1.Seaborn
Seaborn是基于matplotlib的Python数据可视化库。它提供了一个高级界面,用于绘制引人入胜且内容丰富的统计图形。更多运用了解Seaborn官方介绍
2.seaborn.load_dataset
seaborn.load_dataset(name, cache=True, data_home=None, **kws)从在线库中获取数据集(需要联网)。
参数说明:
name:字符串,数据集的名字 (name.csv on https://github.com/mwaskom/seaborn-data)。 您可以通过 get_dataset_names() 获取可用的数据集
cache:boolean, 可选,如果为True,则在本地缓存数据并在后续调用中使用缓存
data_home:string, 可选,用于存储缓存数据的目录。 默认情况下使用 ~/seaborn-data/
kws:dict, 可选,传递给 pandas.read_csv
关于此,更多可参考官网
3.matplotlib.pyplot
matplotlib.pyplot.acorr(x,hold = None,data = None,** kwargs )
参数说明
| x | 标量序列 |
|---|---|
| hold | 布尔值,可选,不推荐使用,默认值:True |
| detrend | 可调用,可选,默认:mlab.detrend_none |
| normed | 布尔值,可选,默认值:True如果为True,则将输入向量归一化为单位长度。 |
| usevlines | 布尔值,可选,默认:True如果为True,则使用Axes.vlines绘制从原点到acorr的垂直线。否则,将使用Axes.plot |
