七、容器相关类
列表(list)、元组(tuple)和字典(dict)等常用类型是容器类型,此外,Python 还有集合(set)、双端队列(deque)等数据类型,同样是 Python 编程的基础内容,需要重点掌握。
大部分编程语言都提供有 list、set、dict(有的叫 dictionary或map)、deque 这些数据类型。计算机编程中流行的一句话是:程序 = 数据结构 + 算法。“数据结构” 所讲的主要内容就是 list、set、dict、deque等,因为这些数据是软件开发的基础。此外,学习 “数据结构” 是需要有一定的编程基础才行。
编程语言中4种主流的数据结构是:list、set、dict、deque。
- set 集合就像一个罐子,把一个对象添加到 set 集合时,set 集合无法记住添加这个元素的顺序,所以 set 里的元素不能重复;
- list 容器就是列表,它可以记住每次添加元素的顺序,因此可以通过索引来存取元素,list 容器允许重复;
- dict 容器就是字典,它里面的每项数据都是由 key-value 对组成,因此可通过 key 来存取 value。
- deque 是一个双端队列,它的两端都可以添加、删除元素,它既可作为栈(stack)使用,也可作为队列(queue)使用。
1、 set 和 frozenset
set 集合的两个牲:set 不记录元素的添加顺序;元素不允许重复。
set集合是可变容器,在程序中可以改变容器中的元素。与 set 对应的还有 frozenset 集合,frozenset 是 set 的不可变版本,它的元素是不可变的。在交互式解释器使用 [s for s in dir(set) if not s.startswith('_')] 命令可查看 set 集合的全部方法,
示例如下:
>>> [s for s in dir(set) if not s.startswith('_')]
['add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update','union', 'update']
对于这些方法,可根据其名称知道它们的作用,如 add() 就是向 set 集合中添加元素,remove()、discard()就是删除元素,clear() 是清空集合等。
remove() 和 discard() 方法都用于删除集合中的元素,它们的区别是:如果集合中不包含被删除的元素,remove() 方法会抛出KeyError异常,而 discard() 方法则什么也不做。
set() 集合的用法示例如下:
# 创建 set 集合
aset = {'python'}
# 使用集合的 add() 方法添加元素
aset.add('linux')
aset.add(5)
print('aset集合的元素个数:', len(aset)) # 输出:3
# 使用集合的 remove() 方法删除指定元素
aset.remove(5)
print('aset集合的元素个数:', len(aset)) # 输出:2
# 判断集合中是否包含指定字符串
print('aset集合中是否包含“linux”字符串:', ('linux' in aset)) # 输出:True
aset.add('java')
print('aset集合的元素:', aset) # 输出:{'linux', 'java', 'python'}
# 下面使用 set() 函数(构造器)来创建 set 集合
bset = set()
bset.add('python')
bset.add("Bash 编程")
print('bset集合的元素:', bset) # 输出:{'Bash 编程', 'python'}
# 使用 issubset() 方法判断是否是子集合
print('bset是否是aset的子集合?', bset.issubset(aset)) # 输出:False
# issubset() 方法与 <= 运算符的效果相同
print('bset是否是aset的子集合?', (bset <= aset)) # 输出:False
# 使用 issuperset() 判断是否为父集合,对应的运算符是 >=
print('aset集合是否完全包含bset集合?', aset.issuperset(bset)) # 输出:False
print('aset集合是否完全包含bset集合?', aset >= bset) # 输出:False
# 使用 difference() 方法对集合做减法,对应的运算符是减号“-”,不改变原来的集合
print(aset.difference(bset)) # 输出:{'java', 'linux'}
print(aset - bset) # 输出:{'java', 'linux'}
# difference_update()方法是用集合 aset 减去 bset 集合里的元素,改变 aset 集合本身
aset.difference_update(bset)
print("aset集合的元素:", aset) # 输出:{'java', 'linux'}
# 删除 aset 集合里的所有元素
aset.clear()
print(aset) # 输出空集合:set()
# 直接创建包含元素的集合
cset = {'python 入门', 'python 进阶', 'Bash 编程'}
print("cset集合的元素:", cset) # 输出:{'Bash 编程', 'python 进阶', 'python 入门'}
# 使用 intersettion() 方法获取两个集合的交集,对应的运算符是”&“,不改变集合本身
inter1 = cset & bset
inter2 = cset.intersection(bset)
print(inter1) # 输出:{'Bash 编程'}
print(inter2) # 输出:{'Bash 编程'}
# 使用 intersection_update() 方法计算两个集合的交集,要改变 bset 集合本身
bset.intersection_update(cset)
print('bset集合的元素:', bset) # 输出:{'Bash 编程'}
# 将序列对象传递给 set() 可直接创建 set 集合
d = set(range(5))
e = set(range(3, 8))
f = set('abc')
print("d集合的元素:", d) # 输出:{0, 1, 2, 3, 4}
print("e集合的元素:", e) # 输出:{3, 4, 5, 6, 7}
print("f集合的元素:", f) # 输出:{'b', 'c', 'a'}
# 对两个集合执行异或运算
xor = d ^ e
print('d 和 e 执行 xor 的结果:', xor) # 输出:{0, 1, 2, 5, 6, 7}
# 使用 union() 方法计算两个集合的并集,不改变集合 d 本身
un = d.union(e)
print('d 和 e 执行并集的结果:', un)
# 使用 update() 方法计算两个集合的并集时,会改变集合 d 本身
d.update(e)
print('d 集合的元素:', d) # 输出:{0, 1, 2, 3, 4, 5, 6, 7}
上面代码示例了集合的基本用法,还示例了 set 集合所支持的几个运算符:
(1)、<=:同 issubset() 方法,判断前面的 set 集合是否为后面的 set 集合的子集合。
(2)、>=:同 issuperset() 方法,判断前面的集合是否为后面集合的父集合。
(3)、-:同 difference() 方法,用前面的集合减去后面的集合的元素。
(4)、&:同 intersection() 方法,用于获取两个集合的交集。
(5)、^:计算两个集异或的结果,就是用两个集合并集减去交集的元素。
集合本身是可变的,集合提供了 add()、remove()、discard()方法来操作单个元素。集合还支持进行集合运算来改变集合内的元素。集合的运算方法都有两个版本,一个是改变集合本身,一个是不改变集合本身。
(1)、交集运算:intersection() 和 intersection_update(),前者不改变集合本身,而是返回两个集合的交集;后者会通过交集运算改变第一个集合。
(2)、并集运算:union() 和 update(),前者不改变集合本身,而是返回两个集合的并集;后者会通过并集运算改变第一个集合。
(3)、减法运算:difference() 和 difference_update(),前者不改变集合本身,而是返回两个集合做减法的结果;后者改变第一个集合。
frozenset 是 set 的不可变版本,因此 set 集合中所有能改变集合本身的方法(如add、remove、discard、xxx_update等),在frozenset 都不支持;set 集合中不改变集合本身的方法,在 frozenset 都支持。在交互式解释器中输入[s for s in dir(frozenset) if not s.startswith("_")] 命令可查看 frozenset 集合撮合的全部方法,如下所示:
>>> [s for s in dir(frozenset) if not s.startswith("_")]
['copy', 'difference', 'intersection', 'isdisjoint', 'issubset', 'issuperset', 'symmetric_difference', 'union']
frozenset 的这些方法与 set 集合中的同名方法的功能是完全相同的。frozenset 的作用有下面两点:
(1)、当集合元素不需要改变时,使用 frozenset 代替 set 更安全。
(2)、当某些 API 需要不可变对象时,必须用 frozenset 代替 set。例如字典(dict)的 key 必须是不可变对象,因此只能使用 frozenset;例如 set 本身的集合元素必须是不可变的,因此 set 不能包含 set,set 只能包含 frozenset。
下面示例在 set 集合中添加 frozenset 集合,示例如下:
s = set()
frozen_s = frozenset('linux')
# 为 set 集合添加 frozenset
s.add(frozen_s)
print('s 集合的元素:', s)
sub_s = set('python')
# 为 set 集合添加普通的 set 集合,运行时报错
s.add(sub_s)
输出信息如下:
s 集合的元素: {frozenset({'u', 'x', 'i', 'n', 'l'})}
Traceback (most recent call last):
File "frozenset_test.py", line 12, in <module>
s.add(sub_s)
TypeError: unhashable type: 'set'
从输出信息可以知道,frozenset 集合可以添加到 set 集合中,但是 set 集合不能添加到 set 集合中去。这是因为 frozenset 集合是不可变的,而 set 集合是可变的。
2、双端队列(deque)
栈、队列、双端队列在数据结构中经常见到。栈是一种特殊的线性表,它只允许在一端进行插入、删除操作,这一端被称为栈顶(top),另一端则被称为栈底(bottom)。
从栈顶插入一个元素被称为进栈,将一个元素插入栈顶被称为“压入栈”,英文语言是 push。从栈顶删除一个元素被称为出栈,将一个元素从栈顶删除被称为“弹出栈”,英文语言是 pop。对于栈而言,最先入栈的元素位于栈底,只有等到上面所有元素都出栈之后,栈底的元素才能出栈。栈是一种后进先出(LIFO,Last in First out)的线性表。
队列(queue)也是一种特殊的线性表,它只允许在表的前端(front)进行删除操作,在表的后端(rear)进行插入操作。进行插入操作的端被称为队尾,进行删除操作的端被称为队头。队列的每个元素总是从队列的后端(rear)入队,从队列的前端(front)出队,因此队列的最后一个元素要出队,必须要等到前面的元素都出队后才能出队。队列是一种先进先出(FIFO,First in First out)的线性表。
双端队列(deque)是一种特殊的队列,它可以在两端同时进行插入、删除操作。如果将所有的插入、删除操作都固定在一端进行,那么这个双端队列就变成了栈;如果固定在一端只添加元素,在另一端只删除元素,那么它就变成了队列。因此,deque 可以被当成队列使用,也可以被当成栈使用。
deque 在 collections 包下,在交互式解释器中导入 collections 包,使用命令 [s for s in dir(collections.deque) if not s.startswith("_")] 可查看 deque 的全部用法,如下所示:
>>> import collections
