计算图(Computation Graph)
举例:
J(a,b,c)=3(a+bc)⟹⎩⎪⎨⎪⎧u=bcv=a+uJ=3v
那么这个函数的计算图为:
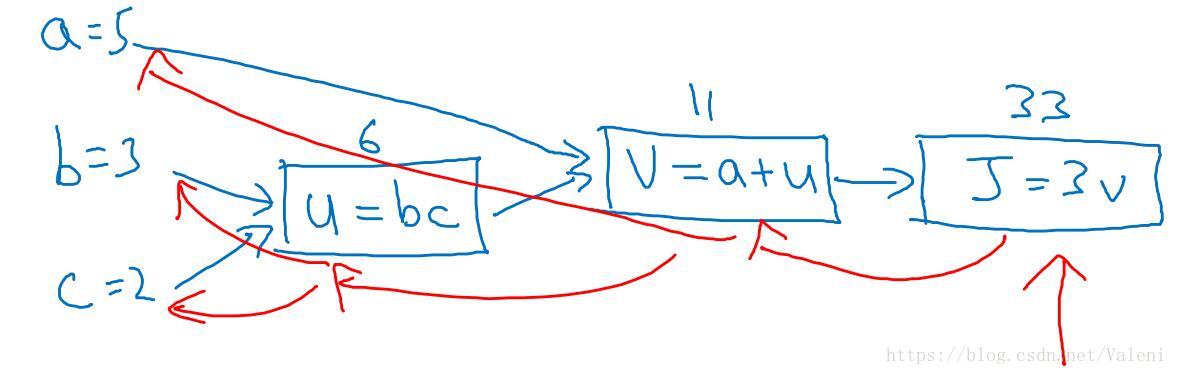
逻辑回归梯度下降算法(Gradient descent algorithm)
单个训练样本(One training sample):
z=wT+b
y^=a=σ(z)
L(a,y)=−(ylog(a)+(1−y)log(1−a))
计算图(Computaion Graph):
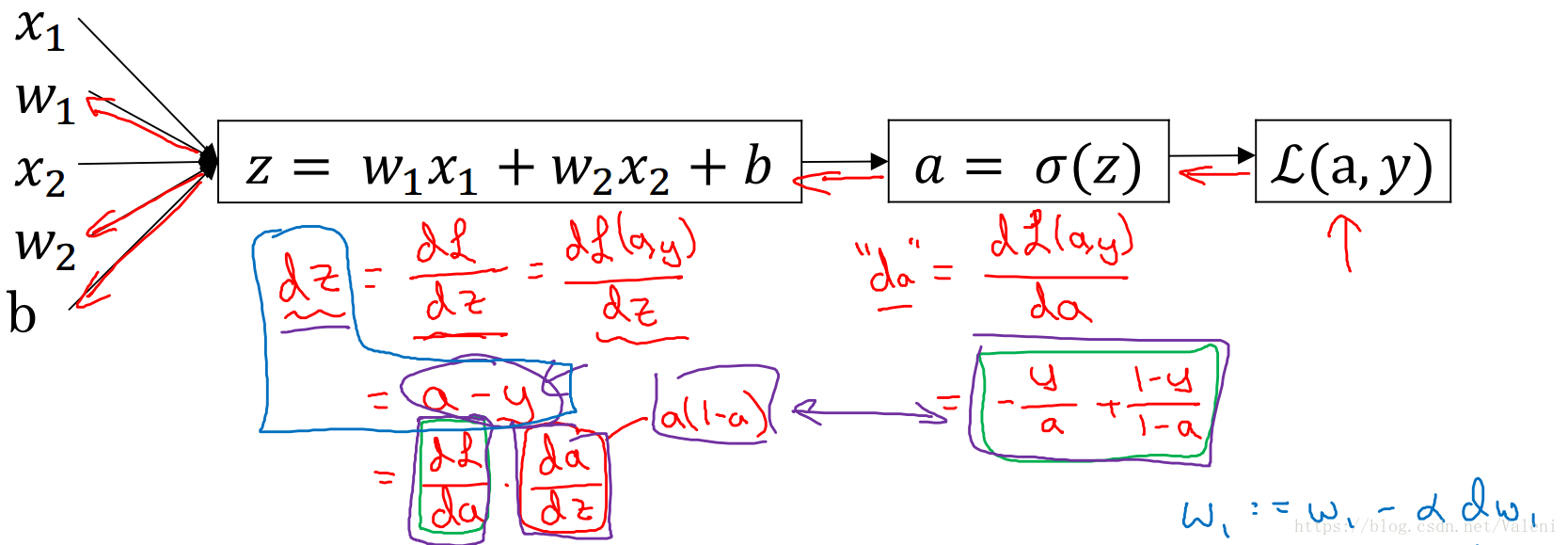
计算导数(Derivative):
dadl(a,y)=−ay+1−a1−y
dzdl(a,y)=dadl⋅dzda
=(−ay+1−a1−y)a(1−a)
=a−y
dw1dl(a,y)=x1(a−y)
dw2dl(a,y)=x2(a−y)
dbdl(a,y)=a−y
这实际上是把逻辑回归看作单层的神经网络,用反向传播算法(Back Propagation Algorithm)计算出各个参数的导数,以便下一步用梯度下降算法计算出代价最小的参数。
多个训练样本(m training samples):
J(w,b)=m1∑i=1ml(a(i),y(i))
a(i)=y^(i)=σ(z(i))=σ(wTx(i)+b)
∂w1∂J(w,b)=m1∑i=1m∂w1∂l(a(i),y(i))
∂b∂J(w,b)=m1∑i=1m∂b∂l(a(i),y(i))
逻辑回归算法(Logistic regression algorithm)
Repeat{
J=0;dw1=0;dw2=0;db=0
For i in range(m):
z(i)=wTx(i)+b
a(i)=σ(z(i))
J+=y(i)loga(i)+(1−y(i))log(1−a(i))
dz(i)=a(i)−y(i)
dw1(i)+=x1(i)dz(i)
dw2(i)+=x2(i)dz(i)
db+=dz(i)
J/=m
dw1/=m
dw2/=m
db/=m
w1=w1−αdw1
w2=w2−αdw2
b=w1−αdb
}
未完待续…