版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/abc8730866/article/details/70260188
本讲核心问题:Where does the error come from?
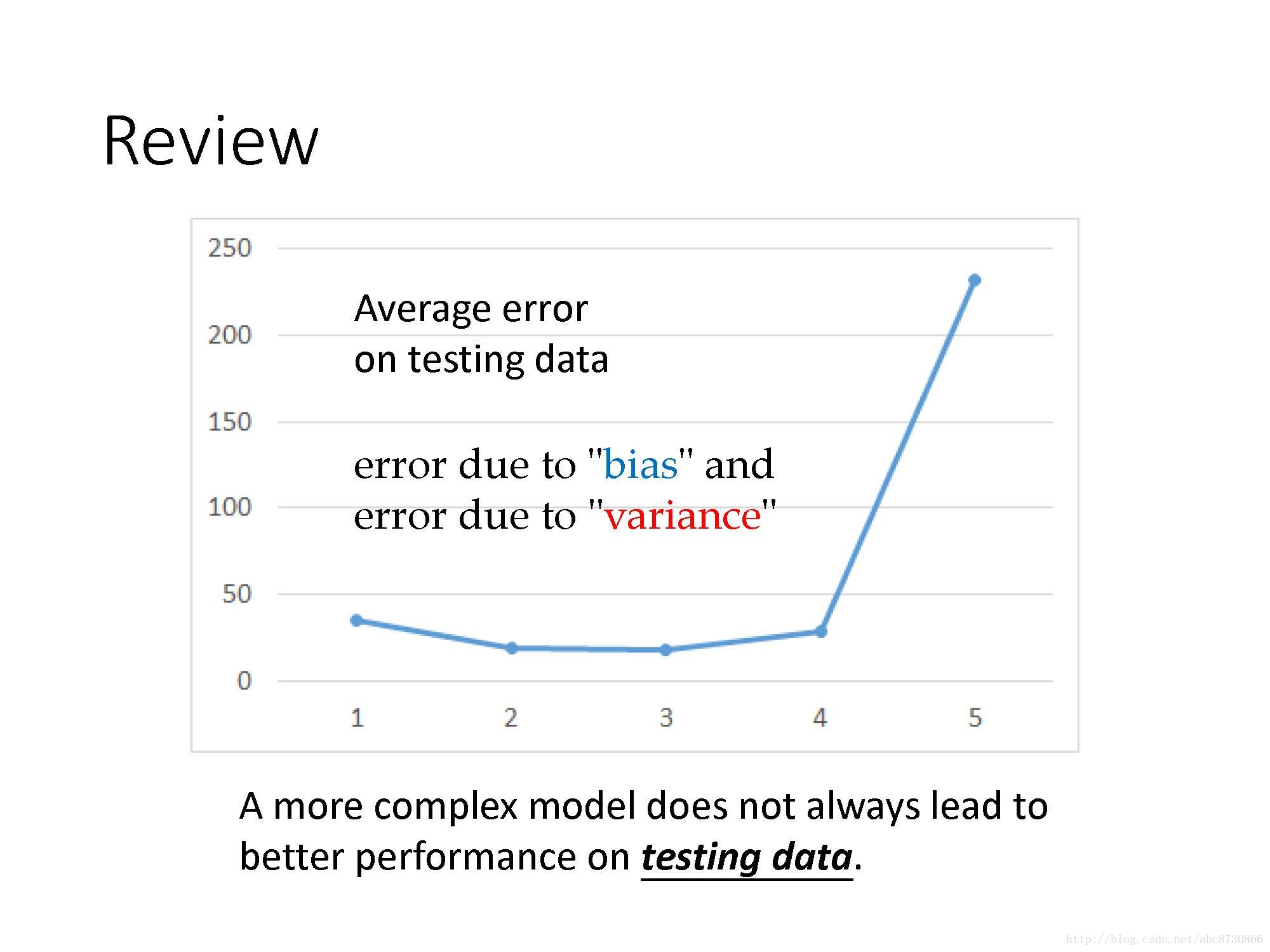
Review:
- 更复杂的模型不一定在测试集上有更好的表现
- 误差由偏差“bias”导致
- 误差由方差“variance”导致
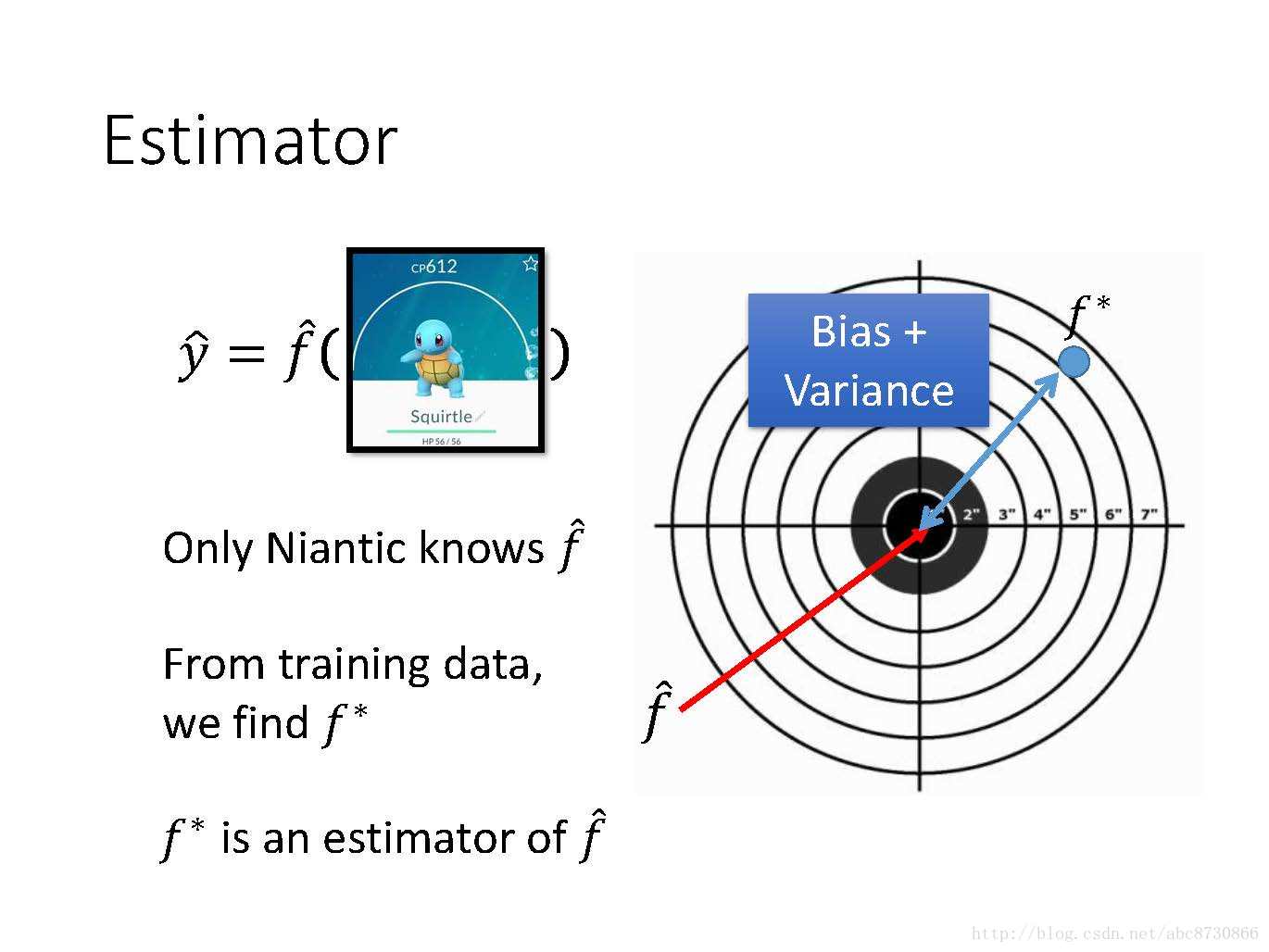
Estimator:
-