>>> [s for s in dir(collections.deque) if not s.startswith("_")]
['append', 'appendleft', 'clear', 'copy', 'count', 'extend', 'extendleft', 'index', 'insert', 'maxlen', 'pop', 'popleft', 'remove', 'reverse', 'rotate']
由于 deque 是双端列队,所以对应的操作方法也都有两个版本。deque 的左边(left)相当于它的队列头(front),右边(right)相当于它的队列尾(rear)。其中:
(1)、append 和 appendleft:在 deque 的右边或左边添加元素,默认是在队列尾(右边)添加元素。
(2)、pop 和 popleft:在 deque 的右边或左边弹出元素,默认是在队列尾(右边)弹出元素。
(3)、extend 和 extendleft:在 deque 的右边或左边添加多个元素,默认在队列尾(右边)添加多个元素。
(4)、clear() 是清空队列;insert() 是线性表的方法,用于在指定位置插入元素。
例如要把 deque 当成队列使用(只在一端添加元素,另一个删除元素),则只需调用 append、popleft 方法既可。示例如下:
from collections import deque
q = deque(('linux', 'python'))
# 元素入队列,默认从右边入队
q.append('java')
q.append('JavaScript')
print('q 中的元素:', q) # 输出:deque(['linux', 'python', 'java', 'JavaScript'])
# 元素出队列,先添加的元素先出队列
print(q.popleft()) # 输出:linux
print(q.popleft()) # 输出:python
print(q) # 输出:deque(['java', 'JavaScript'])
运行代码,输出结果如下:
q 中的元素: deque(['linux', 'python', 'java', 'JavaScript'])
linux
python
deque(['java', 'JavaScript'])
上面代码的输出结果体现了队列的先进先出(FIFO)的特征。
(5)、rotate() 方法:将队列的队尾元素移动到队头,使之首尾相连。示例如下:
from collections import deque
d = deque(range(5))
print('d 中的元素:', d)
# 执行旋转,使之首尾相连
d.rotate()
print('d 中的元素:', d)
d.rotate()
print('d 中的元素:', d)
运行代码,输出结果如下:
d 中的元素: deque([0, 1, 2, 3, 4])
d 中的元素: deque([4, 0, 1, 2, 3])
d 中的元素: deque([3, 4, 0, 1, 2])
从输出结果可以看到,每次执行 rotate() 方法后,deuqeu 的队尾元素都会被移动到队头,这就形成了首尾相连的效果。
3、 Python 的堆操作
(1)、堆的概念:假设有 n 个数据元素的序列 k(0), k(1) ,..., k(n-1),当且仅当满足如下关系时,可以将这组数据称为小顶堆(也叫小根堆):
k(i) <= k(2i+1) 且 k(i) <= k(2i+2),其中 i=0,2,...,(n-1)/2
或者满意如下关系时,可将这组数据称为大顶堆(也叫大根堆):
k(i) >= k(2i+1) 且 k(i) >= k(2i+2),其中 i=0,2,...,(n-1)/2
对于满足小顶堆的数据序列 k(0),k(1),...,k(n-1),如果将它们顺序排成一棵完全二叉树,则此树的特点是:树中所有节点的值都小于其左、右子节点的值,此树的根节点的值必然是最小。反之,对于满足大顶堆的数据序列 k(0),k(1),...,k(n-1),如果将它们顺序排成一棵完全二叉树,则此树的特殊是:树中所有节点的值都大于其左、右子节点的值,此树的根节点的值必然最大。
小顶堆的任意子树也是小顶堆,大顶堆的任意子树还是大顶堆。Python 提供的是基于小顶堆的操作,因此可以对 list 中的元素进行小顶堆排列,这样每次获取堆中的元素时,总会取得堆中最小的元素。
例如,要判断数据序列 9,30,49,46,58,79 是否为堆,可将其转换为一棵完全二叉树,如下图所示。
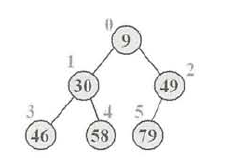
图一 完全二叉树
如上面图所示,每个节点圈旁边的数字表示该节点数据在底层数组中的索引。图中的完全二叉树完全满足小顶堆的特征,每个父节点的值总小于或等于它的左、右子节点的值。
在 Python 中没有 “堆” 这种数据类型,它是直接把列表当成堆处理的。Python 提供的 heapq 函数操作列表时,该列表会表现出“堆”的行为。在交互式解释器中先导入 heapq 包,使用命令heapq.__all__ 查看 heapq 包下的全部函数。示例如下:
>>> import heapq
>>> heapq.__all__
['heappush', 'heappop', 'heapify', 'heapreplace', 'merge', 'nlargest', 'nsmallest', 'heappushpop']
上面这些函数是执行堆操作的工具函数,这些函数大致功能如下:
(1)、heappush(heap,item):将 item 元素加入堆。
(2)、heappop(heap):将堆中最小元素弹出。
(3)、heapify(heap):将堆属性应用到列表上。
(4)、heapreplace(heap,x):将堆中最小元素弹出,并将元素 x 入堆。
(5)、merge(*iterables,key=None, reverse=False):将多个有序的堆合并成一大的有序堆,然后再输出。
(6)、heappushpop(heap,item):将 item 入堆,然后弹出并返回堆中最小的元素。
(7)、nlargest(n, iterable, key=None):返回堆中最大的 n 个元素。
(8)、nsmallest(n, iterable, key=None):返回堆中最小的 n 个元素。
关于这些函数的用法示例如下所示:
from heapq import *
my_data = list(range(10))
my_data.append(0.5)
print("my_data 的元素:",my_data)
# 对 my_data 应用堆属性
heapify(my_data)
print("应用堆之后 my_data 的元素:", my_data)
heappush(my_data, 7.2) # 将 7.2 入堆
print("添加 7.2后 my_data 的元素:", my_data)
运行结果如下所示:
my_data 的元素: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0.5]
应用堆之后 my_data 的元素: [0, 0.5, 2, 3, 1, 5, 6, 7, 8, 9, 4]
添加 7.2后 my_data 的元素: [0, 0.5, 2, 3, 1, 5, 6, 7, 8, 9, 4, 7.2]
上面代码在创建了 list 列表后,就调用 heapify() 函数对列表执行堆操作,执行堆操作后 my_data 列表的元素顺序是:
应用堆之后 my_data 的元素: [0, 0.5, 2, 3, 1, 5, 6, 7, 8, 9, 4]
这些元素的顺序看上去是无序的,但实际上它完全满足小顶堆的特征。将这些元素转换为完全二叉树,可以看到下图二的结果。
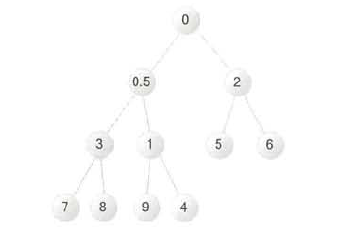
图二 小顶堆对应的完全二叉树
接下来调用 heapppush(my_data,7.2) 向堆中加入一个元素,输出 my_data 堆中的元素,输出结果是:
添加 7.2后 my_data 的元素: [0, 0.5, 2, 3, 1, 5, 6, 7, 8, 9, 4, 7.2]
此时将它转换为完全二叉树,可以看到图三的结果。
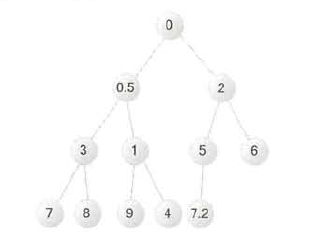
图片三 添加7.2后的小顶堆对应的完全二叉树
下面从堆中弹出两个元素:
# 弹出堆中最小的元素
print(heappop(my_data)) # 输出:0
print(heappop(my_data)) # 输出:0.5
print("弹出两个元素后my_data中的元素:", my_data)
这三行代码的输出结果如下:
0
0.5
弹出两个元素后my_data中的元素: [1, 3, 2, 7, 4, 5, 6, 7.2, 8, 9]
从上面输出的 my_data 的元素可知,此时 my_data 的元素依然满足小顶堆的特征。
关于 replace() 函数的用法:
# 弹出最小的元素,压入指定元素
print(heapreplace(my_data, 8.1))
print("执行replace之后my_data的元素:", my_data)
关于这两行代码的输出结果如下:
1
执行replace之后my_data的元素: [2, 3, 5, 7, 4, 8.1, 6, 7.2, 8, 9]
还可以通过 nlargest()、nsmallest() 来获取最大、最小的 n 个元素,示例如下:
print("my_data中最大的2个元素:", nlargest(2, my_data))
print("my_data中最小的3个元素:", nsmallest(3, my_data))
关于这两行代码的输出结果如下:
my_data中最大的2个元素: [9, 8.1]
my_data中最小的3个元素: [2, 3, 4]
由上面介绍可知,Python 的 heapq 包中提供的函数,就是提供了对排序算法中“堆排序”的支持。Python 通过在底层构建小顶堆,从而对容器中的元素进行排序,以便能快速的获取最小、最大的元素,使用起来很方便。
当要获取列表中最大的 n 个元素,或者最小的 n 个元素时,使用堆能缓存列表的排序结果,并且有较好的性能。
八、 collections 下的容器支持
在 collections 包中除了 deque 容器类外,还有一些其它的容器类,这些容器类不是很常用,但是在实际开发工作中也很实用,掌握这些容器类使编程更方便。
#### 1、 ChainMap 对象
ChainMap 是一个工具类,用链的方式将多个 dict “链” 在一起,在程序中可直接获取任意一个 dict 所包含的 key 对应的 value。ChainMap 表面上是将多个 dict 合并成一个大的 dict,但是在底层并没有真正合并这些 dict,不必调用多个 update() 方法将多个dict 进行合并。所以 ChainMap 是一种“假”合并,但在使用时又具有较好的效果。
要注意的是,使用 ChainMap 将多个 dict 链在一起时,可能存在 key 重复的情况,此时排在前面的 dict 中的 key 具有更高的优先级。关于 ChainMap 的用法示例如下:
from collections import ChainMap
# 首先定义三 dict 对象
a = {'linux': 78, 'python': 83}
b = {'python': 75, 'java': 69}
c = {'html': 80, 'JavaScript': 90}
# 下面将三个 dict 对象链在一起,变成一个大的 dict
cm = ChainMap(a, b, c)
print(cm)
# 获取 linux 对应的 value
print(cm['linux']) # 输出:78
# 获取 python 对应的 value
print(cm['python']) # 输出:83
# 获取 html 对应的 value
print(cm['html']) # 输出:80
运行代码,输出结果如下:
ChainMap({'linux': 78, 'python': 83}, {'python': 75, 'java': 69}, {'html': 80, 'JavaScript': 90})
78
83
80
从输出的第一行可知,ChainMap 实际上并没将这三个 dict 合并成一个大的dict,只是将它们链在一起而已。从输出的 python 对应的 value 可知,ChainMap 在合并多个 dict 对象后,排在前面的 key 有优先获取权。
示例一:
下面使用 ChainMap 将局部范围的定义、全局范围的定义、Python 内置定义链成一个 ChainMap,当通过该 ChainMap 获取变量时,将会按照局部定义、全局定义、内置定义的顺序执行搜索。代码如下:
import builtins