| maxlags | 整数,可选,默认:10;显示的滞后次数。如果为None,将返回所有2 * len(x)-1个滞后。 |
| 返回值 | (滞后,c,行,b):其中:lags 是长度2maxlags + 1滞后向量。c 是2maxlags + 1自相关向量line是由Line2D返回的实例 plot,b 是x轴。 |
| 更多 | 点此进入官网,了解更多示例 |
4.matplotlib.pyplot.plot
matplotlib.pyplot.acorr(x,hold = None,data = None,** kwargs )
参数详解:
网搜一篇文章觉得写的挺有帮助的,自己就不写啦:
1.参考博客matplotlib.pyplot.plot()参数详解
2.参考官网:matplotlib.pyplot是matplotlib的基于状态的接口
5.示例运用:
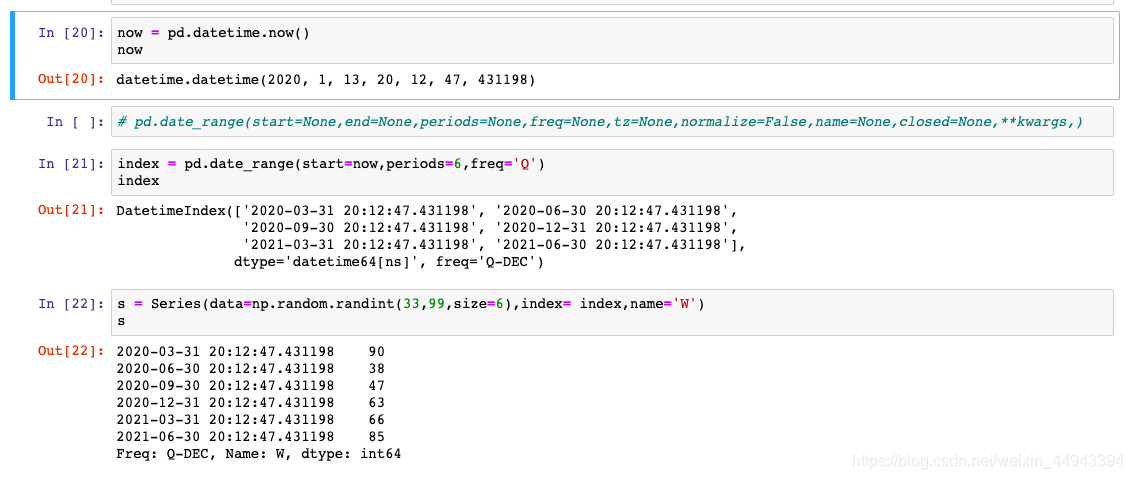
(5.1)Series图表示例------线行图
now = pd.datetime.now()
index = pd.date_range(start=now,periods=6,freq='Q')
s = Series(data=np.random.randint(77,99,size=6),index= index,name='W')
s.plot(kind='line')
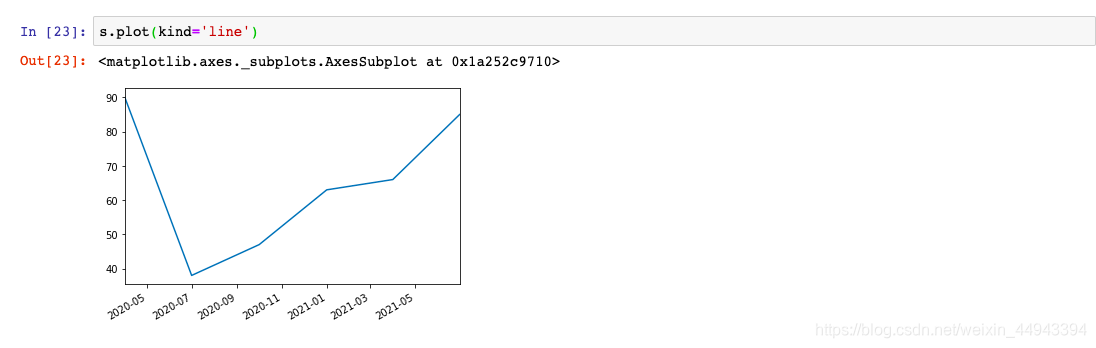
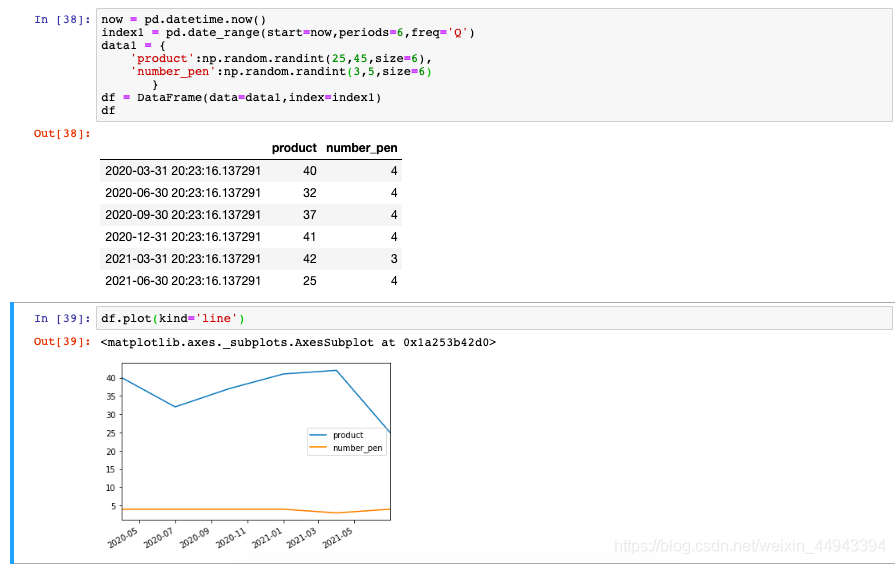
(5.1)DataFrame图表示例------线行图
now = pd.datetime.now()
