- 对Bias和Variance的来源的解释
Bias:来源于训练集中没有的,测试集中存在的data产生的。
Variance:来源于训练集里有的,但是测试集里没有的,且不应该属于ground truth的data(这里其实有个假设:就是test data认为是没有噪音的,完全是ground truth)。



三个值
- h相当于模型对训练集不含有variance的数据进行拟合产生的最佳模型。
- f相当于对测试集数据应该产生的模型
- y相当于对训练集含有噪声的数据应该产生的模型

最希望的模型:

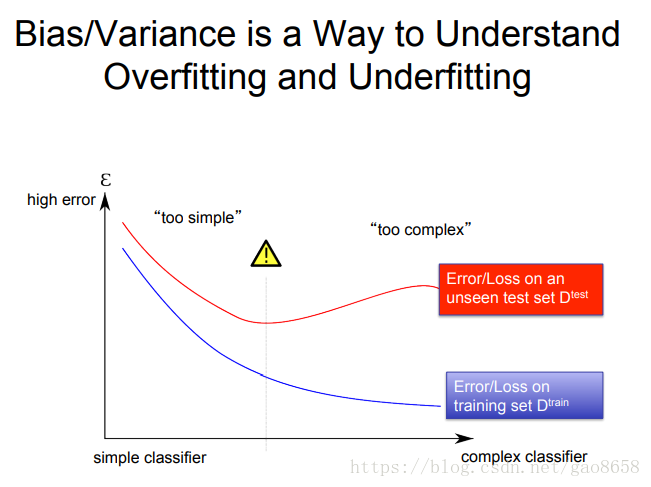
几种现象组合
| high variance | low variance | |
| high bias | 测试集数据和训练集数据严重不符 训练集数据也有大量噪声。 测试集有大量groundtruth训练集没有。 |
欠拟合 |
| low bias | 过拟合 | good model |
几个解决欠拟合和过拟合的方法通过bias和variance理解:
assumption:
如果数据足够好,bias应该是非常少的,更多的可能是train sample中的variance更多些。
数据端影响:
- Bagging:(单个subset更少)每个model的subset data包含的variance更少,假设比例不变,这样每个模型variance更小。(多个subset)同时有多个subdata set,让每个model能看到的train和test都能见到的数据更多,解决bias问题。第一个模型出现的bias,靠其他模型看到过test数据集有,第一个subset没有的数据,来弥补。
- 扩充高质量数据集:稀释variance,减少bias
- 特征选择,减少特征:减少variance发生的列,减少variance影响。
模型端影响:
- 正则化:问题来源:high variance。削弱模型对指定特征的学习能力,减少了高variance的风险。
- 简单模型:减少学习variance能力,当然也同时削弱了预测bias的能力。
- 复杂模型:对variance和bias数据都增强了拟合能力。
- 扩展特征:扩充bias可能性增加,同时有增加variance风险。将数据升维,更改数据的排布,让训练和测试集的分布更加贴近。
参考文章:http://www.cs.cmu.edu/~wcohen/10-601/bias-variance.pdf
友情推荐:ABC技术研习社
为技术人打造的专属A(AI),B(Big Data),C(Cloud)技术公众号和技术交流社群。
