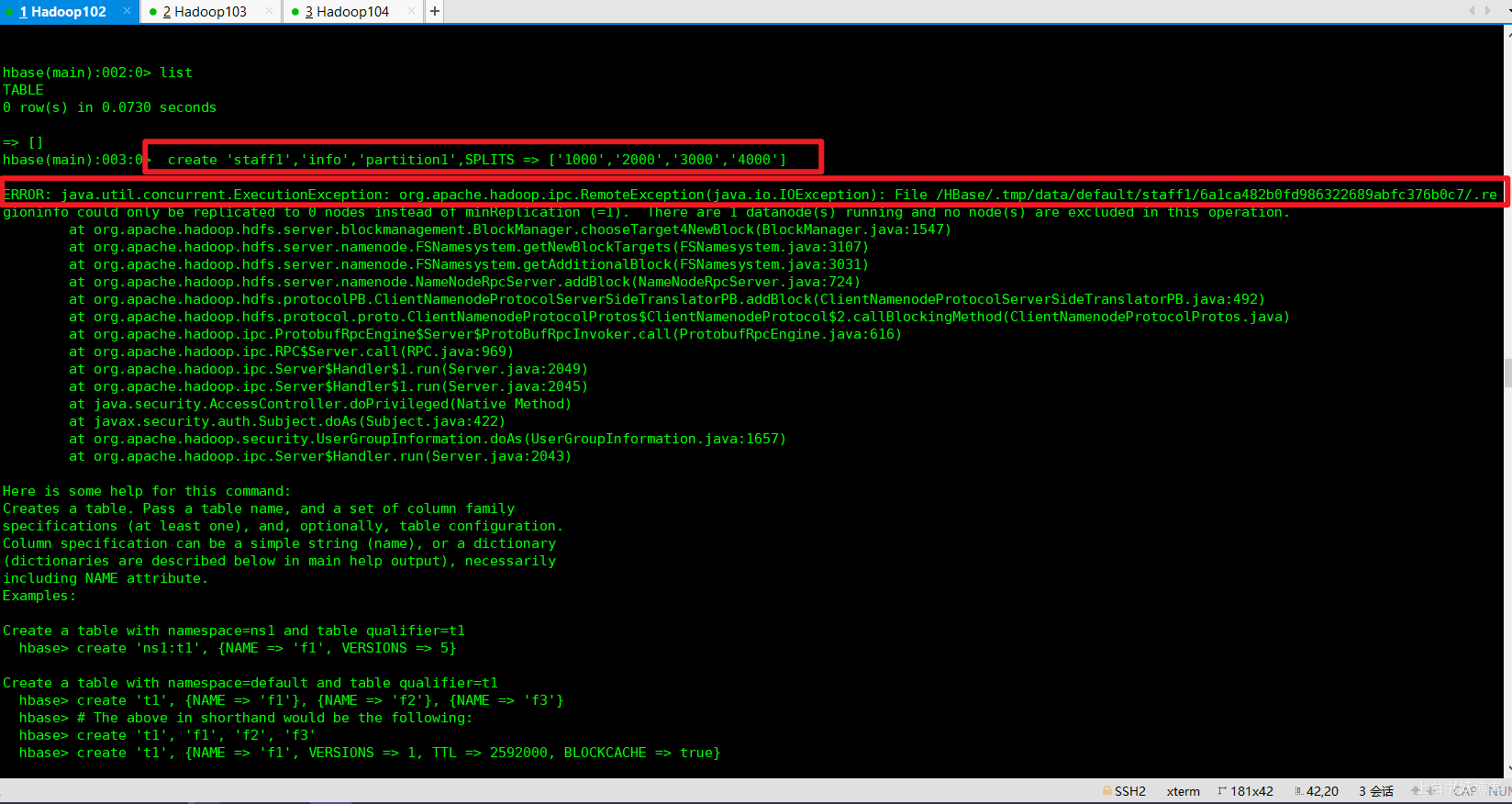
敬请看这位大佬的!!!
虽然这位大佬是hadoop上传文件有错误,并不是Hbase优化的手动设定预分区有错误,但是既然我能解决Hbase的问题,说明方法是对的,另一方面也说明,这个Hbase和hadoop文件上传可能牵扯某些联系,这是猜想!