index1 = pd.date_range(start=now,periods=6,freq='Q')
data1 = {
'product':np.random.randint(25,45,size=6),
'number_pen':np.random.randint(3,5,size=6)
}
df = DataFrame(data=data1,index=index1)
df.plot(kind='line')
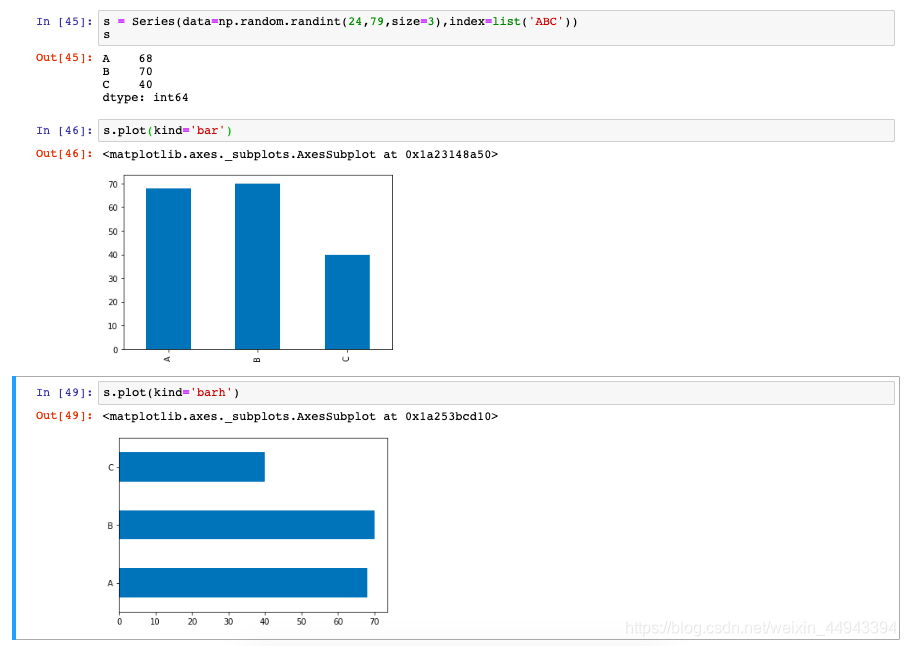
(5.2)Series图表示例------柱状图
s = Series(data=np.random.randint(24,79,size=3),index=list('ABC'))
s.plot(kind='bar/barh')
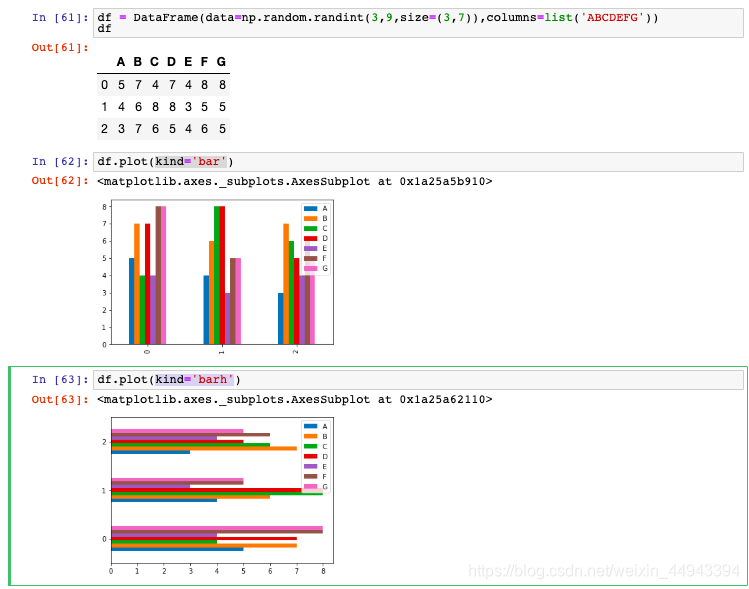
(5.2)DataFrame图表示例------柱状图
df = DataFrame(data=np.random.randint(3,9,size=(3,7)),columns=list('ABCDEFG'))
df.plot(kind='bar/barh')
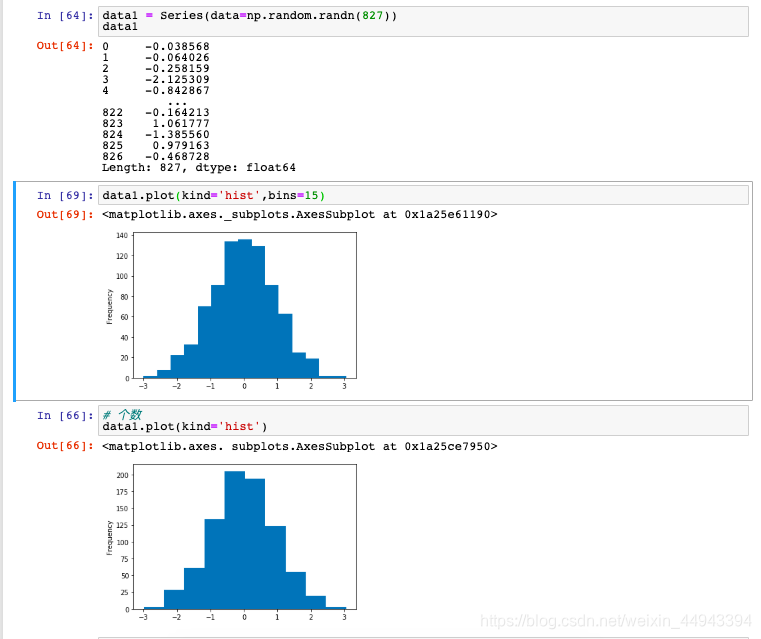
(5.3)示例------直方图
统计在每个数据区间,数据出现的次数
normed:把次数转换成可能出现的概率(0-1)区间
density:seabon matplotlib
data.plot(kind=‘hist’,bins=5,normed=True)
核密度估计图,把每个数据区间可能出现的概率进行统计
data.plot(kind=‘kde’)
显示个数区别:
# 个数
data1 = Series(data=np.random.randn(827))