from collections import ChainMap
my_name = 'michael'
def test():
my_name = 'stark'
# 将 locals、globals、builtins 的变量链成 ChainMap
pylookup = ChainMap(locals(), globals(), vars(builtins))
# 访问 my_name 对应的 value,优先使用局部范围的定义
print(pylookup['my_name']) # stark
# 访问 len 对应的 value,找到的是在内置定义的 len 函数
print(pylookup['len']) # <built-in function len>
test()
示例二:
优先使用运行程序时输入的参数,然后是系统环境变量,最后是代码中定义的默认值。将这三个搜索范围链成 ChainMap。文件名称是chainmap_test3.py
import os, argparse
from collections import ChainMap
# 定义默认参数
defaults = {'color': '蓝色', 'user': 'michael'}
# 创建程序参数解析器
parser = argparse.ArgumentParser() # 初始化,创建实例
# 为参数解析器添加 -u(--user) 和 -c(--color) 参数
parser.add_argument('-u', '--user')
parser.add_argument('-c', '--color')
# 解析运行该文件时输入的参数
namespace = parser.parse_args() # 调用实例方法
print(namespace)
# 将运行该文件时输入的参数转换成 dict
command_line_args = {k:v for k, v in vars(namespace).items() if v}
# 使用 ChainMap 将 command_line_args、os.environ、default 链成大 dict
combined = ChainMap(command_line_args, os.environ, defaults)
# 获取 color 对应的 value
print(combined['color'])
# 获取 user 对应的 value
print(combined['user'])
# 获取 PYTHONPATH 对应的 value
print(combined['PYTHONPATH'])
上面代码中链接的顺序是 command_line_args、os.environ、defaults,其中 command_line_args 由运行该源代码文件时输入的参数解析而来,它的优先级最高。现在在命令行运行该源代码文件:
python chainmap_test3.py -c 红色 -u stark
上面命令中指定的 -c 对应于 color参数,-u 对应于 user参数,在命令行输入的参数优先级是最高的,输出结果如下所示:
Namespace(color='红色', user='stark')
红色
stark
.
上面输出中的最后一行是 PYTHONPATH 环境变量的值。如果在运行文件时不提供参数,如下所示:
python chainmap_test3.py
由于没有提供命令行参数,所以访问 user、color 时使用的是 defaults 字典中 key 对应的值,此时的输出结果如下:
Namespace(color=None, user=None)
蓝色
michael
.
2、 Counter 对象
Counter 对象也是 collections 包下一个很有用的工具类,它可以自动统计容器中各元素出现的次数。Counter 的本质是一个特殊的 dict,它的 key 是其所包含的元素,而它的 value 则记录了该 key 出现的次数。用 Counter 并不存在的 key 访问 value时,将会输出 0,表示 key 出现了 0 次。
在创建 Counter 对象时向其提供任何可迭代对象即可,此时 Counter 将会自动统计各元素出现的次数,并以元素为 key,出现的次数为 value 构建 Counter 对象;还能以 dict 为参数来构建 Counter 对象;还能通过关键字参数来构建 Counter 对象。示例如下:
# 导入 Counter 类
from collections import Counter
# 创建空的 Counter 对象
c1 = Counter()
print(c1)
# 创建 Counter 对象时传递字符串参数
c2 = Counter('fobobf')
print(c2)
# 创建 Counter 对象时传递列表参数
c3 = Counter(['python', 'go', 'python', 'linux', 'go', 'linux', 'python'])
print(c3)
# 创建 Counter 对象时传递字典参数
c4 = Counter({'red': 1, 'blue': 2})
print(c4)
# 使用关键字参数的语法创建 Counter
c5 = Counter(python=5, linux=10)
print(c5)
运行代码,输出结果如下:
Counter()
Counter({'f': 2, 'o': 2, 'b': 2})
Counter({'python': 3, 'go': 2, 'linux': 2})
Counter({'blue': 2, 'red': 1})
Counter({'linux': 10, 'python': 5})
查看 Counter 类的源代码可知,它继承了 dict 类,因此它完全可以调用 dict 支持的方法。除此之外,Counter 类还提供下面三个常用的方法:
(1)、elements():该方法返回该 Counter 所包含的全部元素组成的迭代器。
(2)、most_common([n]):该方法返回 Counter 中出现最多的 n 个元素。
(3)、subtract([iterable-or-mapping]):该方法计算 Counter 的减法,其实就是计算减去之后各元素出现的次数。
关于 Counter 类的这几个方法的使用示例如下:
from collections import Counter
# 创建 Counter 对象
cnt = Counter()
# 访问并不存在的 key时,将输出该 key 的次数为 0
print(cnt['python']) # 0
for word in ['go', 'python', 'java', 'python', 'go', 'html']:
cnt[word] += 1
print(cnt)
# 只访问 Counter 对象的元素,由于返回的是迭代器,可转换成列表、元组等
print(tuple(cnt.elements()))
# 将字符串(可迭代对象)转换成 Counter
chr_cnt = Counter('abracadabra')
# 获取出现最多的三个字母
print(chr_cnt.most_common(3)) # [('a', 5), ('b', 2), ('r', 2)]
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
# 用 Counter 对象执行减法,其实是在减少各元素出现的次数
c.subtract(d)
print(c) # Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})
e = Counter({'x': 2, 'y': 3, 'z': -4})
# 调用 del 删除 key-value 对,会真正删除该 key-value 对
del e['y']
print(e) # Counter({'x': 2, 'z': -4})
# 访问 'w' 对应的 value,因 'w' 没有出现过,所以返回 0
print(e['w']) # 0
# 删除 e['w'],删除该 key-value 对
del e['w']
# 再次访问 'w' 对应的 value,还是返回 0
print(e['w']) # 0
运行代码,输出结果如下:
0
Counter({'go': 2, 'python': 2, 'java': 1, 'html': 1})
('go', 'go', 'python', 'python', 'java', 'html')
[('a', 5), ('b', 2), ('r', 2)]
Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})
Counter({'x': 2, 'z': -4})
0
0
由上面的输出可知,Counter 对象的 elements() 方法返回容器中所有元素组成的迭代器。在 Counter 中记录了元素出现的次数,elements() 方法根据元素出现的次数返回对应数量的元素组成的迭代器。most_common(3) 方法返回容器中出现次数最多的三个元素。subtract() 方法是对元素出现的次数执行减法。
Counter 对象还有一些常用操作,比如把 Counter 对象转换成 set(集合)、list(列表)、dict(字典)等,还可对 Counter 执行加、减、交、并运算,以及求正、求负运算等。Counter 执行这些运算的含义如下:
(1)、加(+):将两个 Counter 对象中各 key 出现的次数相加,且只保留出现次数为正的元素。
(2)、减(-):将两个 Counter 对象中各 key 出现的次数相减,且只保留出现次数为正的元素。
(3)、交(&):取两个 Counter 对象中都出现的 key 且各 key 对应的次数的最小数。
(4)、并(|):取两个 Counter 对象中各 key 对应的出现次数的最大数,摒弃掉次数为负数的 key-value 对。
(5)、求正:只保留 Counter 对象中出现次数为 0 或正数的 key-value 对。
(6)、求负:只保留 Counter 对象中出现次数为负数的 key-value 对,并将出现次数改为正数。
关于 Counter 对象的这些常用操作示例如下:
from collections import Counter
c = Counter(python=4, linux=2, hmtl=3, go=-2)
# 统计 Counter 中所有元素出现次数的总和
print(sum(c.values())) # 7
# 将 Counter 转换为 list , 只保留 key
print(list(c)) # ['python', 'linux', 'hmtl', 'go']
# 将 Counter 转换为 set,只保留各 key
print(set(c)) # {'linux', 'go', 'python', 'hmtl'}
# 将 Counter 转换为 dict
print(dict(c)) # {'python': 4, 'linux': 2, 'hmtl': 3, 'go': -2}
# 将 Counter 转换为 list,列表元素由 (元素, 出现次数) 的元组形式组成
list_of_pairs = c.items()
print(list_of_pairs) # dict_items([('python', 4), ('linux', 2), ('hmtl', 3), ('go', -2)])
# 将列表元素为 (元素, 出现次数) 组的 list 转换成 Counter
c2 = Counter(dict(list_of_pairs))
print(c2) # Counter({'python': 4, 'hmtl': 3, 'linux': 2, 'go': -2})
# 获取 Counter 中最少出现的三个元素
print(c.most_common()[:-4:-1]) # [('go', -2), ('linux', 2), ('hmtl', 3)]
# 清空所有 key-value 对
c.clear()
print(c) # Counter()
c = Counter(a=3, b=1, c=-1)
d = Counter(a=1, b=-2, d=3)
# 对 Counter 执行加法,只保留出现次数为正的元素
print(c + d) # Counter({'a': 4, 'd': 3})
# 对 Counter 执行减法,只保留出现次数为正的元素
print(c - d) # Counter({'b': 3, 'a': 2})
# 对 Counter 对象执行交运算,两个 Counter 对象都出现的 key 且对应的次数是最小数
print(c & d) # Counter({'a': 1})