f^ 是计算pokemon真正的函数,只有Niantic公司知道 - 从训练集上,我们得出
f∗ ,f∗ 是f^ 的一个估计 - 故像射击一样,靶心为
f^ ,f∗ 是我们射中的地方,会由于“bias”和“variance”导致射偏。
Bias and Variance of Estimator:
- 估测均值
μ :用m来估计均值μ 是unbiased的(注意理解下其中公式)


- 估计方差
σ2 :用s2 来估计σ2 是biased的(同样注意理解其中公式)

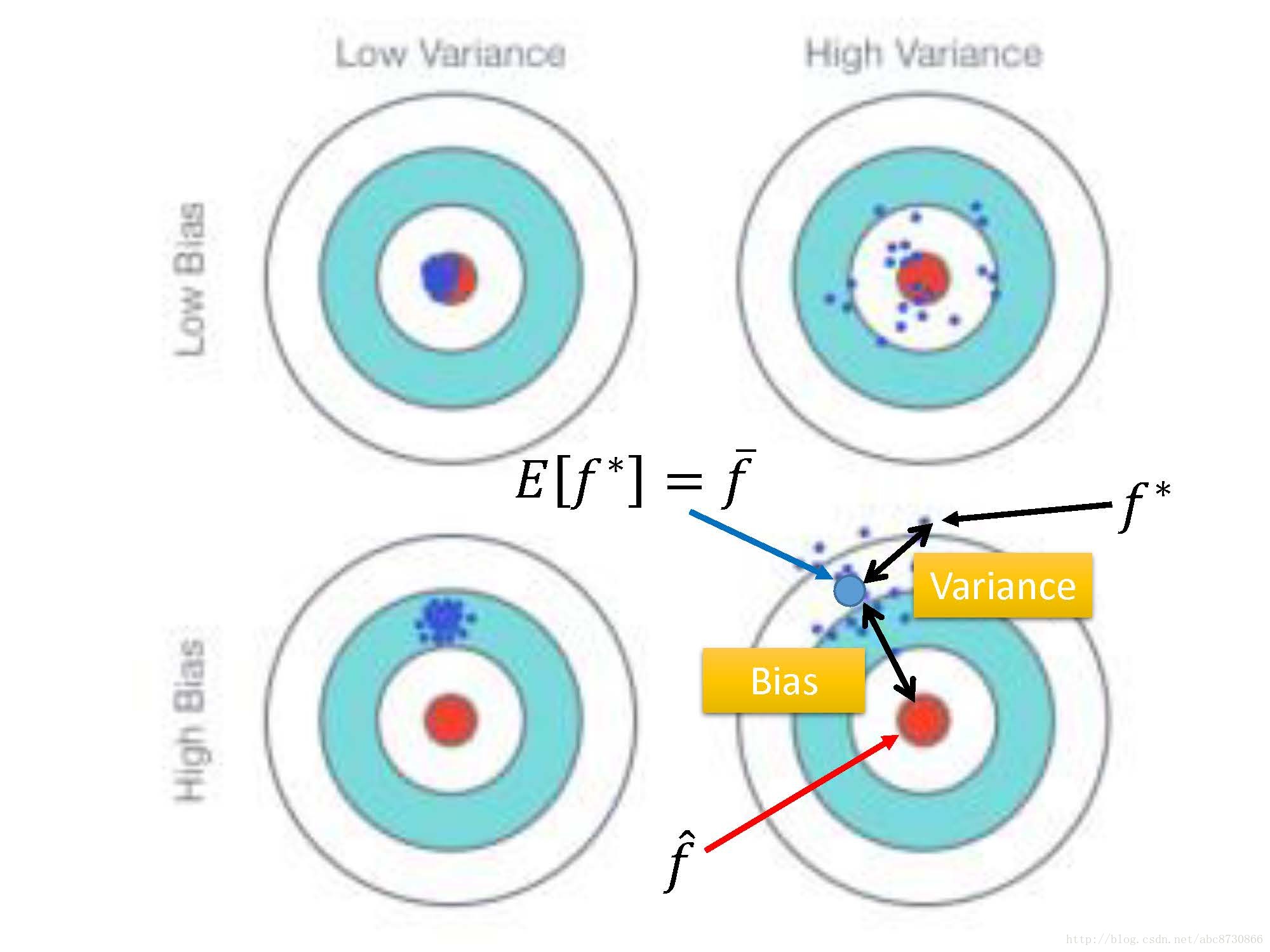
形象解释Bias和Variance
