1 关联分析算法:Apriori
关联规则挖掘的重要算法:Apriori
关联规则挖掘可以让我们从数据集中发现项与项(item 与 item)之间的关系
概念:
支持度:指的是某个物品在组合中出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
置信度:指的是在 A 发生的情况下,B 发生的概率是多少。
提升度:指的是A的发生对B的发生概率提升的程度。
公式:提升度 (A→B)= 置信度 (A→B)/ 支持度 (B),用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升
频繁项集:支持度大于等于最小支持度 (Min Support,可随机指定) 阈值的项集,所以小于最小值支持度的项目就是非频繁项集,而大于等于最小支持度的项集就是频繁项集。
工作原理:
1 初始化K=1,计算 K 项集的支持度;
2 筛选掉小于最小支持度(随机指定)的项集;
扫描二维码关注公众号,回复: 10336277 查看本文章
3 如果项集为空,则对应 K-1 项集的结果为最终结果,或者说项集只有一行,那此行就是结果;
否则 K=K+1,重复 1-3 步。
FP-Growth 算法:对Apriori进行改进
Apriori缺陷:
1 可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了;
2 每次计算都需要重新扫描数据集,来计算每个项集的支持度。
FP-Growth特点:
1 创建了一棵 FP 树来存储频繁项集。在创建前对不满足最小支持度的项进行删除,减少了存储空间。
2 整个生成过程只遍历数据集 2 次,大大减少了计算量。
FP-Growth原理:
1 创建项头表(item header table)
先扫描一遍数据集,对于满足最小支持度的单个项(K=1 项集)按照支持度从高到低进行排序,这个过程中删除了不满足最小支持度的项
2 构造 FP 树
根节点记为 NULL 节点,扫描筛选过后的数据集,对于每一条数据,按照支持度从高到低的顺序进行创建节点;
节点如果存在就将计数 count+1,如果不存在就进行创建。同时在创建的过程中,需要更新项头表的链表。3 通过 FP 树挖掘频繁项集
具体的操作会用到一个概念,叫“条件模式基”;
指的是以要挖掘的节点为叶子节点,自底向上求出 FP 子树,然后将 FP 子树的祖先节点设置为叶子节点之和。
2 PageRank
目的就是要找到优质的网页,网页之间会形成一个网络,也即互联网,论文之间也存在着相互引用的关系,可以说
目前网络环境就是各种网络的集合。只要是有网络的地方,就存在出链和入链,就会有 PR 权重的计算,也就可以运用 PageRank 算法,社交网络也可以使用此算法来计算一个人的影响力
概念:出链指的是链接出去的链接。入链指的是链接进来的链接;如图中 网页A 有 2 个入链,3 个出链。
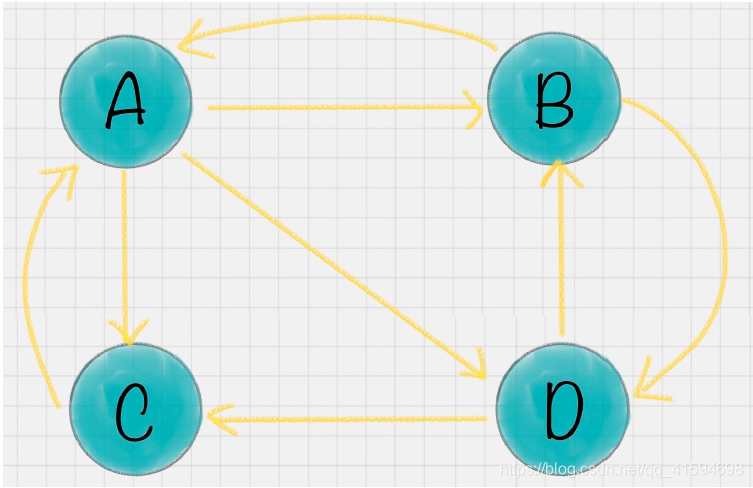
简化模型中,一个网页的影响力 = 所有入链集合的页面的加权影响力之和:
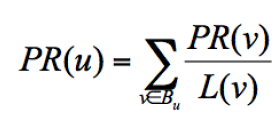
u 为待评估的页面, 为页面 u 的入链集合。针对入链集合中的任意页面 v,它能给 u带来的影响力是其自身的影响力 PR(v) 除以 v 页面的出链数量,即页面 v 把影响力 PR(v)平均分配给了它的出链,这样统计所有能给 u 带来链接的页面 v,得到的总和就是网页 u的影响力,即为 PR(u)。
为了解决简化模型中存在的等级泄露和等级沉没的问题,出现了随机浏览模型:用户并不都是按照跳转链接的方式来上网,还有一种可能是不论当前处于哪个页面,都有概率访问到其他任意的页面,所以定义了阻尼因子 d,这个因子代表了用户按照跳转链接来上网的概率,通常可以取一个固定值 0.85,而 1-d=0.15 则代表了用户不是通过跳转链接的方式来访问网页的,比如直接输入网址,公式为:
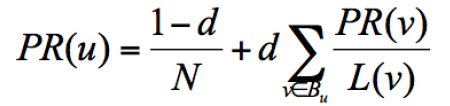
其中 N 为网页总数,因为加入了阻尼因子d,一定程度上解决了等级泄露和等级沉没的问题。
3 逻辑回归
逻辑回归,也叫作 logistic 回归,是常用的数据挖掘算法
虽然名字中带有“回归”,但它实际上是分类方法,主要解决的是二分类问题,当然它也可以解决多分类问题,只是二分类更常见一些。
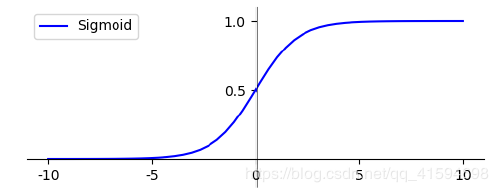
在逻辑回归中使用了 Logistic 函数,也称为 Sigmoid 函数。
Sigmoid 函数是在深度学习中经常用到的函数之一,函数公式为:
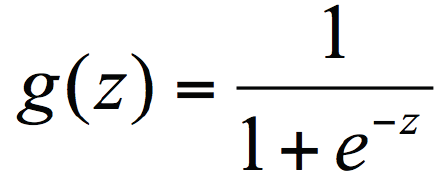
函数的图形类似 S 状
为什么逻辑回归算法是基于 Sigmoid 函数实现的?
我们要实现一个二分类任务,0 即为不发生,1 即为发生;
给定一些历史数据 X 和 y,其中 X 代表样本的 n 个特征,y 代表正例和负例,也就是 0 或 1 的取值。
通过历史样本的学习,我们可以得到一个模型,当给定新的 X 的时候,可以预测出 y。
这里得到的 y 是一个预测的概率,通常不是 0% 和100%,而是中间的取值,那么就可以认为概率大于 50% 的时候,即为发生(正例),概率小于 50% 的时候,即为不发生(负例)。这样就完成了二分类的预测。