# 对 Counter 对象执行并运算,各 key 出现次数的最大数,摒弃掉次数为负数的 key
print(c | d) # Counter({'a': 3, 'd': 3, 'b': 1})
# 对 Counter 对象执行求正运算,只保留出现次数为0或正数的 key-value
print(+ c) # Counter({'a': 3, 'b': 1})
# 对 Counter 对象执行求负运算,只保留出现次数为负数的 key-value对,并将出现次数改为正数
print(- d) # Counter({'b': 2})
上面代码中使用了 Counter 的各种通用方法和运算符,根据这个代码示例加深对 Counter 对象的方法和运算符功能的理解。
3、 defaultdict 对象
defaultdict 是 dict 的子类,defaultdict 可当成 dict 来使用,dict 支持的功能在 defaultdict 基本都支持。两者最大区别是 dict 获取不存在的 key 的 value 时会引发 KeyError 异常;而 defaultdict 则可以提供一个 default_factory 属性,该属性所指定的函数负责为不存在的 key 来生成 value。两者的对比示例如下所示:
from collections import defaultdict
my_dict = {} # 创建一个空字典对象
# 下面创建一个空的 defaultdict 对象,并使用 int 作为 defaultdict 的 default_factory
# 即当 key 不存在时,将会返回 int 函数的返回值
my_defaultdict = defaultdict(int)
print(my_defaultdict['a']) # 0
print(my_dict['a']) # KeyError
上面代码中创建了一个空的 dict 对象和空的 defaultdict 对象,接下来访问 defaultdict 中不存在的 key 对应的 value 时,就会输出 defaultdict 的 default_factory 属性(int函数)的返回值 0;如果访问 dict 中不存在的 key 对应的 value,就会引发 KeyError 异常。
对于使用 defaultdict 的简单应用:假设有一个包含多个 key-value 对的元组列表,这些 key-value 对中有些 key 是重复的,现在对这些 key-value 对进行整理。一个 key 对应一个 list,list 的元素就是这个 key 对应的所有 value。首先使用普通的dict 来完全这个任务。代码如下:
s = [('python', 1), ('linux', 2), ('python', 3), ('linux', 4), ('python', 5)]
d = {}
for k, v in s:
# 字典的 setdefault() 方法获取指定 key 对应的 value
# 如果 key 不存在,则先将该 key 对应的 value 设置为默认值:[]
d.setdefault(k, []).append(v)
print(list(d.items()))
上面代码运行结果如下:
[('python', [1, 3, 5]), ('linux', [2, 4])]
上面代码中,使用 dict 的 setdefault() 方法来处理 key 不存在情况,这个方法获取指定 key 对应的 value,但如果该 key 不存在,setdefault() 方法就会先为该 key 设置一个默认的 value。
对于上面这个任务使用 defaultdict 来处理会更简单一些,可以在创建 defaultdict 对象时传递一个 list 参数,这样当 key 不存在时就会设置默认的 value(就是 list),代码如下所示:
from collections import defaultdict
s2 = [('python', 1), ('linux', 2), ('python', 3), ('linux', 4), ('python', 5)]
# 创建 defaultdict 对象,设置由 list 参数来生成默认值
sd = defaultdict(list)
for k, v in s2:
# 此时直接访问 defaultdict 中指定的 key 对应的 value 即可
# 如果该 key 不存在,defaultdict 会自动根据创建对象时提供的参数来为该 key 生成默认值
sd[k].append(v)
print(list(sd.items()))
上面代码运行结果如下:
[('python', [1, 3, 5]), ('linux', [2, 4])]
上面代码中使用 defaultdict 类创建对象时传递了一个 list 参数,这样在后面的代码中直接访问 defaultdict 中不存在的 key 对应的 value 时,就会根据创建 defaultdict 对象时传入的 list 函数来生成默认的 value。
4、 namedtuple 工厂函数
namedtuple() 是一个工厂函数,可以用来创建一个 tuple 类的子类,该子类可以为 tuple 的每个元素指定字段名,可通过指定的字段名来访问 namedtuple 的各元素。当然,使用索引来访问 namedtuple 的各元素也是可以的。
namedtuple 是轻量级的,性能很好,比普通的 tuple 占用更少的内存。namedtuple 函数的语法格式如下:
namedtuple(typename, field_names, *, verbose=False, rename=False, module=None)
该函数的参数说明如下:
(1)、typename:该参数指定所创建的 tuple 子类的类名,相当于用户定义一个新类。
(2)、field_names:该参数是一个字符串序列,如 ['x', 'y']。此外,field_names 也可直接使用单个字符串代表所有字段名,多个字段名用空格、逗号隔开,如 'x y' 或 'x,y'。任何有效的 Python 标识符都可作为字段名(不能以下划线开头)。有效的标识符由字母、数字、下划线组成,但不能以数字、下划线开头,也不能是关键字(如pass、raise、class、return等)。
(3)、rename:默认为 False ,如果设置为 True,那么无效的字段名将会被自动替换为位置名。例如指定['abc', 'def', 'ghi', 'abc'],它将会被替换为 ['abc', '_1', 'ghi', '_3'],这是因为 def 字段是关键字,而 abc 字段名重复。
(4)、verbose:默认为 False ,如果设置为 True,那么当该子类被创建后,该类定义就会被立即打印出来。
(5)、module:如果设置了该参数,那么该类将位于该模块下,因此该自定义类的
__module__属性将被设为参数值。
下面使用 namedtuple 工厂函数来创建命名元组,示例如下:
from collections import namedtuple
# 定义命名元组类:Point
Point = namedtuple('Point', ['x', 'y'])
# 初始化 Point 对象,既可用位置参数,也可用命名参数
p = Point(11, y=12)
# 像普通元组一样根据索引访问元素
print(p[0] + p[1]) # 23
# 可以执行元组解包,按元素的位置觖包
a, b = p
print(a, b) # 11 12
# 根据字段名访问各元素
print(p.x + p.y) # 23
print(p) # Point(x=11, y=12)
从上面的代码可知,要使用命名元组类的顺序是:
- (1)先创建一个命令元组类,需要指定类名和字段名;
- (2)根据第一步创建的命名元组类初始化(或创建实例)命名元组对象;
- (3)像访问普通元组元素一样访问命名元组元素,也可通过字段名访问其元素。
根据这个顺序,上面代码中首先创建了一个命名元组类 Point,它是 tuple 的子类;接着是创建 Point 对象,因为 Point 代表的是一个命名元组,就像 tuple 类一样;接下来就是访问命名元组的元素,用法与普通元组一样。
当然,命名元组还有下面这些方法和属性可供使用:
(1)、_make(iterable):类方法。该方法用于根据序列或可迭代对象创建命名元组对象。
(2)、_asdict():将当前命名元组对象转换为 OrderedDict 字典。
(3)、_replace(**kwargs):替换命名元组中一个或多个字段的值。
(4)、_source:该属性返回定义该命名元组的源代码。
(5)、_fields:该属性返回该命名元组中所有字段名组成的元组。
关于上面这些方法和属性的用法示例如下:
from collections import namedtuple
# 定义命名元组类:Point
Point = namedtuple('Point', ['x', 'y'])
my_data = ['East', 'North']
# 创建命名元组对象
p2 = Point._make(my_data)
print(p2) # Point(x='East', y='North')
# 将命名元组对象转换成 OrderedDict
print(p2._asdict()) # OrderedDict([('x', 'East'), ('y', 'North')])
# 替换命名元组对象的字段值
p2._replace(y='South')
print(p2) # Point(x='East', y='North')
# 输出 p2 包含的所有字段
print(p2._fields) # ('x', 'y')
# 定义一个命名元组类
Color = namedtuple('Color', 'red green blue')
# 再定义一个命名元组类,其字段由 Point 的字段加上 Color 的字段组成
Pixel = namedtuple('Pixel', Point._fields + Color._fields)
# 创建 Pixel 对象,分别为 x、y、red、green、blue 字段赋值
pix = Pixel(11, 22, 128, 255, 0)
print(pix) # Pixel(x=11, y=22, red=128, green=255, blue=0)
运行代码,输出结果如下:
Point(x='East', y='North')
OrderedDict([('x', 'East'), ('y', 'North')])
Point(x='East', y='North')
('x', 'y')
Pixel(x=11, y=22, red=128, green=255, blue=0)
5、 OrderedDict 对象
- OrderedDict 是 dict(字典)的子类
- OrderedDict 是一个在序的字典,默认字典是无序的,但是 OrderedDict 的字典对象是有序的。
- 在 OrderedDict 中,先添加 key-value 对排在前面,后添加的排在后面。
- 两个 OrderedDict 对象中的 key-value 完全相同,但顺序不同时,在判断它们是否相等时依然会返回 False。
from collections import OrderedDict
# 创建 OrderedDict 对象
dx = OrderedDict(x=1, y=2, z=3)
print(dx) # OrderedDict([('x', 1), ('y', 2), ('z', 3)])
# 创建一个空的 OrderedDict 对象 d
d = OrderedDict()
# 向对象 d 中添加 key-value 对
d['python'] = 90
d['linux'] = 88
d['java'] = 85
d['html'] = 80
# 你遍历普通字典一样,可以遍历 OrderedDict 的 key-value 对
for k, v in d.items():
print(k, v)
运行代码,输出如下:
OrderedDict([('x', 1), ('y', 2), ('z', 3)])
python 90
linux 88
java 85
html 80
上面代码中创建了一个 OrderedDict 对象 d,并向 d 中添加了 4 个key-value 对,从输出可以看出,输出的顺序和添加的顺序是一样的,所以 OrderedDict 可以记住它们的添加顺序。
此外,两个 OrderedDict 对象中即使有完全相同的 key-value 对,但只要它们的顺序不同,依然会判断这两个 OrderedDict 是不相等的,也就是说两个 OrderedDict 不是同一个对象。示例如下:
# 创建一个普通的 dict 对象
my_data = {'python': 10, 'linux': 20, 'html': 30, 'java': 40}