- 就像射击一样,你瞄准点同靶心的距离就是Bias;你实际射在靶心上的位置与你瞄准点的距离就是Variance。
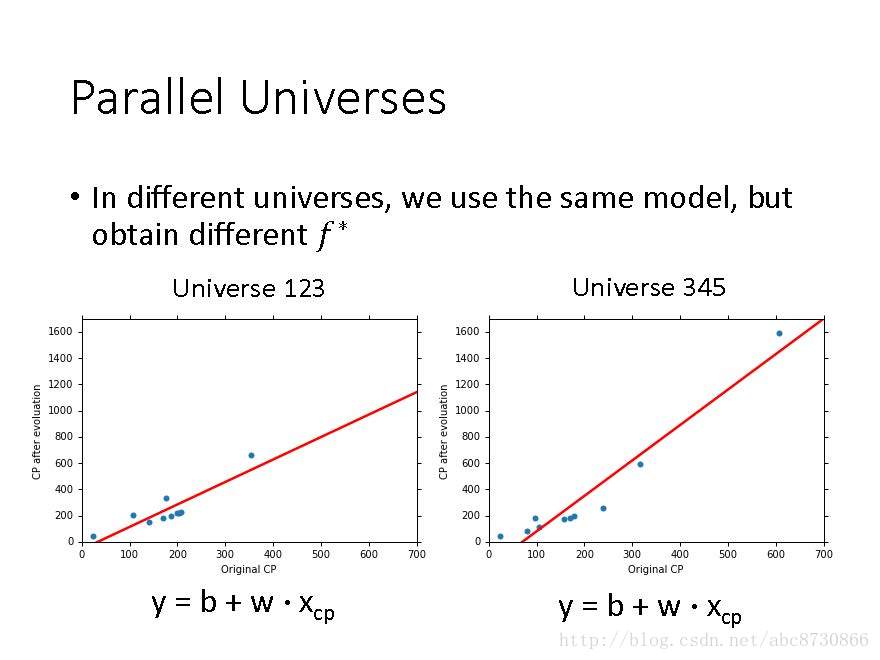
Parallel Universes
- 搜集多个训练集

- 在所有训练集上,用相同的模型,得到不同的
f∗
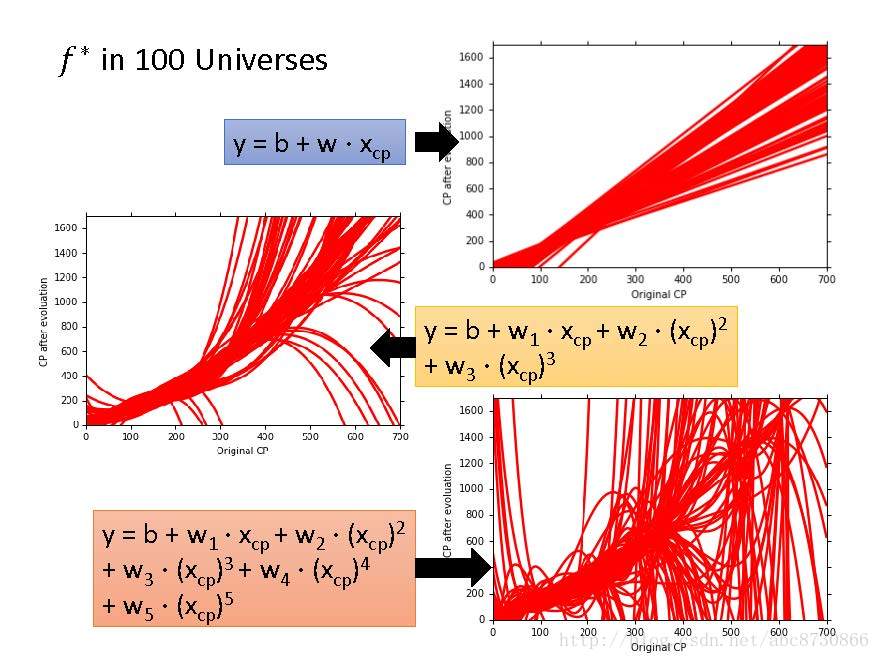
三种模型,每种模型在一百个数据集上得到的
f∗ 的情况
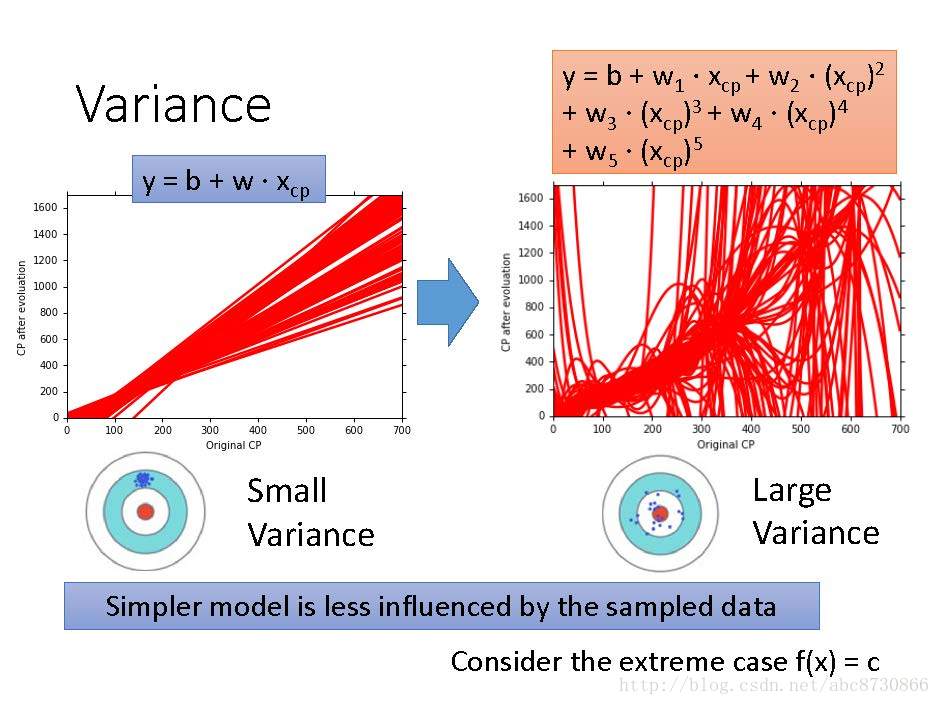
Variance
- 较简单的模型在受不同样本的影响较小,有更小的方差。(聚集在靶上瞄准的位置)