data1.plot(kind='hist')
data1.plot(kind='hist',bins=15)
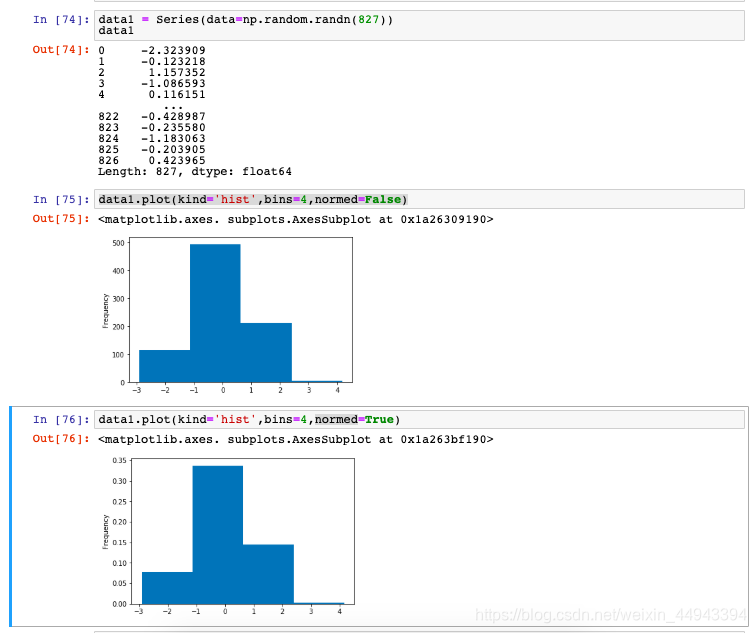
normal的True和False
# normal
data1 = Series(data=np.random.randn(827))
data1.plot(kind='hist',bins=4,normed=False)
data1.plot(kind='hist',bins=4,normed=True)
kde使用
data1 = Series(data=np.random.randn(827))
data1.plot(kind='hist',bins=6,normed=True)
data1.plot(kind='kde')
data1.plot(kind='hist',bins=2,normed=True)
data1.plot(kind='kde')
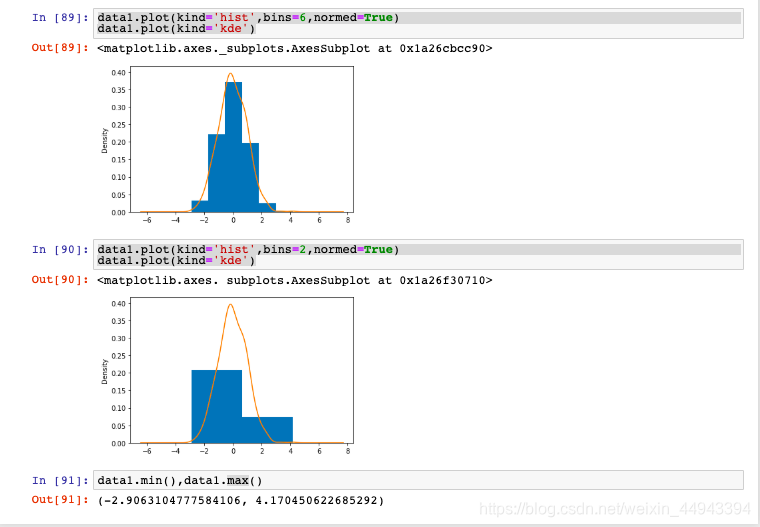
rondom生成随机数百分比直方图,调用hist方法
- 柱高表示数据的频数,柱宽表示各组数据的组距
- 参数bins可以设置直方图方柱的个数上限,越大柱宽越小,数据分组越细致
- 设置normed参数为True,可以把频数转换为概率
kde图:核密度估计,用于弥补直方图由于参数bins设置的不合理导致的精度缺失问题
两道练习题,点此
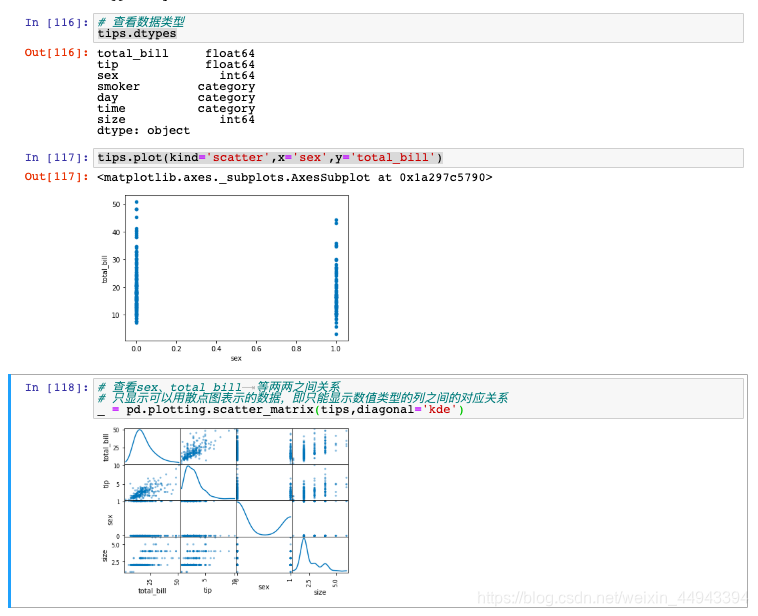
(5.4)示例------散点图

如果还不能转换,使用下种方法:
参考链接:pandas category数据类型
参考资料:来源于学习资料及各链接网站。