# 创建基于key 排序的 OrderedDict
d1 = OrderedDict(sorted(my_data.items(), key=lambda t: t[0]))
# 创建基于 value 排序的 OrderedDict
d2 = OrderedDict(sorted(my_data.items(), key=lambda t: t[1]))
print(d1)
print(d2)
print(d1 == d2) # False
运行这段代码,输出如下:
OrderedDict([('html', 30), ('java', 40), ('linux', 20), ('python', 10)])
OrderedDict([('python', 10), ('linux', 20), ('html', 30), ('java', 40)])
False
上面代码分别使用普通 dict 对象的 key 和 value 的排序结果来创建两个 OrderedDict 对象 d1 和 d2,这两个对象中的 key-value 对是完全一样,只不过顺序不同。从输出可以看到,虽然两个 OrderedDict 对象的 key-value 完全一样,但是它们仍然是不相等的。
由于 OrderedDict 是有序的,所以 OrderedDict 对象还有下面两个方法可以使用:
(1)、popitem(last=True):默认弹出并返回最右边(最后加入)的 key-value 对;如果将 last 参数设置 False,则弹出并返回最左边(最先加入)的 key-value 对。
(2)、move_to_end(key, last=True):默认将指定的 key-value 对移动到最右边(最后加入);如果将 last 改为 False,则将指定的 key-value 对移动到最左边(最先加入)。
关于这两个方法的使用示例如下:
a = OrderedDict.fromkeys('abcde')
print(a) # OrderedDict([('a', None), ('b', None), ('c', None), ('d', None), ('e', None)])
# 将 c 对应的 key-value 对移动到最右边(最后加入)
a.move_to_end('c')
print(a.keys()) # odict_keys(['a', 'b', 'd', 'e', 'c'])
# 将 c 对应的 key-value 移动到最左边(最先加入)
a.move_to_end('c', last=False)
print(a.keys()) # odict_keys(['c', 'a', 'b', 'd', 'e'])
# 弹出并返回最右边的 key-value 对
print(a.popitem()[0]) # e
# 弹出并返回最左边的 key-value 对
print(a.popitem(last=False)[0]) # c
运行代码,输出结果如下:
OrderedDict([('a', None), ('b', None), ('c', None), ('d', None), ('e', None)])
odict_keys(['a', 'b', 'd', 'e', 'c'])
odict_keys(['c', 'a', 'b', 'd', 'e'])
e
c
从上面的输出可以看到,使用 OrderedDict 的 move_to_end() 方法可以方便地将指定的 key-value 对移动到 OrderedDict 的任意一端;而 popitem() 方法可用于弹出并返回 OrderedDict 任意一端的 key-value 对。
九、 函数相关的模块
Python 是支持函数式编程的,且还提供了一些与函数相关的模块。
1、 itertools 模块的功能函数
itertools 模块中主要包含一些用于生成迭代器的函数。在交互式解释器中可查看该模块包含的全部属性和函数。
>>> import itertools
>>> [s for s in dir(itertools) if not s.startswith("_")]
['accumulate', 'chain', 'combinations', 'combinations_with_replacement', 'compress', 'count', 'cycle','dropwhile', 'filterfalse', 'groupby', 'islice', 'permutations', 'product', 'repeat', 'starmap','takewhile', 'tee', 'zip_longest']
itertools 模块中不少函数都可用于生成迭代器。下面三个是生成无限迭代器的函数。
(1)、count(start,[step]):生成 start,start+step,start+2*step,...的迭代器,其中 step 默认为 1。比如使用count(10) 生成的迭代器包含:10,11,12,13,14,...。
(2)、cycle(p):对序列 p 生成无限循环 p0,p1,...,p0,p1,... 的迭代器。比如使用 cycle('ABC') 生成的迭代器包含:A,B,C,A,B,C,...。
(3)、repeat(elem, [,n]):生成无限个 elem 元素重复的迭代器,如果指定了参数 n,则只生成 n 个 elem 元素。例如使用repeat(10,3) 生成的迭代器包含:10,10,10。
关于上面3个函数的示例如下:
import itertools as it
# 使用 count(10,3) 生成10,13,16,... 的迭代器
for e in it.count(10, 3):
print(e)
# 用于跳出无限循环
if e > 20:
break
print('-' * 20)
my_counter = 0
# cycle 用于对序列生成无限循环的迭代器
for e in it.cycle(['python', 'html', 'linux']):
print(e)
# 用于控制循环退出
my_counter += 1
if my_counter > 7:
break
print('-' * 20)
# repeat 用于生成 n 个元素重复的迭代器
for e in it.repeat('python', 3):
print(e)
运行上面代码,输出如下:
10
13
16
19
22
--------------------
python
html
linux
python
html
linux
python
html
--------------------
python
python
python
itertools 模块中还有一些常用迭代器函数,如下所示:
(1)、accumulate(p, [,func]):默认生成根据序列 p 元素累加的迭代器,p0,p0+p1,p0+p1+p2,... 序列,如果指定了 func 函数,则用 func 函数来计算下一个元素的值。
(2)、chain(p, q,...):将多个序列里的元素“链”在一起生成新的序列。
(3)、compress(data, selector):根据 selectors 序列的值对 data 序列的元素进行过滤。如果 selector[0] 为真,则保留data[0];如果 selector[1] 为真,则保留 data[1],......,以此类推。
(4)、dropwhile(pred, seq):使用 pred 函数对 seq 序列进行过滤,从 seq 中第一个使用 pred 函数计算为 False 的元素开始,保留从该元素到序列结束的全部元素。
(5)、takewhile(pred, seq):该函数和上一个函数恰好相反。使用 pred 函数对 seq 序列进行过滤,从 seq 中第一个使用 pred 函数计算为 False 的元素开始,去掉从该元素到序列结束的全部元素。
(6)、filterfalse(pred, seq):使用 pred 函数对 seq 序列进行过滤,保留 seq 中使用 pred 计算为 True 的元素。比如 filterfalse(lambda x: x%2, range(10)) 得到 0,2,4,6,8。
(7)、islice(seq, [start,] stop [, step]):其功能类似于序列的 slice 方法,实际上就是返回 seq[start:stop:step]的结果。
(8)、starmap(func, seq):使用 func 对 seq 序列的每个元素进行计算,将计算结果作为新的序列元素。当使用 func 计算序列元素时,支持序列解包。比如 seq 序列的元素长度为 3,那么 func 可以是一个接收三个参数的函数,该函数将会根据这三个参数来计算新序列的元素。
(9)、zip_longest(p, q, ..., fillvalue=None):将 p、q 等序列中的元素按索引合并成元组,这些元组将作为新序列的元素。当序列元素长度不相等时,使用 fillvalue 参数的字符串代替。
关于上面这些函数的用法示例如下:
import itertools as it
# 默认使用累加的方式计算下一个元素的值
for e in it.accumulate(range(5)):
print(e, end=', ') # 0, 1, 3, 6, 10,
print('\n','-'* 20)
# 使用 x*y 的方式来 计算迭代器下一个元素的值
for e in it.accumulate(range(1, 6), lambda x, y: x * y):
print(e, end=', ') # 1, 2, 6, 24, 120,
print('\n','-'* 20)
# 将两个序列“链”在一起,生成新的迭代器
for e in it.chain(['a', 'b'], ['py', 'html']):
print(e, end=', ') # a, b, py, html,
print('\n','-'* 20)
# 根据第二个序列来筛选第一个序列的元素
# 由于第二个序列只有中间两个元素为1(True),因此第一个序列只保留中间两个元素
for e in it.compress(['a', 'b', 'py', 'html'], [0, 1, 1, 0]):
print(e, end=', ') # b, py,
print('\n','-'* 20)
# 获取序列中长度不于 4 的元素开始到结束的所有元素,也就是去掉满足条件之前的元素
for e in it.dropwhile(lambda x: len(x) < 4, ['a', 'b', 'python', 'x', 'y']):
print(e, end=', ') # python, x, y,
print('\n','-'* 20)
# 去掉序列中从长度不小于4 的元素开始到结束的所有元素,也就是去掉满足条件之后的元素
for e in it.takewhile(lambda x: len(x) < 4, ['a', 'b', 'python', 'x', 'y']):
print(e, end=', ') # a, b,
print('\n','-'* 20)
# 只保留序列中长度不小于 4 的元素,也就是去掉满足条件的元素
for e in it.filterfalse(lambda x: len(x) < 4, ['a', 'b', 'python', 'x', 'y']):
print(e, end=', ') # python,
print('\n','-'* 20)
# 使用 pow 函数对原序列的元素进行计算,将计算结果作为新序列的元素
for e in it.starmap(pow, [(2, 5), (3, 2), (10, 3)]):
print(e, end=', ') # 32, 9, 1000,
print('\n','-'* 20)
# 将 ‘ABCD’、'xy' 的元素按索引合并成元组,这些元组将作为新序列的元素
# 长度不够的序列元素使用 '-' 字符代替
for e in it.zip_longest('ABCD', 'xy', fillvalue='-'):
print(e, end=', ') # ('A', 'x'), ('B', 'y'), ('C', '-'), ('D', '-'),
运行上面代码,输出结果如下:
0, 1, 3, 6, 10,
--------------------
1, 2, 6, 24, 120,
--------------------
a, b, py, html,
--------------------
b, py,
--------------------
python, x, y,
--------------------
a, b,
--------------------
python,
--------------------
32, 9, 1000,
--------------------