- 较复杂模型有较大的方差。(分布在靶心周围,分散的很开)
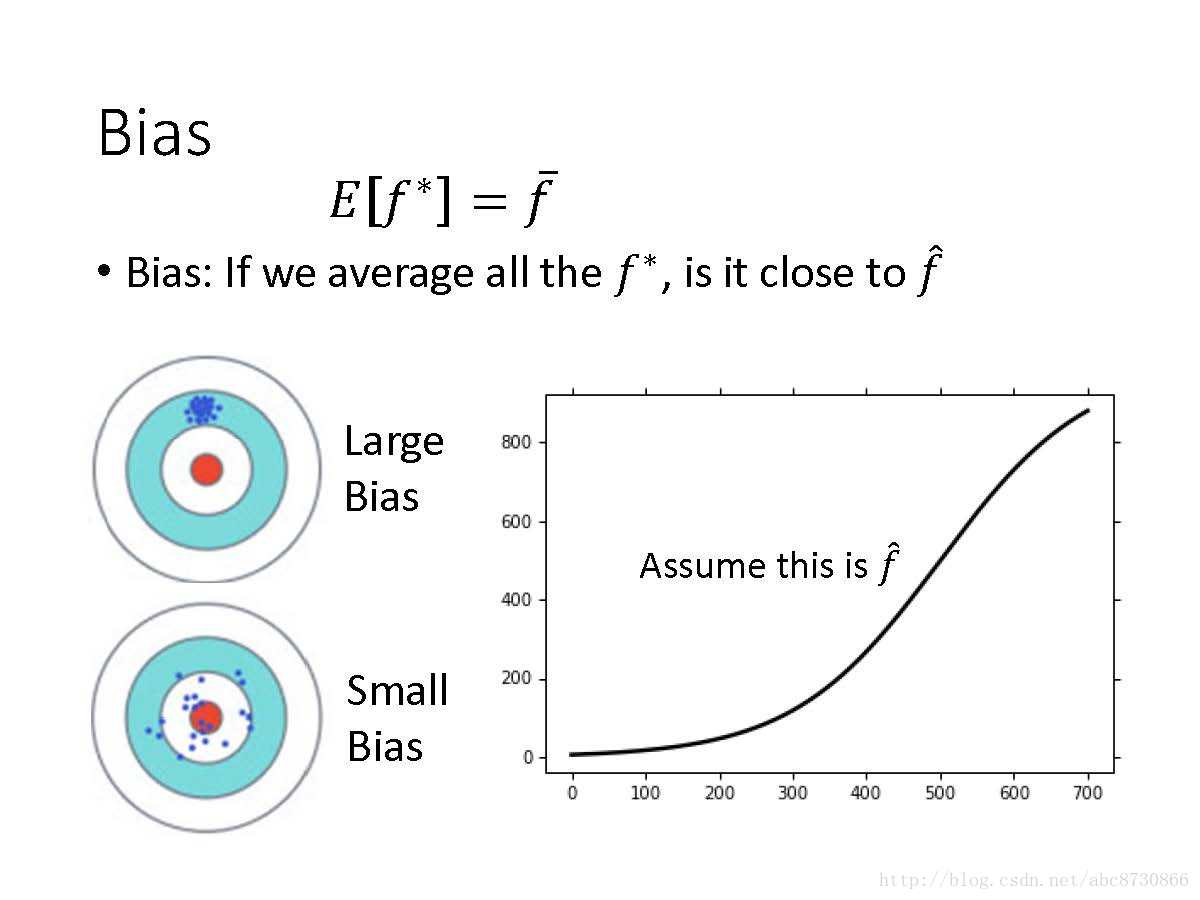
Bias
- 用
f∗ 的期望去衡量Bias,用f¯ 与f^ 的近似程度来衡量偏差 - 大的偏差(见图):瞄的就不准,偏靶心一段距离。
- 小的偏差(见图):瞄的准,围绕靶心。
- 黑色曲线:假定的
f^ ; - 红色曲线:5000个不同数据集下的
f∗ ; - 蓝色曲线:5000个
f∗ 的平均f¯ - 三种不同模型,1次、3次、5次。
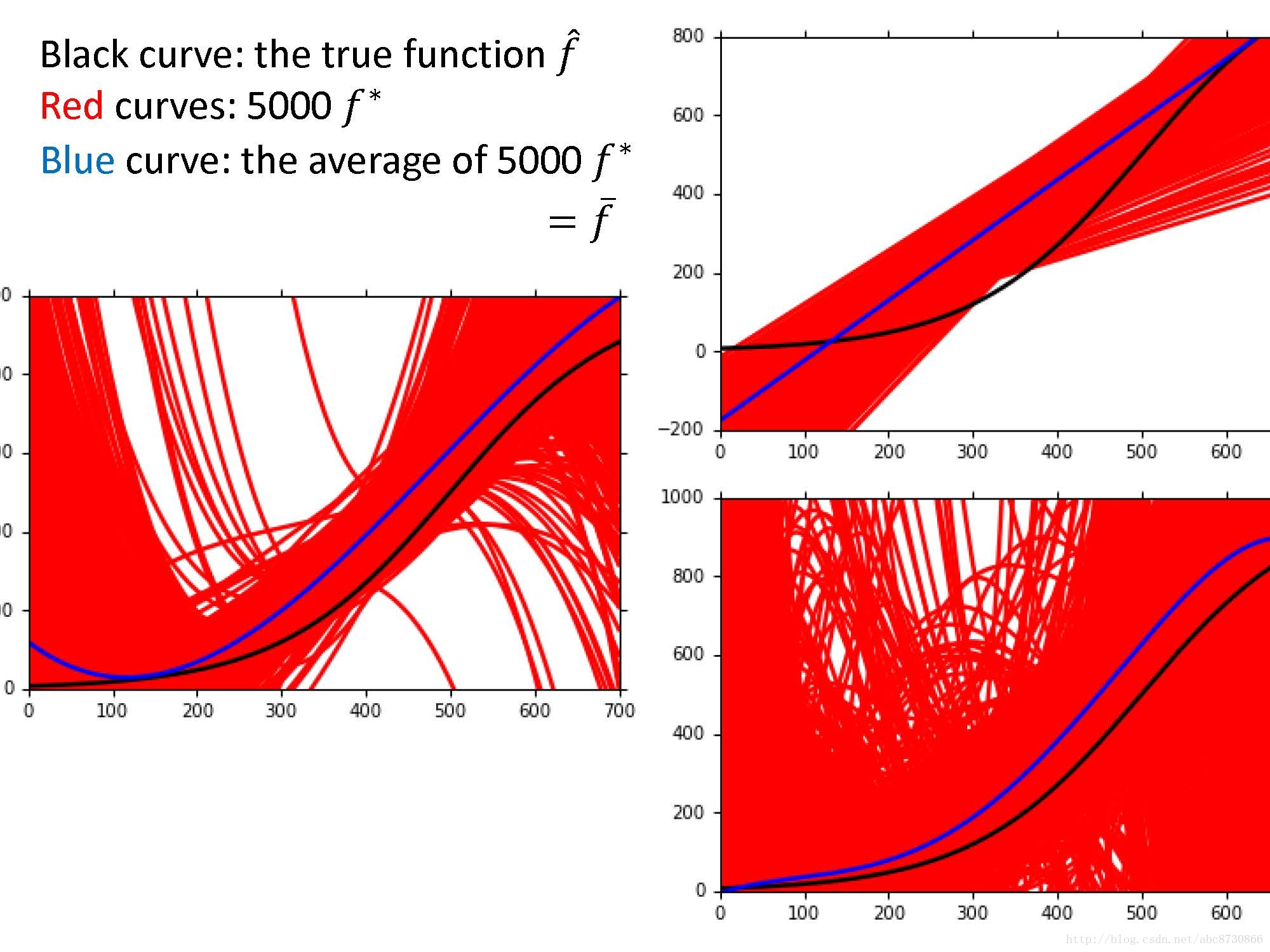
可以看出:
