Deep Learning by Andrew Ng 学习笔记之Neural Style Transfer
其他
2018-06-20 10:14:15
阅读次数: 2
Nerual StyleTransfer Algorithm
- Paper:A neural algorithm of artistic style (2015)
- 定义:
- 图片画风转移
- G = C + S,generate = content + style
- 首先理解感受野 receptive field,
- 浅层layer感受小的feature(比如边缘),深层detect复杂的feature(比如花、狗)。
- 每个layer的visualize结果:每个layer对应N_c个hidden unit,对于每个unit,找出激活值最大的9个output,然后找到这9个output对应的感受野对应的原图,就可以知道每个layer在学习些什么。-- 这里不太懂!!!这些图片代表什么?怎么来的?

- Paper: Visualizing and Understanding ConvNets (2013)
- Cost Function
- J(G) = alpha * J_content(C, G) + beta * J_style(S, G)
- 因此使G有C的内容和S的style。
- (两个超参数也许并非是必要的,one is enough)
- J(C, G)代表C和G的相似度,因此cost func希望G和两张图片都越来越接近
- 训练方式:
- 首先随机生成一张图片G=100*100*3
- 用梯度下降方式更新G,G = G - G对J(G)的导数
- 最终得到收敛图片为最终结果
- Cost Function之Content function:
- J(G) = alpha * J_content(C, G) + beta * J_style(S, G)
- J_content的超参数: layer -- l, 计算cost的hidden layer。
- 可以使用pre-trained convnet,e.g. vgg
- 对于C&G,L层的激活输出如果相似,那么两个iamge有相似的content。
- l一般不能选的太小(l太浅,会和图片完全一致),也不能选的太大(会看不出原图中的物体???)
- J_content(C, G) = 1/2 | a[l]_c - a[l]_g|| ^ 2
- 全都是element wise的差的平方的和。
- 前面的正则项可以不是1/2。
- Cost Function之Style Cost function:
- 同样具有超参数L - layer。
- 考虑这个layer的输出矩阵[N_w, N_h, N_c]
- 各个channet之间的相似度代表的信息:这两个不同的feature是否相关
- 橙色和竖线条纹高度相关,经常同时出现
- 橙色和圆形不相关等等
- 这些信息定义了图片的style
- 因此对于每一个这样的矩阵[N_w, N_h, N_c]我们可以得到一个没有正则化的协方差矩阵[N_c * N_C]
- 称作 Style Matrix
- 这是一个对称阵
- 每个元素(I, j)代表第i个和第j个channel的相关程度,越大越相关。
- 元素(I, j)计算方式:

- 之所以用G:“Gram Matrix”
- 两个channel便利所有对应位置,element wise相乘再相加得到两个channel之间的相关系数。
- 这样对于S和G,我们就分别得到了两个[N_c, N_c] 的style matix。
- 因此有
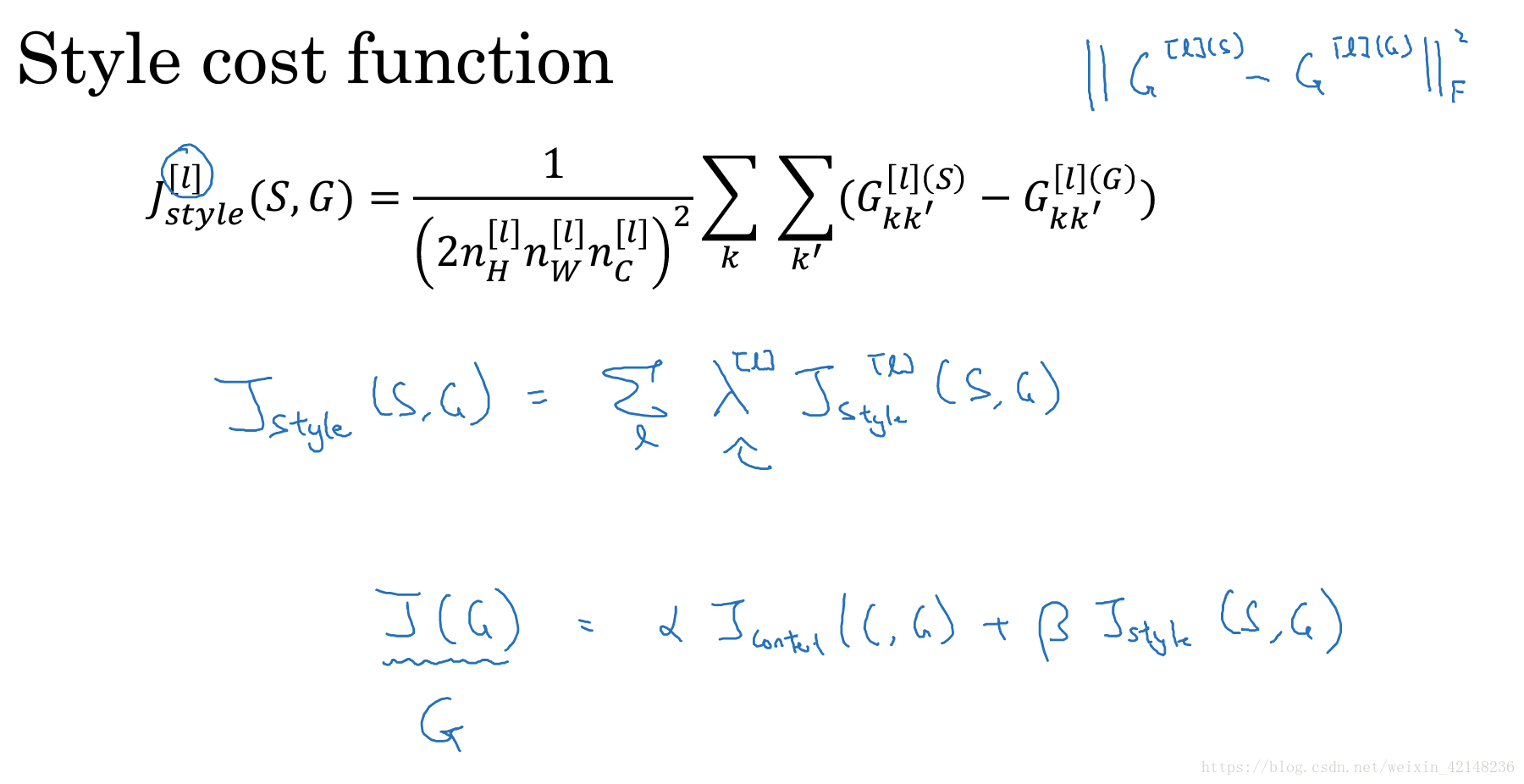
- 其中前面的正则项可以随意设置一个超参数
- J_style可以是所有layer的矩阵的element wise(L2norm)的差的平方和的总和,并给每一层添加一个权重。(效果会更好)
转载自blog.csdn.net/weixin_42148236/article/details/80736248