('A', 'x'), ('B', 'y'), ('C', '-'), ('D', '-'),
在 itertools 模块中,还有一些用于生成排列组合的工具函数:
(1)、product(p, q, ..., [repeat=1]):用序列 p、q、... 中的元素进行排列组合,就相当于使用嵌套循环组合。
(2)、permutations(p [, r]):从序列 p 中取出 r 个元素组成全排列,将排列得到的元组作为新迭代器的元素。
(3)、combinations(p, r):从序列 p 中取出 r 个元素组成全组合,元素不允许重复,将组合得到的元组作为新迭代器的元素。
(4)、combinations_with_replacement(p, r):从序列 p 中取出 r 个元素组成全组合,元素允许重复,将组合得到的元组作为新迭代器的元素。
关于上面4个函数的用法示例如下:
import itertools as it
# 使用两个序列进行排列组合
for e in it.product('AB', 'XY'):
print(''.join(e), end=', ') # AX, AY, BX, BY,
print('\n----------')
# 使用一个序列,重复两次进行全排列
for e in it.product('AB', repeat=2):
print(''.join(e), end=', ') # AA, AB, BA, BB,
print('\n----------')
# 从序列中取两个元素进行排列
for e in it.permutations('ABCD', 2):
print(''.join(e), end=', ') # AB, AC, AD, BA, BC, BD, CA, CB, CD, DA, DB, DC,
print('\n----------')
# 从序列中取两个元素进行组合,元素不允许重复
for e in it.combinations('ABCD', 2):
print(''.join(e), end=', ') # AB, AC, AD, BC, BD, CD,
print('\n----------')
# 从序列中取两个元素进行组合,元素允许重复
for e in it.combinations_with_replacement('ABCD', 2):
print(''.join(e), end=', ') # AA, AB, AC, AD, BB, BC, BD, CC, CD, DD,
运行代码,输出如下所示:
AX, AY, BX, BY,
----------
AA, AB, BA, BB,
----------
AB, AC, AD, BA, BC, BD, CA, CB, CD, DA, DB, DC,
----------
AB, AC, AD, BC, BD, CD,
----------
AA, AB, AC, AD, BB, BC, BD, CC, CD, DD,
上面代码中用到一个字符串的 join() 方法,该方法用于将元组的所有元素连接成一个字符串。
2、functools 模块的功能函数
在 functools 模块中包含了一些函数装饰器和便捷的功能函数。在交互式解释器用下面方式查看该模块的所包含的全部属性和函数。
>>> import functools
>>> [s for s in dir(functools) if not s.startswith("_")]
['MappingProxyType', 'RLock', 'WRAPPER_ASSIGNMENTS', 'WRAPPER_UPDATES', 'WeakKeyDictionary', 'cmp_to_key', 'get_cache_token', 'lru_cache', 'namedtuple', 'partial', 'partialmethod', 'recursive_repr', 'reduce','singledispatch', 'total_ordering', 'update_wrapper', 'wraps']
functools 模块中常用的函数装饰器和功能函数如下:
(1)、functools.cmp_to_key(func):将老式的比较函数(func)转换为关键字函数(key function)。Python 3中比较大小、排序都是基于关键字函数的,Python 3不支持老式的比较函数。
比较函数接收两个参数,比较这两个参数并根据它们的大小关系返回负值(代表前者小于后者)、零或正值(代表前者大于后者);关键字函数则只需要一个参数,通过该参数可返回一个用于排序关键字的值。
(2)、@functools.lru_cache(maxsize=128,typed=False):该函数装饰器使用 LRU(最近最少使用)缓存算法来缓存相对耗时的函数结果,避免传入相同的参数重复计算。同时,缓存并不会无限增长,不用的缓存会被释放。其中 maxsize 参数用于设置缓存占用的最大字节数,typed 参数用于设置将不同类型的缓存结果分开存放。
(3)、@functools.total_ordering:这个类装饰器(作用类似于函数装饰器,只是作用于修饰类)用于为类自动生成比较方法。通常只要提供 __lt__()、__le__()、__gt__()、__ge__() 其中之一(最好能提供 __eq__()方法),@functools.total_orering 装饰器就会为该类生成剩下的比较方法。
(4)、functools.partial(func, *args, **kwargs):该函数用于为 func 函数的部分参数指定参数值,从而得到一个转换后的函数,程序以后调用转换后的函数时,就可以少传入那些已经指定值的参数。
(5)、functools.partialmethod(func, *args, **kwargs):该函数与上一个函数的含义完全相同,只不过该函数用于为类中的方法设置参数值。
(6)、functools.reduce(function, iterable[,initializer]):将初始值(默认为0,可由 initializer 参数指定)、迭代器的当前元素传入 function 函数,将计算出来的函数结果作为下一次计算的初始值、迭代器的下一个元素再次利用 function 函数 ······ 依此类推,直到迭代器的最后一个元素。
(7)、@functools.singledispatch:该函数装饰器用于实现函数对多个类型进行重载。比如同样的函数名称,为不同的参数类型提供不同的功能实现。该函数的本质就是根据参数类型的变换,将函数转向调用不同的函数。
(8)、functools.update_wrapper(wrapper, wrapped, assigned=WRAPPER_ASSIGNMENTS, updated=WRAPPER_UPDATES):对 wrapper 函数进行包装,使之看上去就像 wrapped(被包装)函数。
(9)、@functools.wraps(wrapped, assigned=WRAPPER_ASSIGNMENTS, updated=WRAPPER_UPDATES):该函数装饰器用于修饰包装函数,使包装函数看上去就像 wrapped 函数。
注意:functools.update_wrapper 和 @functools.wraps 的功能是一样的,只不过前者是函数,因此需要把包装函数作为第一个参传入;而后者是函数装饰器,因此使用该函数装饰器修饰包装函数即可,无须将包装函数作为第一个参数传入。
functools 模块中部分函数或函数装饰器的用法如下:
from functools import *
# 设初始值(默认为0)为 x,当前序列元素为 y,将 x+y 的和作为下一次计算的初始值
# 相当于 0+0+1+2+3+4=10
print(reduce(lambda x,y: x+y, range(5))) # 10
# 相当于 0+0+1+2+3+4+5=15
print(reduce(lambda x,y: x+y, range(6))) # 15
# 设初始值为是 10,相当于 10+0+1+2+3+4+5=25
print(reduce(lambda x,y: x+y, range(6), 10)) # 25
print('-' * 20)
class User:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'User[name=%s]' % self.name
# 定义一个老式的大小比较函数,User 的 name 越长。该 User 越大
def old_cmp(u1, u2):
return len(u1.name) - len(u2.name)
my_data = [User('Python'), User('Linux'), User('Go'), User('Java')]
# 对 my_data 排序,需要关键字函数(调用 cmp_to_key 将 old_cmp 转换为关键字函数)
my_data.sort(key=cmp_to_key(old_cmp))
# my_data 都是User类对象,当调用 print 时,根据 __repr__ 的返回值输出
print(my_data) # [User[name=Go], User[name=Java], User[name=Linux], User[name=Python]]
print('-' * 20)
@lru_cache(maxsize=32)
def factorial(n):
print('~~计算 %d 的阶乘~~' % n)
if n == 1:
return 1
else:
return n * factorial(n - 1)
# 只有下面这行会计算,然后会缓存5、4、3、2、1的阶乘
print(factorial(5)) # 会输出 ~~计算 1-5 的阶乘~~,最后输出 120
print(factorial(3)) # 只输出:6
print(factorial(5)) # 只输出:120
print('-' * 20)
# int 函数默认将十进制形式的字符串转换为整数
print(int('12345')) # 123456
# 为 int 函数的 base 参数指定参数值
basetwo = partial(int, base=2)
basetwo.__doc__ = '将二进制形式的字符串转换成整数'
# 相当于执行 base 为 2 的 int 整数
print(basetwo('10010')) # 18
print(int('10010', 2)) # 18
运行上面代码,输出如下:
10
15
25
--------------------
[User[name=Go], User[name=Java], User[name=Linux], User[name=Python]]
--------------------
~~计算 5 的阶乘~~
~~计算 4 的阶乘~~
~~计算 3 的阶乘~~
~~计算 2 的阶乘~~
~~计算 1 的阶乘~~
120
6
120
--------------------
12345
18
18
上面代码中的 print(reduce(lambda x,y: x+y, range(5))) 行代码调用 reduce() 函数来计算序列的 “累计” 结果,在调用该函数时传入的第一个参数(函数)决定了累计算法,这里使用的累计算法是 “累加”。
上面代码中的 my_data.sort(key=cmp_to_key(old_cmp)) 行代码调用 cmp_to_key() 函数将老式的大小比较函数(old_cmp)转换为关键字函数,这样该关键字函数即可作为列表对象的 sort() 方法的参数。
上面代码中的 @lru_cache(maxsize=32) 行代码调用 @lru_cache 对函数结果进行缓存,后面程序第一次执行 factorial(5) 时会看到执行结果;但接下来调用 factorial(3)、factorial(5)时都不会看到执行结果,因为它们的结果已被缓存起来。
上面代码中的 basetwo = partial(int, base=2) 行代码调用 partial() 函数为 int() 函数的 base 参数绑定值 “2”,这样在后面调用该函数时实际上就相当于调用 base 为 2 的 int() 函数。所以,print(basetwo('10010')) 和 print(int('10010', 2)) 的本质是完全一样的,输出结果也是一样的。
partialmethod() 与 partial() 函数的作用基本相似,不同的是 partial() 函数用于为函数的部分参数绑定值;而 partialmethod() 函数则用于为类中方法的部分参数绑定值。示例如下:
from functools import *
class Cell:
def __init__(self):
self._alive = False
# @property 装饰器指定该可使用属性语法访问
@property