- 简单模型,大的偏差。(上图:
f¯ 与f^ 近似度小;下图:偏离靶心。) - 复杂模型,小的偏差。(上图:
f¯ 与f^ 很近似;下图:围绕靶心。)
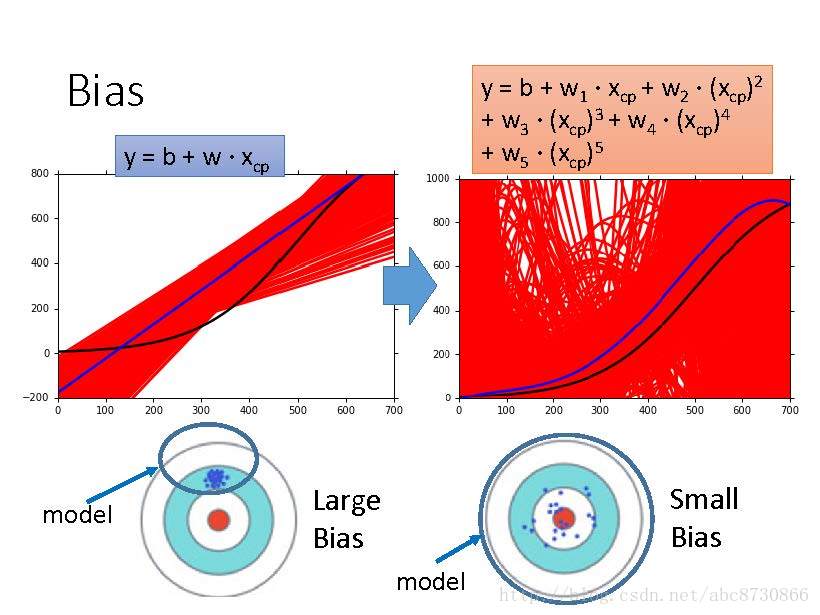
Bias vs Variance
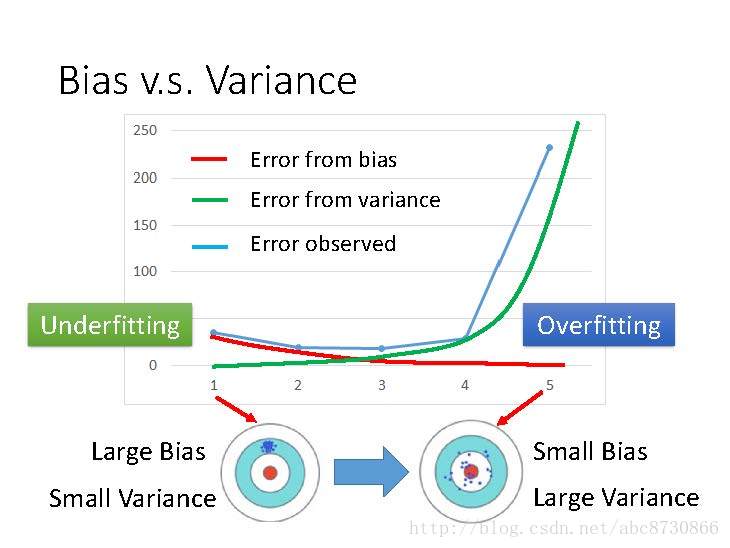
- 随着模型变复杂,Bias导致的error下降;
- 随着模型变复杂,Variance导致的error上升;
- 随着模型变复杂,error由下降到上升。
- 模型较简单时,大的Bias,小的Variance,Underfitting!