查阅资料发现造成这个问题的原因可能是使用hadoop namenode -format格式化时格式化了多次造成那么spaceID不一致,解决方案:
1、停止集群(切换到/sbin目录下)
$./stop-all.sh
2、删除在hdfs中配置的data目录(即在core-site.xml中配置的hadoop.tmp.dir对应文件件)下面的所有数据;
$ rm -rf /opt/module/hadoop-2.7.2/data/tmp
如图所示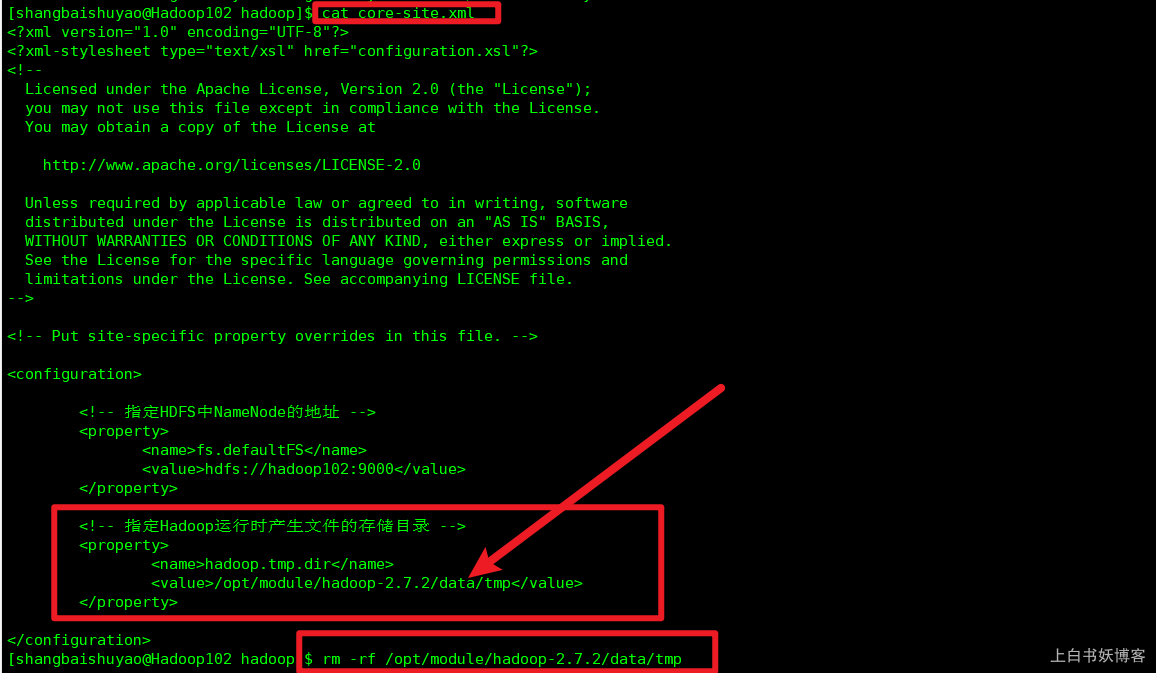
3、重新格式化namenode(切换到hadoop目录下的bin目录下) $ ./hadoop namenode -format
4、重新启动hadoop集群(切换到hadoop目录下的sbin目录下) $./start-all.sh
5、然后重新启动zookeeper,Hbase等
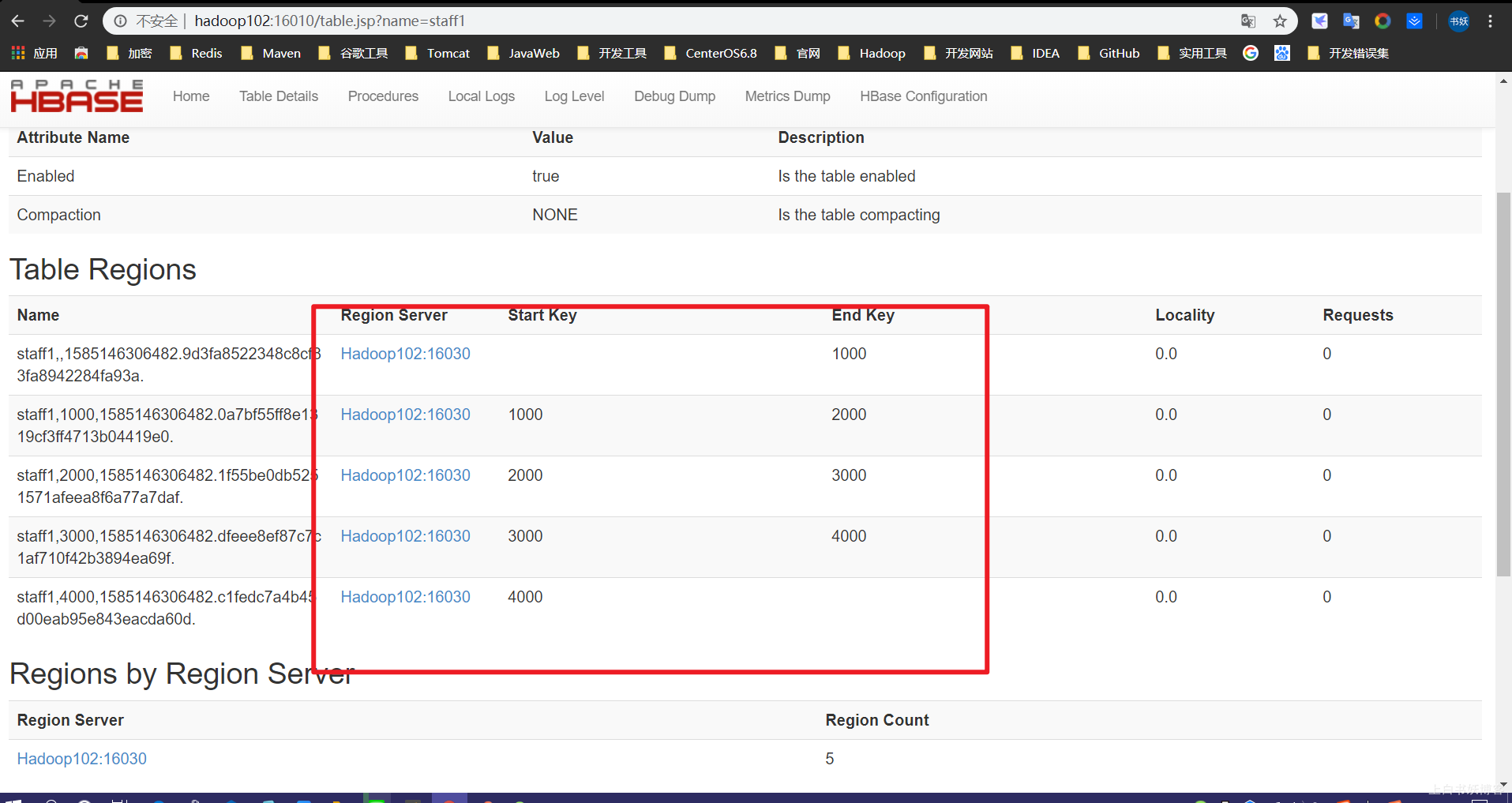
然后如图所示,就成功了!!!