def alive(self):
return self._alive
def set_state(self, state):
self._alive = bool(state)
# 指定 set_alive() 方法,就是将 set_state() 方法的 state 参数指定为 True
set_alive = partialmethod(set_state, True)
# 指定 set_dead() 方法,就是将 set_state() 方法的 state 参数指定为 False
set_dead = partialmethod(set_state, False)
c = Cell()
print(c.alive) # False
# 下面代码相当于调用 c.set_state(True)
c.set_alive()
print(c.alive) # True
# 下面代码相当于调用 c.set_state(False)
c.set_dead()
print(c.alive) # False
上面代码中定义了一个细胞(cell)类,该类的 set_state() 方法用于设置该细胞的状态。接下来的 set_alive = partialmethod(set_state, True) 和 set_dead = partialmethod(set_state, False) 两行代码使用 partialmethod() 函数为 set_state() 方法绑定了参数值;将 set_state() 方法的参数值绑定为 True 之后赋值给 set_alive() 方法;将 set_state() 方法的参数值绑定为 False 之后赋值给了 set_dead() 方法。因此,当调用 c.set_alive() 就相当于调用 c.set_state(True);当调用 c.set_dead() 就相当于调用 c.set_state(False)。
关于 @total_ordering 类装饰器的作用示例如下:
from functools import *
@total_ordering
class User:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'User[name=%s]' % self.name
# 根据是否有 name 属性来决定是否可比较
def _is_valid_operand(self, other):
return hasattr(other, 'name')
def __eq__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
# 根据 name 判断是否相等,转换为小写来比较、忽略大小写
return self.name.lower() == other.name.lower()
def __lt__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
# 根据 name 判断是否相等,转换为小写来比较、忽略大小写
return self.name.lower() < other.name.lower()
# 打印被装饰之后的 User类中的 __gt__ 方法
print(User.__gt__)
print(User('michael') < User('stark')) # True
print(User('michael') > User('stark')) # False
上面代码中定义的 User 类中提供了 __eq__、__lt__ 两个比较方法。这行 @total_ordering 代码装饰器修饰了 User 类,这样该装饰器会为 User 类提供 __gt__、__ge__、__le__、__ne__ 这些比较方法。在代码中通过输出 User 类的__gt__方法可以看到,此时的 __gt__ 方法是根据__lt__方法 “生产” 出来的。输出如下:
<function _gt_from_lt at 0x000001C98818EF28>
True
False
如果将上面代码中的这行 @total_ordering 代码注释掉,再次运行这段代码,则看到的输出结果如下:
<slot wrapper '__gt__' of 'object' objects>
True
False
从输出结果可以看到,此时该 __gt__ 方法是来自父类 object。
@singledispatch 函数装饰器的作用是根据函数参数类型转向调用另一个函数,从而实现函数重载的功能。该函数的示例如下:
from functools import *
@singledispatch
def test(arg, verbose):
if verbose:
print("默认参数为:", end=" ")
print(arg)
# 限制 test 函数的第一个参数为 int 类型的函数版本
@test.register(int)
def _(argu, verbose):
if verbose:
print("整型参数为:", end=" ")
print(argu)
test('python', True)
# 调用第一个参数为 int 类型的版本
test(20, True)
运行代码,输出结果如下:
默认参数为: python
整型参数为: 20
上面代码中使用 @singledispatch 装饰器修饰了 test() 函数,接下来即可通过 test() 函数的 register 方法来注册被转向调用的函数。代码中继续使用 @test.register(int) 修饰了目标函数,这意味着如果 test() 函数的第一个参数为 int 类型,实际上会转向调用被 @test.register(int) 修饰的函数。
需要注意的是:使用 @singledispatch 装饰器修饰之后的函数就有了 register() 方法,该方法用于为指定类型注册被转向调用的函数。
在上面代码第一次调用 test('python', True) 函数时,第一个参数是 str 类型,此时会调用 test 函数本身;第二次调用test(20, True) 函数时第一个参数是 int 类型,因此会转向调用被 @test.register(int) 修饰的函数。从输出结果可以看到这点。
在上面代码中,还可继续使用 @test.register() 装饰器来绑定被转向调用的函数。示例如下:
······
# 限制 test 函数的第一个参数为 list 类型的函数版本
@test.register(list)
def _(argb, verbose=False):
if verbose:
print("列表中所有元素为:")
for i, e in enumerate(argb):
print("{0}:{1}".format(i, e), end=" ")
test([40, 30, 20, 10], False)
print("\n-------------------")
关于这段代码的输出如下:
0:40 1:30 2:20 3:10
-------------------
在这段代码中使用 @test.register(list) 将 test() 的第一个参数注册为 list,现在调用 test() 函数时,传入第一个参数是列表类型时,就会转向调用被 @test.register(list) 修饰的函数。输出结果如上所示。
此外,还可使用 register(cls, func=None) 方法来执行绑定,即根据 cls(类型)来转向被调用的函数(func)。这种方式与前面使用的装饰器的本质是一样的,只不过这种语法没有修饰被转向调用的函数,因此需要额外多传入一个参数。示例如下:
······
print("\n-------------------")
# 定义一个函数,不使用函数装饰器修饰
def nothing(arg, verbose=False):
print("~~None 参数~~")
# 当 test 函数的第一个参数为 None 类型时,转向调用 nothing 函数
test.register(type(None), nothing)
test(None, True)
print("\n-------------------")
关于这段代码的输出结果如下:
-------------------
~~None 参数~~
-------------------
上面代码段中 test.register(type(None), nothing) 行代码指定调用 test() 函数的第一个参数为 None 类型时,就会转向调用nothing() 函数。接下来的 test(None, True) 行代码在调用 test() 函数时传入的第一个参数是 None,因此会转向调用 nothing() 函数。运行结果如上所示。
此外,@singledispatch 也允许为参数的多个类型绑定同一个被转向调用的函数:只要使用多个 @函数名.register() 装饰器即可。例如下面示例这样:
······
from decimal import Decimal
# 限制 test 函数的第一个参数为 float 或 Decimal 类型的函数版本
@test.register(float)
@test.register(Decimal)
def test_num(arg, verbose=False):
"""test_num() 函数上面有两个装饰器,现在test()函数的第一个参数
满足两个类型中的一个时,就会调用这个函数"""
if verbose:
print("参数的一半为:", end=" ")
print( arg / 2)
上面这段代码中使用@test.register(float)、@test.register(Decimal) 修饰 test_num() 函数,这意味着在调用 test() 函数时无论第一个参数是 float 类型还是 Decimal 类型,其实都会转向调用 test_num 函数。
当程序中为 @singledispatch 函数执行绑定之后,就可通过该函数的 dispatch(类型) 方法来找到该类型所对应转向的函数。如下代码所示:
······
# 通过 test.dispatch(类型) 即可获取它转向的函数
# 当 test 函数的第一个参数为 float 时将转向调用 test_num
print(test_num is test.dispatch(float)) # True
# 当 test 函数的第一个参数为 Decimal 时将转向调用 test_num
print(test_num is test.dispatch(Decimal)) # True
# 直接调用 test 并不等于调用 test_num
print(test_num is test) # False
运行这段代码,输出结果如下:
True
True
False
由于这段代码中调用 test() 函数时,第一个参数无论是 float 还是 Decimal 都会转向调用 test_num 函数,因此 test.dispatch(float) 和 test.dispatch(Decimal) 其实就是 test_num 函数,所以输出结果是 True。如上输出所示。
此外,如果要访问 @singledispatch 函数所绑定的全部类型及对应的 dispatch 函数,可通过该函数的只读属性 registry 来实现,该属性相当于一个只读的 dict 对象。例如下面这样:
······
# 获取 test 函数所绑定的全部类型
print(test.registry.keys())
# 获取 test 函数为 int 类型绑定的函数
print(test.registry[int])
运行这段代码,输出如下:
dict_keys([<class 'object'>, <class 'int'>, <class 'list'>, <class 'NoneType'>,
<class 'decimal.Decimal'>, <class 'float'>])
<function _ at 0x000001F4CDA76F28>
@wraps(wrapped_func) 函数装饰器与 update_wrapper(wrapper, wrapped_func) 函数的作用是一样的,都用于让包装函数看上去就像被包装函数(主要就是让包装函数的 __name__、__doc__属性与被包装函数保持一致)。区别是:@wraps(wrapped_func) 函数装饰器直接修饰包装函数,因此不需要传入包装函数作为参数;而 update_wrapper(wrapper, wrapped_func) 函数需要同时传入
包装函数、被包装函数作为参数。下面代码示例了 @wraps(wrapped_func) 函数装饰器的用法:
from functools import wraps
def my_decorator(f):
# 让 wrapper 函数看上去你 f 函数
@wraps(f)