- 模型过于复杂时,小的Bias,大的Variance,Overfitting!
What to do with large bias?
诊断:
- 如果模型甚至不能够拟合训练集,那有大的Bias,Underfitting!
- 如果模型能够拟合训练集,但是在测试集上有很大的error,那可能有大的Variance,Overfitting!
对于Bias,重新设计模型:
- 增加更多的特征作为输入;
- 一个更复杂的模型。

What to do with large variance?
- 更多的data(效果见图):非常有效,但不是都很实际,因为有可能没有条件搜集更多的data;
- 正则化(效果见图)

Model Selection
- 通常在Bias和Variance之间有一个权衡;
- 平衡两种误差,选择一个模型,使得总误差最小;
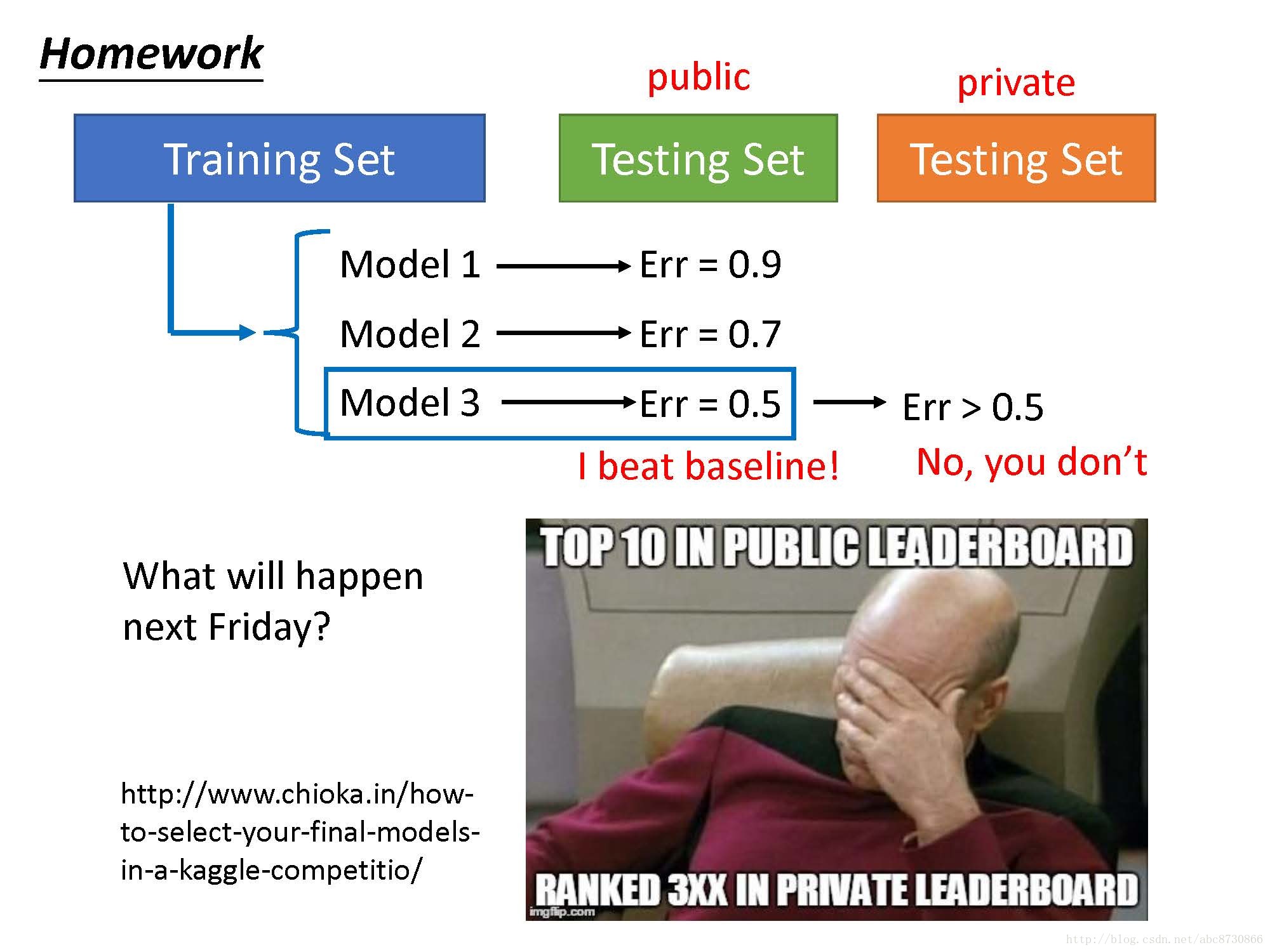
- 不该做得事:用三种模型在训练集上训练,得出三种
f∗ ,分别在自己的测试集上得出error,选择此时error最小的f∗ ,然后就把它放在真正的测试集上测试。(下图继续解释为何这样不好,以及该怎样做)
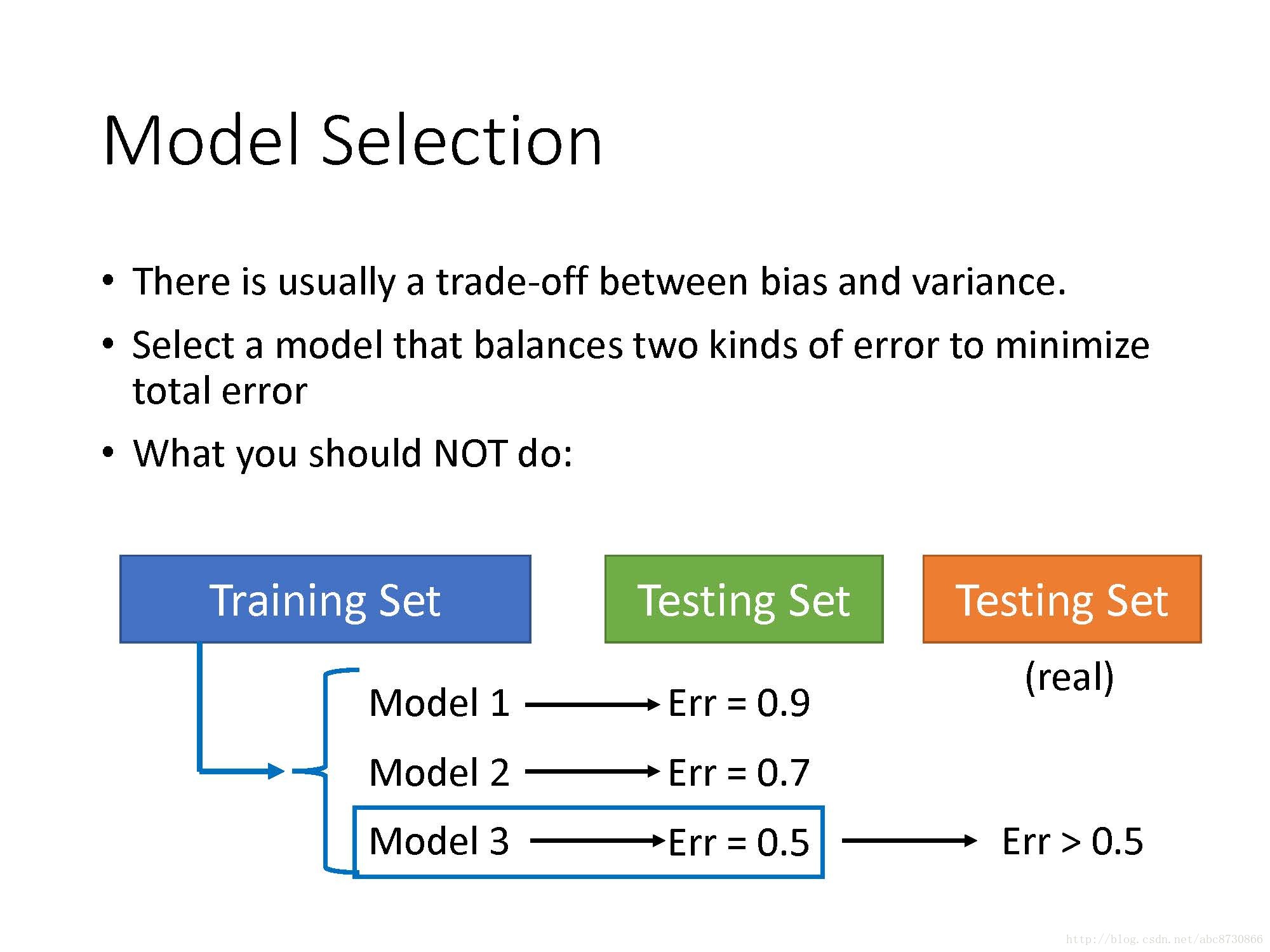
- 以Homework为例,如果用上面的做法,会导致你在真正的测试集上表现很差。(下面会继续介绍正确做法)
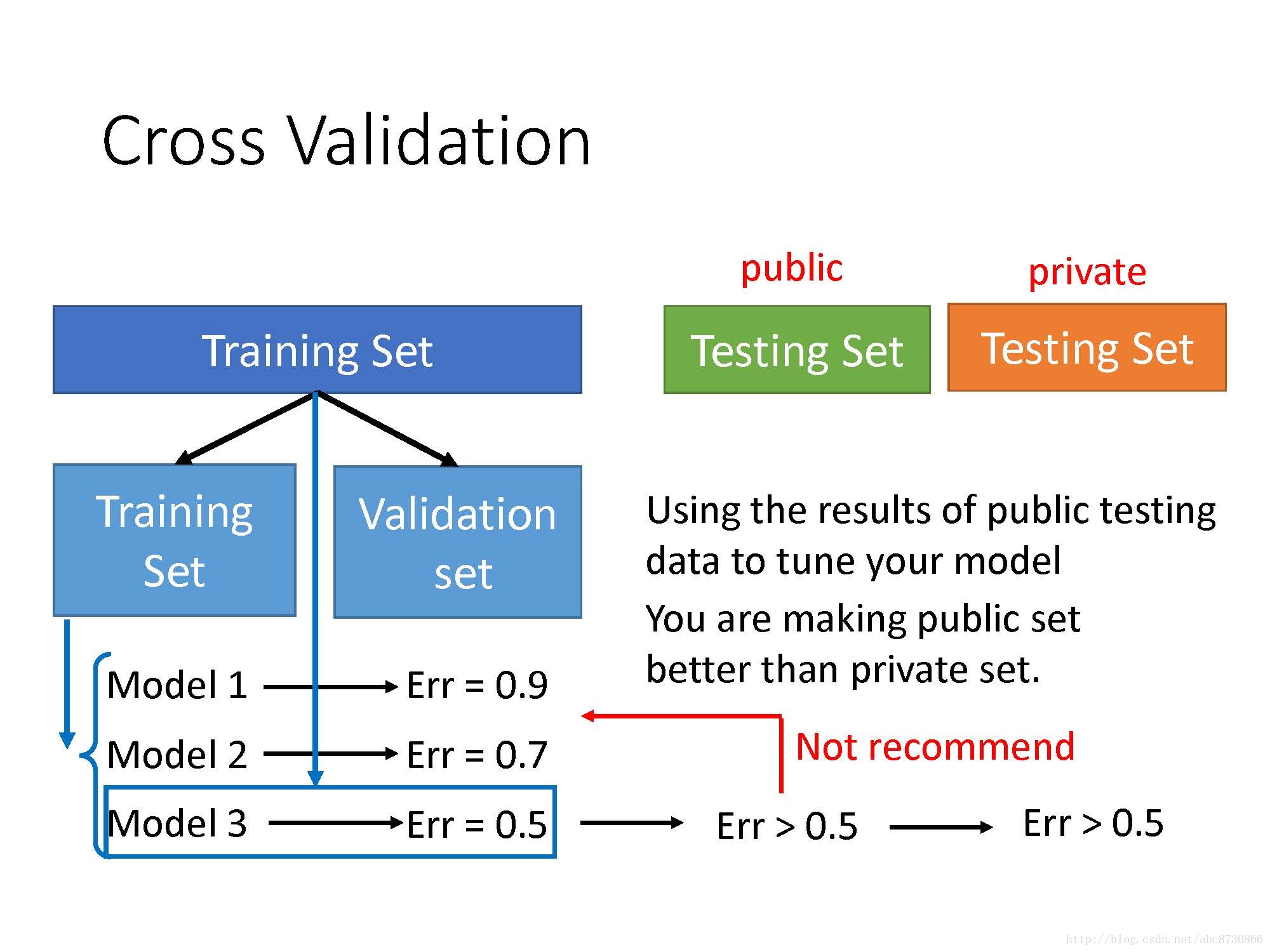
Cross Validation
- 将训练集分成两部分,一部分为训练集,另一部分为验证集;
- 用训练集分别训练三种模型,在验证集上得出error,选取error最小的模型;
- 用整个原始的训练集,去训练得出来的模型,在测试集上得出error;
