WebMagic功能
实现PageProcessor
- 抽取元素Selectable
WebMagic里主要使用了三种抽取技术:XPath、正则表达式和CSS选择器。另外,对于JSON格式的内容,可使用JsonPath进行解析。
XPath
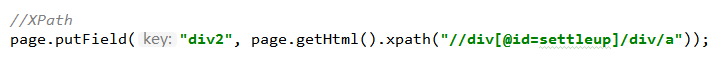
CSS选择器
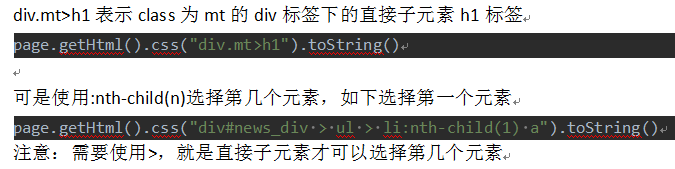
CSS选择器是与XPath类似的语言。它比XPath写起来要简单一些,但是如果写复杂一点的抽取规则,就相对要麻烦一点。

正则表达式
正则表达式则是一种通用的文本抽取语言。在这里一般用于获取url地址。

抽取元素API
Selectable相关的抽取元素链式API是WebMagic的一个核心功能。使用Selectable接口,可以直接完成页面元素的链式抽取,也无需去关心抽取的细节。
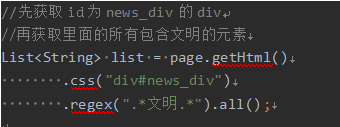
在刚才的例子中可以看到,page.getHtml()返回的是一个Html对象,它实现了Selectable接口。这个接口包含的方法分为两类:抽取部分和获取结果部分。



获取结果API
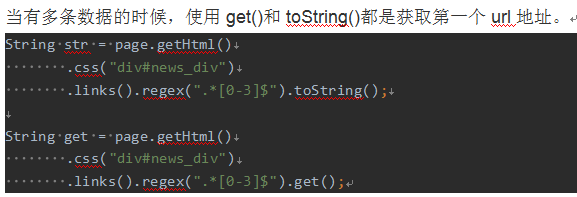
当链式调用结束时,我们一般都想要拿到一个字符串类型的结果。这时候就需要用到获取结果的API了。
一条抽取规则,无论是XPath、CSS选择器或者正则表达式,总有可能抽取到多条元素。WebMagic对这些进行了统一,可以通过不同的API获取到一个或者多个元素。



获取链接
有了处理页面的逻辑,我们的爬虫就接近完工了,但是现在还有一个问题:一个站点的页面是很多的,一开始我们不可能全部列举出来,于是如何发现后续的链接,是一个爬虫不可缺少的一部分。

使用Pipeline保存结果
WebMagic用于保存结果的组件叫做Pipeline。我们现在通过“控制台输出结果”这件事也是通过一个内置的Pipeline完成的,它叫做ConsolePipeline。
那么,我现在想要把结果用保存到文件中,怎么做呢?只将Pipeline的实现换成"FilePipeline"就可以了