def wrapper(*args, **kwargs):
print('调用被装饰函数')
return f(*args, **kwargs)
return wrapper
@my_decorator
def test():
"""test 函数的说明信息"""
print("执行 test 函数")
test()
print(test.__name__)
print(test.__doc__)
上面代码中的这行代码 @wraps(f) 作用是,让被包装函数(wrapper)就像 f 函数。接下使用 @my_decorator 修饰 test() 函数,因此在调用 test() 函数时,实际上是调用 my_decorator 的返回值:wrapper 函数(函数装饰器的功能)。
也就是说,上面代码中最后三行代码看上去是访问 test 函数,实际上是访问 wrapper 函数。由于程序使用 @wraps(f) 修饰了 wrapper 函数,因此该函数看上去就像 test 函数。所以,程序在输出 test.name 和 test.doc 时(注意此处的 test 其实是wrapper 函数),输出的依然是 test 函数的函数名、描述文档。运行代码,输出结果如下:
调用被装饰函数
执行 test 函数
test
test 函数的说明信息
如果注释掉上面代码中的 @wraps(f) 这行代码,此时将不能让 wrapper 函数看上去像 test 函数。此时再次运行该段代码,将看到如下输出结果:
调用被装饰函数
执行 test 函数
wrapper
None
十、小结
1、Python 还有大量内置模块在这里没提及,如有使用到,可参考 Python 官方库文档。
2、sys 模块代表与 Python 解释器相关的操作;os 模块代表与操作系统相关的操作。
3、random、time、json 模块是编程中实用且不复杂的模块,需要熟练掌握。
4、Python 的正则表达式模块非常重要,正则表达式是 Python 的一个强大功能,也是用来编写爬虫程序、抓取数据的基础。正则表达式入门容易,要深入就需要花更多的时间学习。
5、Python 的各种容器类,包括 set、frozenset、deque、堆操作、ChainMap、Counter、defaultdict、OrderedDict、命名元组等,这些容器类在特殊场合下有特殊的功用,熟练使用它们,不仅能大大提高开发效率,还可以让程序代码更加优雅。
6、使用 itertools 和 functools 模块下的迭代器功能函数、函数装饰器和其他功能函数,可以让 Python 代码更加简洁和优雅。
练习:
1、提示用户输入自己的名字、年龄、身高,并将该用户信息以 JSON 格式保存在文件中。再写一个程序读取刚刚保存的 JSON 文件,恢复用户输入的信息。
import json
name = input("请输入你的名字:")
while True:
try:
age = int(input("请输入你的年龄:"))
break
except:
print("年龄需要输入整数")
while True:
try:
height = float(input("请输入你的身高(cm):"))
break
except:
print("身高需要输入浮点数")
with open('person.txt', 'w+', encoding='utf8') as f:
json.dump({'name': name, 'age': age, 'height': height}, f)
with open('person.txt', 'r', encoding='utf8') as fp:
person_info = json.load(fp)
print("姓名:", person_info['name'])
print("年龄:", person_info['age'])
print("身高(cm):", person_info['height'])
2、给定一个字符串,该字符串只包含数字 0~9、英文逗号、英文点号,要求使用英文逗号、英文点号将它们分割成多个子串。
import re, sys
while True:
string = input("请输入字符串:")
if string == 'exit':
sys.exit(0)
if not re.fullmatch(r'[0-9,\.]+', string):
raise ValueError("你的输入只能包含0~9数字、英文逗号、英文点号!")
# findall 匹配的结果自动分成多个子串
rt_list = re.findall(r'[0-9]+', string)
print(rt_list)
3、 定义一个正则表达式,用于验证国内的所有手机号码。
import re, sys
while True:
number = input("请输入一个手机号码:")
if number == 'exit':
sys.exit(0)
if not re.fullmatch(r'^(1[358][0-9]|14[579]|16[6]|17[0135678]|19[0189])\d{8}$', number):
print("你输入的不是正确国内手机号码!")
else:
print("国内手机号码是:", number)
4、提示用户输入一个字符串,在程序中使用正则表达式获取该字符串中第一次重复出现的英文字母(包括大小写)。
import re, sys
while True:
string = input("请输入一个字符串:")
if string == 'exit':
sys.exit(0)
# if re.search(r'', string, re.I):
# 去掉字符串中的非字母字符
m1 = re.sub('[^a-zA-Z]', "", string)
if m1:
for e in m1.lower():
if m1.lower().count(e) >= 2:
print(e)
break
5、 提示用户输入一字符串和一个子串,打印出该子串在字符串出现的 start 和 end 位置,如果没有出现,则打印 (-1,-1),例如
当用户输入:
aaadaa
aa
要求输出如下:
(0, 1)
(1, 2)
(4, 5)
import re
string, sub = input("请输入第一个字符串:"), input("请输入子串:")
matches = list(re.finditer(r'(?={})'.format(sub), string))
if matches:
# print("\n".join(str((match.start(), match.start() + len(sub) - 1)) for match in matches))
for match in matches:
print((match.start(), match.start() + len(sub) - 1))
else:
print((-1, -1))
6、提示用户输入两行,第一行是所有学习 Python 的学员编号(以逗号隔开),第二行是所有学习 Linux 的学员编号(以逗号隔开),计算所有只学 Python 不学 Linux 的学员的数量。使用集合的差集实现。
import re
python_set = set(re.findall('[^,\.\s]+', input("学习Python的学员:")))
linux_set = set(re.findall('[^,\.\s]+', input("学习Linux的学员:")))
print(python_set)
print(linux_set)
diff = python_set - linux_set
print('只学Python不学Linux的学员:', diff)
print('只学Python不学Linux的学员有%d人。' % len(diff))
代码运行一次的结果如下:
学习Python的学员:a1001, a1002, a1003, a1004
学习Linux的学员:b1001, b1002, a1001, b1004
{'a1002', 'a1004', 'a1003', 'a1001'}
{'b1002', 'b1001', 'a1001', 'b1004'}
只学Python不学Linux的学员: {'a1004', 'a1003', 'a1002'}
只学Python不学Linux的学员有3人。
7、提示用户输入两行,第一行是所有学习 Python 的学员编号(以逗号隔开),第二行是所有学习 Linux 的学员编号(以逗号隔开),计算所有既学 Python 又学 Linux 的学员的数量。使用集合的交集实现。
import re
python_set = set(re.findall('[^,\.\s]+', input("学习Python的学员:")))
linux_set = set(re.findall('[^,\.\s]+', input("学习Linux的学员:")))
print(python_set)
print(linux_set)
inter = python_set & linux_set
print('既学Python又学Linux的学员:', inter)
print('既学Python又学Linux的学员有%d人。' % len(inter))
代码运行一次的结果如下:
学习Python的学员:a1001, a1002, a1003, a1004
学习Linux的学员:b1001, b1002, a1001, b1004
{'a1001', 'a1003', 'a1004', 'a1002'}
{'a1001', 'b1001', 'b1004', 'b1002'}
既学Python又学Linux的学员: {'a1001'}
既学Python又学Linux的学员有1人。
8、计算用户输入的两个带时区的时间戳字符串之间相差的秒数。例如用户输入:
Sun 10 May 2015 13:54:36 -0700
Sun 10 May 2015 13:54:36 -0000
程序应该输出:
25200
from datetime import datetime as dt
s = """
按照下面的格式输入日间:
第一个时间:Wed 27 Nov 2019 10:08:30 -0800
第二个时间:Wed 27 Nov 2019 10:08:30 -0000
得到结果是:28800
"""
fmt = '%a %d %b %Y %H:%M:%S %z'
for i in range(int(input("请输入要比较多少组时间:"))):
if i == 0:
print(s)
print(int(abs((dt.strptime(input('第一个时间:'), fmt) -
dt.strptime(input('第二个时间:'), fmt)).total_seconds())))
代码运行一次的结果如下:
请输入要比较多少组时间:1
按照下面的格式输入日间:
第一个时间:Wed 27 Nov 2019 10:08:30 -0800
第二个时间:Wed 27 Nov 2019 10:08:30 -0000
得到结果是:28800
第一个时间:Wed 27 Nov 2019 10:08:30 -0500
第二个时间:Wed 27 Nov 2019 10:10:30 -0500
120
9、提示用户输入一个字符串,要求实现输出字符串中出现次数最多的3个字符,以及对应的出现次数。使用 Counter 类中的 most_common(n) 方法即可实现。
from collections import Counter
s = input("请输入一个字符串:")
c = Counter(s)
[print(e[0], e[1]) for e in c.most_common(3)]
10、定义一个 fibonacci(n) 函数,该函数返回包含 n 个元素的斐波那契数列的列表。再使用 lambda 表达式定义一个平方函数,要求最终输出斐波那契数列的前 n 个元素的平方值。
方法一:使用列表方式
def fibonacci(n):
res_list = [1, 1]
# 生成斐波那契数列
[res_list.append(res_list[-1] + res_list[-2]) for _ in range(2, n)]
return res_list
print(fibonacci(10))
# 计算 fibonacci 数列元素的平方
res = map(lambda x: x*x, fibonacci(10))
print([e for e in res])
方法二:使用生成器方式
def fibonacci2(n):
a, b = 1, 1
for i in range(n):
yield a
a, b = b, a + b
print(list(fibonacci2(10)))
result = map(lambda x: x*x, fibonacci2(10))
print([e for e in result])