吴恩达机器学习栏目清单
专栏直达:https://blog.csdn.net/qq_35456045/category_9762715.html
14.6 重建的压缩表示
参考视频: 14 - 6 - Reconstruction from Compressed Representation (4 min).mkv
在以前的视频中,我谈论PCA作为压缩算法。在那里你可能需要把1000维的数据压缩100维特征,或具有三维数据压缩到一二维表示。所以,如果这是一个压缩算法,应该能回到这个压缩表示,回到你原有的高维数据的一种近似。

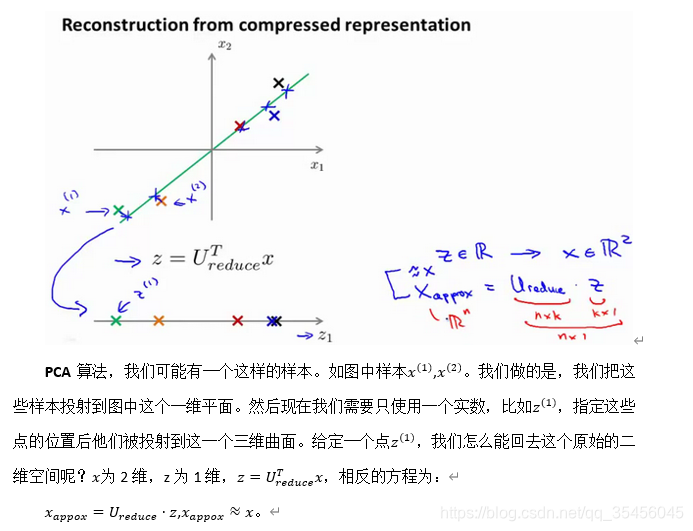
如图:
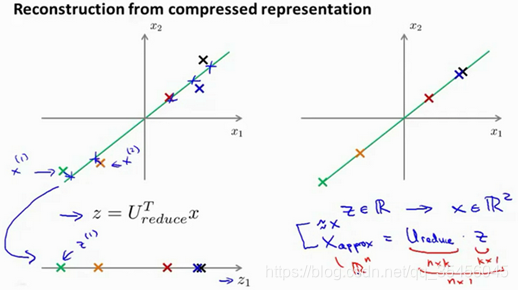
如你所知,这是一个漂亮的与原始数据相当相似。所以,这就是你从低维表示z回到未压缩的表示。我们得到的数据的一个之间你的原始数据 x,我们也把这个过程称为重建原始数据。
当我们认为试图重建从压缩表示 x 的初始值。所以,给定未标记的数据集,您现在知道如何应用PCA,你的带高维特征x和映射到这的低维表示z。这个视频,希望你现在也知道如何采取这些低维表示z,映射到备份到一个近似你原有的高维数据。
现在你知道如何实施应用PCA,我们将要做的事是谈论一些技术在实际使用PCA很好,特别是,在接下来的视频中,我想谈一谈关于如何选择k。
14.7 主成分分析法的应用建议
参考视频: 14 - 7 - Advice for Applying PCA (13 min).mkv
假使我们正在针对一张 100×100像素的图片进行某个计算机视觉的机器学习,即总共有10000 个特征。
- 第一步是运用主要成分分析将数据压缩至1000个特征
- 然后对训练集运行学习算法。
- 在预测时,采用之前学习而来的U_reduce将输入的特征x转换成特征向量z,然后再进行预测
注:如果我们有交叉验证集合测试集,也采用对训练集学习而来的U_reduce。
错误的主要成分分析情况:一个常见错误使用主要成分分析的情况是,将其用于减少过拟合(减少了特征的数量)。这样做非常不好,不如尝试正则化处理。原因在于主要成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征。然而当我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。
另一个常见的错误是,默认地将主要成分分析作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析。