- 在真正的测试集上得出error,这样的话效果好,才是真的好。
不建议做的事:
- 看到在测试集上(自己的)的效果不好,然后反过来去调整模型。这样做虽然对于人之常情或者发paper来说是不可避免的,但要强调的是:这样做了,也只是在你自己的测试集上的效果好,在真正的测试集上的效果不一定会变好。
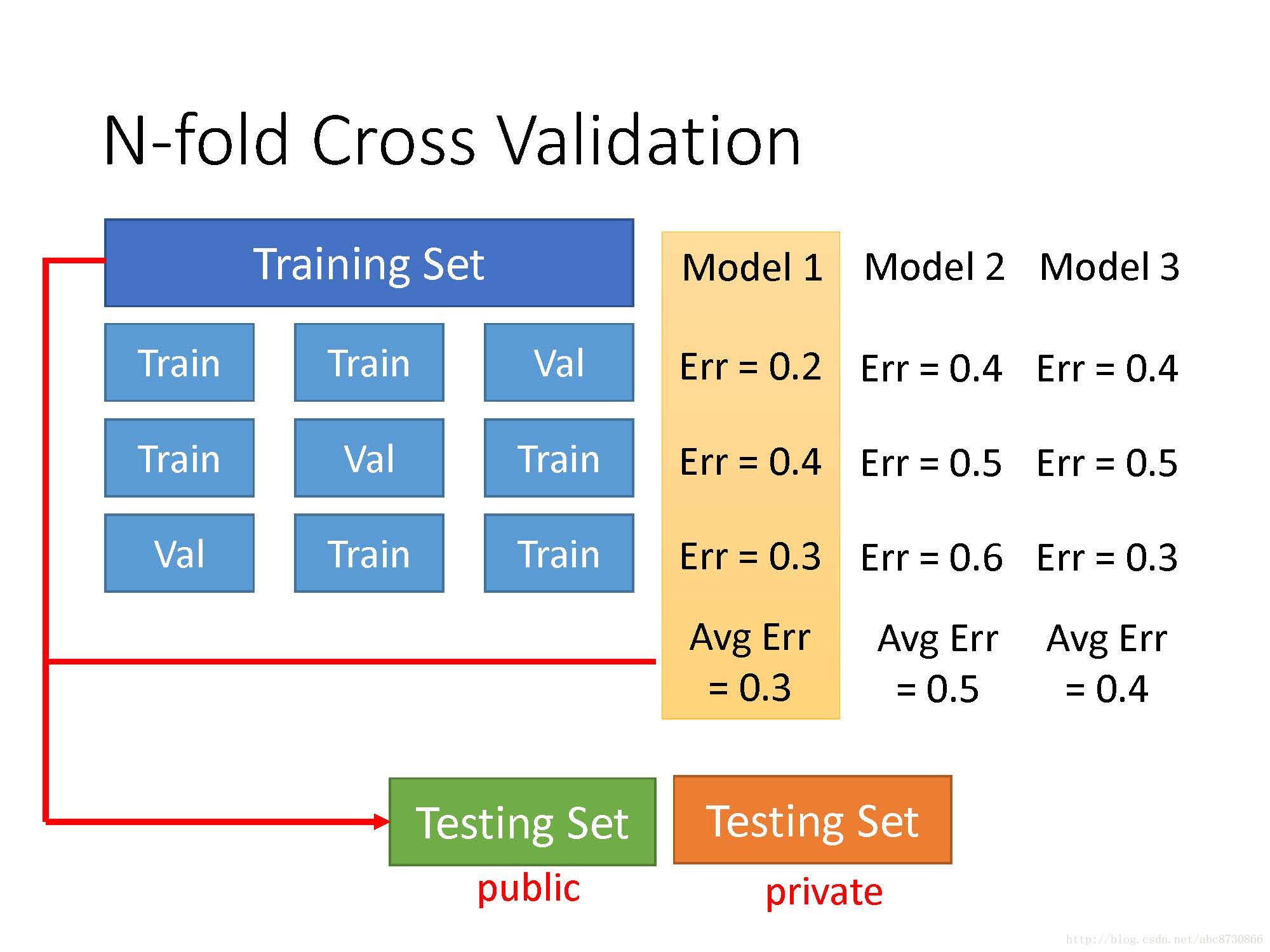
N-fold Cross Validation
- 将训练集分成三部分,取其中一份为验证集,有三种组合情况;
- 用三种模型在这三种情况下进行训练,然后在验证集上得出error,取三种情况下error的均值,均值error最小的情况作为选定的最好的模型;
- 将选出的模型,用原始的整个训练集训练,然后在测试集上得出error;
- 在真正的测试集上得出error。