一般来说,验证集越大,我们对模型质量的度量中的随机性(也称为“噪声”)就越小,它就越可靠。但是,通常我们只能通过划分出更多训练数据来获得一个大的验证集,而较小的训练数据集意味着更糟糕的模型!而交叉验证可是用来解决这个问题。
什么是交叉验证?
在交叉验证中,我们将数据集等量划分成几个小的子集,然后对不同的子集运行建模过程,以获得每个子集模型的拟合效果的指标(可用MAE 平均绝对误差表示)。
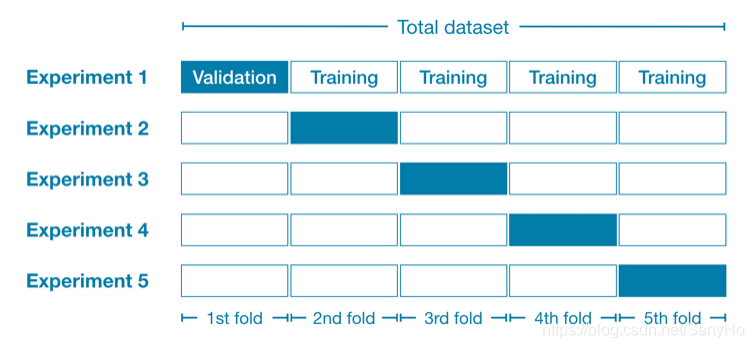
- 我们将所有的数据集分为五部分(5 folds),每部分有20%的数据。
- 在实验1中,我们使用第一个折叠(1st-fold)作为一个验证集,其他所有数据作为训练数据。之后获得第一个训练的模型拟合效果的指标
- 在实验2中,我们使用第二个折叠(2nd-fold)作为一个验证集(并使用除第二个折叠之外的所有内容来训练模型)。之后得到第二个训练的模型拟合效果的指标
- 我们重复这个过程,每次用一个折叠作为验证集。知道所有的折叠都被用作过验证集。
- 比较五个MAE的值,MAE的值最小所对应的实验,获得的模型和参数即为最优模型和最优参数。
什么时候用交叉验证?
- 当数据较少时,用交叉验证cross-validation
- 当数据较大时,用简单验证法,将样本数据随机分为两部分(如80%训练集和20%训练集)。如果用交叉验证,那么耗时会过长。
- 没有简单的阈值来划分大数据集和小数据集。但是,如果模型需要几分钟或更少的时间运行,则可能值得切换到交叉验证。
- 或者,可以运行交叉验证,看看每个实验的分数是否接近。如果每个实验都得到差不多相同的结果,那么一个验证集(简单验证法)可能就足够了。
Example
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
data = pd.read_csv('filename.csv')
X = data[['column_1','column_2']]
Y = data['column_3']
model = RandomForestRegressor(m_estimators=100, random_state=0)
# 将得分*(-1),因为scikit learn计算的是负的MAE
# cv是代表折叠的次数
scores = -1 * cross_val_score(model, X, y, cv=5, scoring='neg_mean_absolute_error')
print("MAE scores:\n", scores)
MAE scores:
[301628.7893587 303164.4782723 287298.331666 236061.84754543 260383.45111427]
从MAE得分可以看出,实验四的MAE值最小,即该子集模型的拟合效果最好。
Scikit learn有一个约定,其中定义了所有度量,因此较高的数字更好。在这里使用否定词可以使它们与该惯例保持一致,尽管负的MAE在其他地方几乎闻所未闻。
print("Average MAE score (across experiments):")
print(scores.mean())
Average MAE score (across experiments):
277707.3795913405
此外,我们可以取所有实验(实验1~5)的平均值,来获得该算法的精度。然后可以尝试着用不同算法进行实验,看哪个算法更适用于这个数据集。
